
Connecting nearly a billion professionals is no small feat. It requires an infrastructure that puts the user experience above everything else. At LinkedIn, this principle created a massive engineering challenge: delivering a fast, consistent experience across various use cases, from the social feed to real-time messaging and enterprise tools.
In a deep-dive presentation at HAProxyConf, Sanjay Singh and Sri Ram Bathina from LinkedIn’s Traffic Infra team shared their journey to modernize the company’s edge layer. Facing rapid growth and changing technical needs, LinkedIn made the strategic decision to redesign its traffic stack around HAProxy.
The engineering principles driving this decision—simplicity, fault isolation, and raw performance—are just as relevant today as infrastructures get more complex.
Here is a look at why they moved away from their legacy solution, how they evaluated the competition, and the dramatic performance gains they achieved with HAProxy.
The challenge: a legacy stack hitting its limits
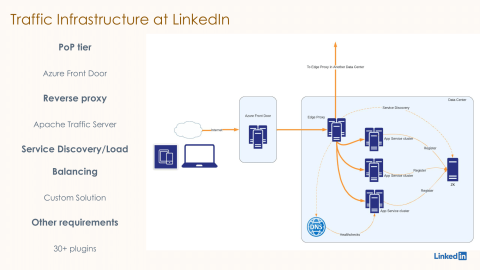
For years, LinkedIn’s traffic stack relied on Apache Traffic Server (ATS). This system acted as the bridge between user devices and LinkedIn’s services.
To make it work for their specific needs, the team had heavily modified ATS with over 30 custom plugins. These plugins handled everything from business logic to authentication and security.
While this architecture worked well for a while, three major drivers forced the team to re-evaluate their setup:
Organic growth: As the LinkedIn member base grew, so did queries per second (QPS). Scaling the fleet horizontally (adding more servers) was becoming inefficient and expensive.
Business diversification: New products, such as LinkedIn Learning and Sales Navigator, brought complex requirements, including strict consistency for payments and geo-specific routing.
Technological advancement: The team needed to support next-generation protocols, such as HTTP/2, HTTP/3, and gRPC, to keep up with the industry.
The hardware bottleneck
The legacy stack was becoming a bottleneck for growth. Scaling the ATS fleet wasn't simple; it had a cascading effect on downstream services, meaning bottlenecks shifted to other spots in the system.
The most telling challenge came during a hardware upgrade. The team upgraded to AMD 64-core machines, expecting a significant performance boost, but the upgrade in computing power only reduced their fleet size by about 12%.
This proved that simply throwing more hardware at the problem wasn't the answer—the software itself had to change.

The danger of complexity
Reliance on custom C/C++ plugins also created a fragile environment. Because these plugins functioned as shared libraries, they didn't offer good fault isolation. If a developer introduced a bug in one plugin, it could crash the entire proxy and take down the site. LinkedIn needed a solution that offered better reliability, higher performance, and native ways to handle their complex routing rules without writing so much custom code.
The evaluation: why HAProxy won

The LinkedIn team didn't just pick a new tool at random. They created a strict "wishlist" for their next proxy. It had to be:
Open source with a strong community.
Highly performant to handle LinkedIn's massive scale.
Feature-rich—offering native constructs to model routing so they could write less custom code.
Future-proof with support for modern protocols.
They evaluated several top competitors in the industry, including Zuul, Nginx, and Envoy, before HAProxy emerged as the clear winner by checking every box on the wishlist.
It offered the right balance of performance and community support. Crucially, its long-term support (LTS) release cycle fit LinkedIn's operational model perfectly, allowing them to focus on business logic rather than constant upgrades.
As Sri Ram Bathina noted, "We anticipate that it's going to drastically reduce our fleet size and get a lot of gains in performance, cost, and the amount of effort required to manage our fleet".
The decision was driven by four key advantages:
1. Unmatched performance
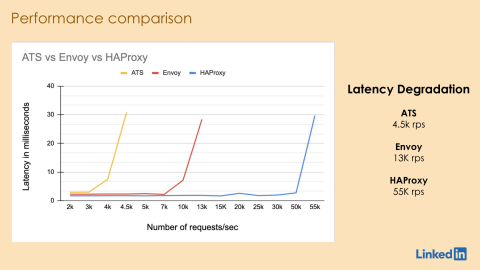
The LinkedIn team conducted benchmarking to measure end-to-end average latency using a 1KB payload and a simulated 1ms upstream delay. The goal was to see how much load (in requests per second) the proxy could take before latency exceeded 10 milliseconds.
The results were stark:
Legacy (ATS): Latency spiked above 10ms at just 4,500 RPS.
Envoy: Hit the limit at 13,000 RPS.
HAProxy: Maintained low latency up to 55,000 RPS.
HAProxy outperformed the competition by a huge margin. For LinkedIn, this kind of efficiency means they can handle more traffic with fewer servers, solving the scaling issues affecting their legacy stack.
2. Simplifying configuration
One of the biggest pain points with the old stack was how complicated the rules were.
To route traffic for a specific frontend, the team had to create a new rule for every single path. This resulted in a staggering 16,000 routing rules. Managing that many rules is a nightmare for operations and invites human error.
HAProxy solved this with its native map files and pattern fetching. By fetching patterns from a file and applying them to a single rule, they projected a massive reduction in complexity. They could go from 16,000 rules down to just 250—essentially one rule per backend.
Sri Ram explained the impact simply: "This would make our operations very simple... I only have to change that one rule instead of changing it in multiple places".
3. Native extensibility and fault isolation
LinkedIn has some very specific routing needs. One example is "member sticky routing". To ensure a consistent experience (such as read-after-write consistency), the system tries to route a user to the same data center every time.
With HAProxy, the team prototyped this logic using a simple Lua script. They could fetch the data center information and route the request in just two lines of config.
Furthermore, HAProxy’s Stream Processing Offload Agent (SPOA) provided the fault isolation they desperately needed. They can now offload processing—like anti-abuse checks—to external agents. If those agents fail, the core proxy keeps running smoothly.
4. Future-proofing
Finally, the move to HAProxy solves the "catch-up" problem. The legacy stack struggled to support modern protocols, which threatened to slow down the development of next-gen applications at LinkedIn.
HAProxy provided immediate, out-of-the-box support for HTTP/2, gRPC, WebSockets, and more. This ensures LinkedIn’s infrastructure isn't just fixing today's problems, but is ready for the future of the web.
Conclusion
By moving to HAProxy, LinkedIn has not only replaced a component; it has fundamentally modernized its edge. They moved from a complex, plugin-heavy architecture that struggled to scale to a streamlined, high-performance stack that is easier to manage and ready for the next generation of web protocols.
While LinkedIn achieved this with the free open source version of HAProxy, enterprise customers can easily achieve this level of performance (and more) using HAProxy One, the world’s fastest application delivery and security platform.
HAProxy One combines the performance, reliability, and flexibility of our open source core (HAProxy) with the capabilities of a unified enterprise platform. Its next-generation security layers are powered by threat intelligence from HAProxy Edge, enhanced by machine learning, and optimized with real-world operational feedback.
The platform consists of a flexible data plane (HAProxy Enterprise), a scalable control plane (HAProxy Fusion), and a secure edge network (HAProxy Edge), which together enable multi-cloud load balancing as a service (LBaaS), web app and API protection, API/AI gateways, Kubernetes networking, application delivery network (ADN), and end-to-end observability.
As Sri Ram Bathina concluded in their talk, "We love HAProxy... It is going to help capture our routing requirements very easily and minimize the amount of code we need to write."




