
At KubeCon, we asked a simple question at our booth: "How much is your service mesh costing you?"
The answers were eye-opening. Engineers shared stories of 40% resource overhead, multi-second latency spikes during peak traffic, and infrastructure bills that had nearly doubled since mesh adoption. One architect told us they were spending more time managing their mesh than building features.
But beyond costs, a second theme emerged in nearly every conversation: the complexity of federating services across fractured environments. As teams expand beyond a single cluster, they are struggling to connect workloads across services and clouds.
These conversations made it clear that teams are hungry for a better path forward. That’s why we presented two sessions at KubeCon: a keynote overview and a technical demonstration, introducing our vision for solving both cost and connectivity challenges — Universal Mesh. The response confirmed what we have long known: the service mesh dream hasn't matched the reality for many organizations.
This post recaps our KubeCon sessions, explores the challenges Universal Mesh solves, and explains why this approach resonated so strongly with the technical community.
Watch our webinar Beyond fragmented networking: achieving end-to-end security and observability with Universal Mesh and listen to our experts.
TL;DR
The problem: Current service mesh architectures create significant resource overhead (30-50% infrastructure cost increase) and struggle to federate Kubernetes workloads across clusters and clouds, as well as non-K8s resources.
The solution: Universal Mesh shifts focus from per-service proxies to strategic gateways at network boundaries, acting as a unified federation layer.
The results: Mesh benefits (mTLS, observability, traffic control) without the per-service overhead, plus seamless connectivity across clusters and clouds.
See it live: PayPal runs this architecture at massive scale (they call it "Meridian").
The service mesh reality check: what we heard at KubeCon

The modern enterprise didn't happen by design; it evolved over time. Organizations now manage a fractured digital landscape of multiple clouds, on-premises data centers, Kubernetes clusters, and crucial legacy applications that aren't going anywhere.
Traditional service mesh architectures operate well within Kubernetes but struggle to integrate these diverse environments. At our booth, two problems came up in nearly every conversation.
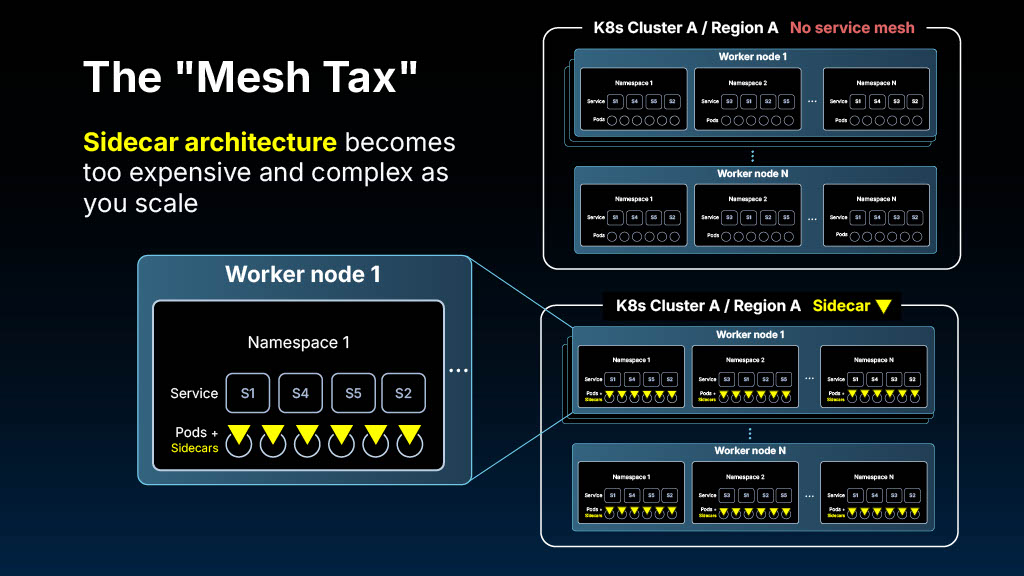
Problem 1: the "mesh tax" is real
The mesh tax refers to the resource overhead and performance impact of current service mesh approaches. Engineers shared specific pain points:
Sidecar model: Deploying a proxy alongside every application pod is expensive. Each sidecar typically consumes 0.5-1 CPU cores and 512MB-1GB of RAM. Every request traverses the sidecar proxy twice (outbound and inbound), adding 2-10ms of latency per hop. One team told us they had deployed over 800 sidecars across their clusters, consuming more resources than their actual applications.
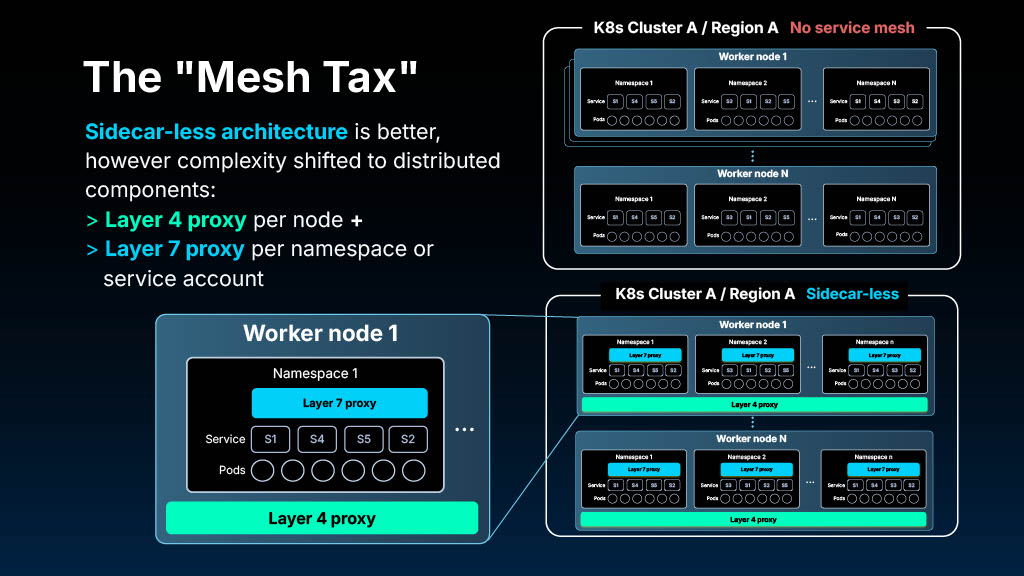
Sidecar-less model: While this improves resource usage, it often shifts complexity to distributed components, like a Layer 4 proxy per node and Layer 7 proxies per namespace. Organizations reported that troubleshooting became harder, and upgrades still required careful orchestration across dozens of components.
The bottom line: teams reported 30-50% infrastructure overhead from mesh components alone, along with performance impacts that forced them to over-provision their clusters.
Problem 2: the multi-cloud federation challenge
The integration wall has become an operational obstacle for platform engineers tasked with multi-cloud federation. Teams are finding it difficult to:
Send traffic outbound: Enabling services inside the mesh to securely call external resources (like AWS Lambda, RDS databases, or legacy APIs on VMs) requires custom workarounds.
Receive traffic inbound: Allowing non-K8s resources, such as virtual machines or bare-metal servers, to securely call services inside the mesh often means maintaining separate API gateways, VPN tunnels, and certificate infrastructure.
For example, one engineer described spending weeks building a solution for a simple use case: letting a Lambda function authenticate to a Kubernetes service across AWS and Azure. The final setup involved custom API gateways, VPN configuration, and complex certificate management.
This is the friction of federating complex infrastructure. Existing solutions lack unified observability and security policies across these boundaries, creating blind spots and compliance headaches.
A paradigm shift: focus on the boundary, not the service
 The industry has been hyper-focused on managing connectivity at the service level, but we believe the real challenge lies at the network boundary.
The industry has been hyper-focused on managing connectivity at the service level, but we believe the real challenge lies at the network boundary.
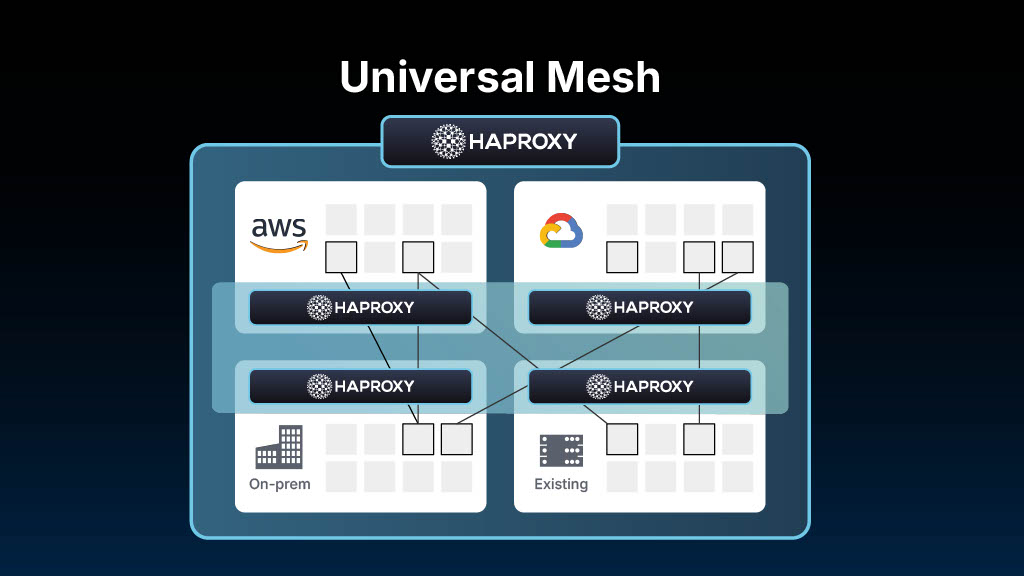
Instead of deploying 500 sidecar proxies for 500 pods, what if you deployed 3-5 strategic gateways at critical network boundaries — your cloud provider edges, your on-premises perimeter, your cluster boundaries? These gateways handle all cross-boundary traffic and act as the glue for your federation strategy, while services communicate directly within their trusted zones.
This is the core idea behind Universal Mesh. It's not an incremental improvement, but a fundamental shift that provides unified security, federated connectivity, and observability across every environment, from VMs and bare metal to Kubernetes and serverless functions.
KubeCon session highlights
We explored the Universal Mesh concept in depth during our two sessions.
Keynote: A vision for simplified connectivity
Frank Mancina, VP of Engineering & Operations at HAProxy Technologies, delivered a 5-minute keynote outlining the limitations of current models and introducing the Universal Mesh vision.
The core problem
Frank argued that the problem isn't the service — it's the boundary. Managing thousands of individual service proxies creates operational complexity and resource drain. The solution is to shift focus to strategic gateways at network boundaries.
The Universal Mesh approach
Universal Mesh converges Ingress, Mesh, and Proxies into a single, unified data plane. Rather than distributed components scattered across your infrastructure, you deploy high-performance gateways at network boundaries that handle cross-boundary traffic.
Quantifiable benefits
By removing sidecars and distributed components, organizations can:
Reduce resource overhead by 30-50%
Decrease per-request latency by 5-15ms
Simplify operations — upgrades happen at gateway boundaries, not across thousands of pods
Cut infrastructure costs while improving performance
Built for real-world complexity
The architecture is designed from the ground up for multi-cluster and hybrid-cloud environments. Federation isn't bolted on — it's fundamental to how Universal Mesh works.






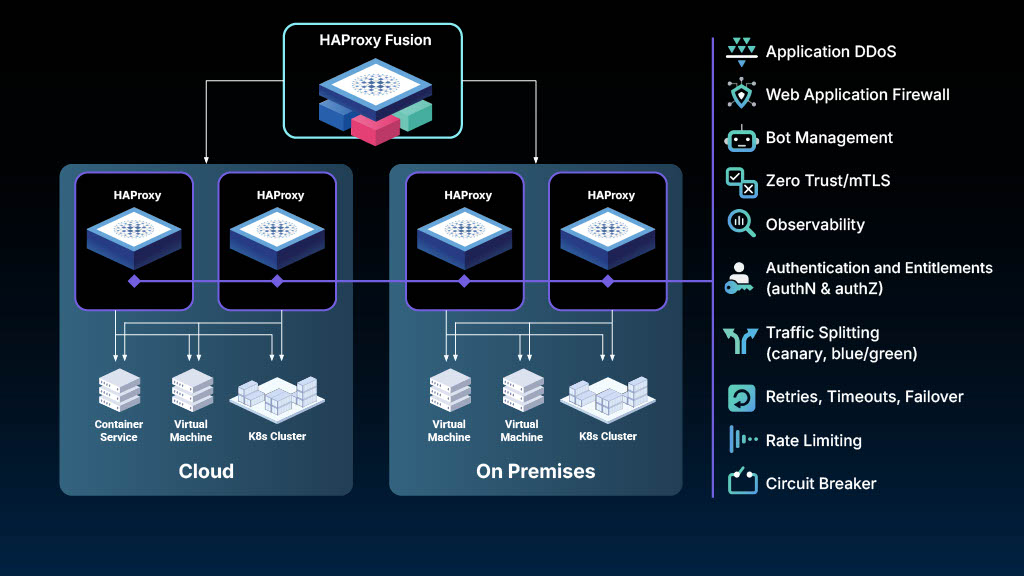




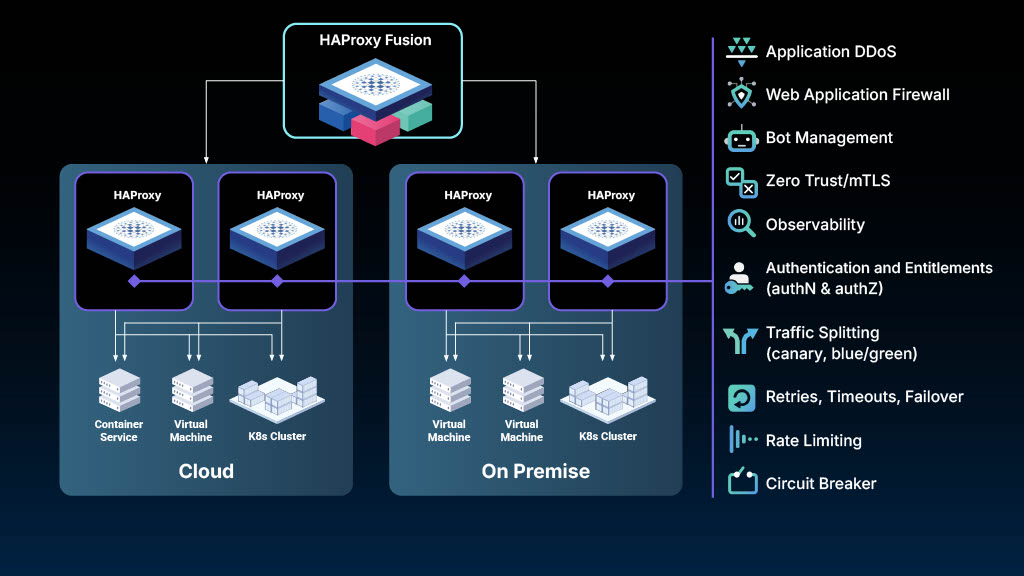
Demo theater: Universal Mesh in action
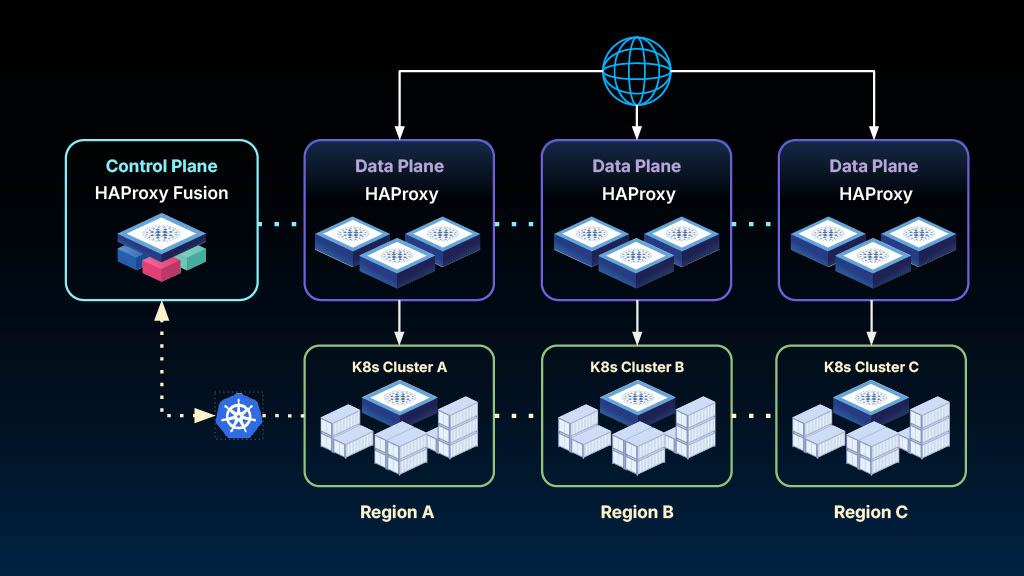
Jakub Suchy, Director of Solutions Engineering, led a demo theater session that demonstrated how Universal Mesh works in practice, utilizing HAProxy Fusion (the control plane) and HAProxy Enterprise (the data plane), which is built on HAProxy’s reliable and high-performance open source core.
Connect everything
Jakub demonstrated how Universal Mesh provides a single pattern for connecting both greenfield (Kubernetes) and brownfield (VMs, legacy) applications across different cloud providers and on-premises locations.
The highlight: a Lambda function authenticating to a Kubernetes service across AWS and Azure — something that typically requires custom API gateways, VPN tunnels, and complex certificate management. With Universal Mesh, it took three configuration lines and worked immediately.
Operational simplicity
The demo showcased the ease of adding new services and managing traffic routing. Jakub demonstrated automatic failover to a backup region when a primary cluster became unavailable — no manual intervention, no complicated runbooks, just policy-based routing at the gateway.
Centralized control
Critical functions, such as mTLS (Zero Trust), web application firewall (WAF), authentication, rate limiting, and advanced traffic splitting, are applied consistently at the gateways across the entire mesh. One policy, one place, enforced everywhere.





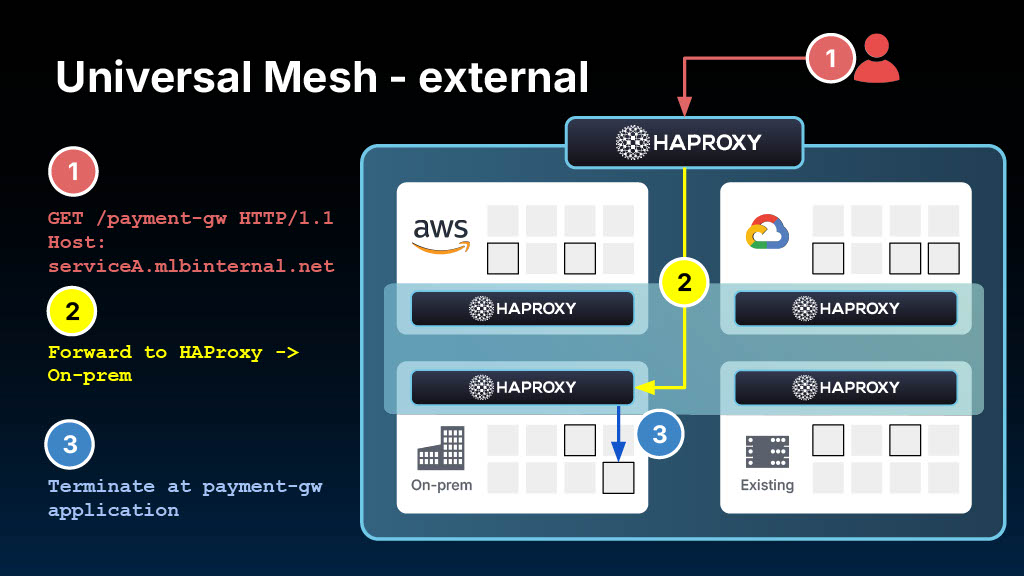
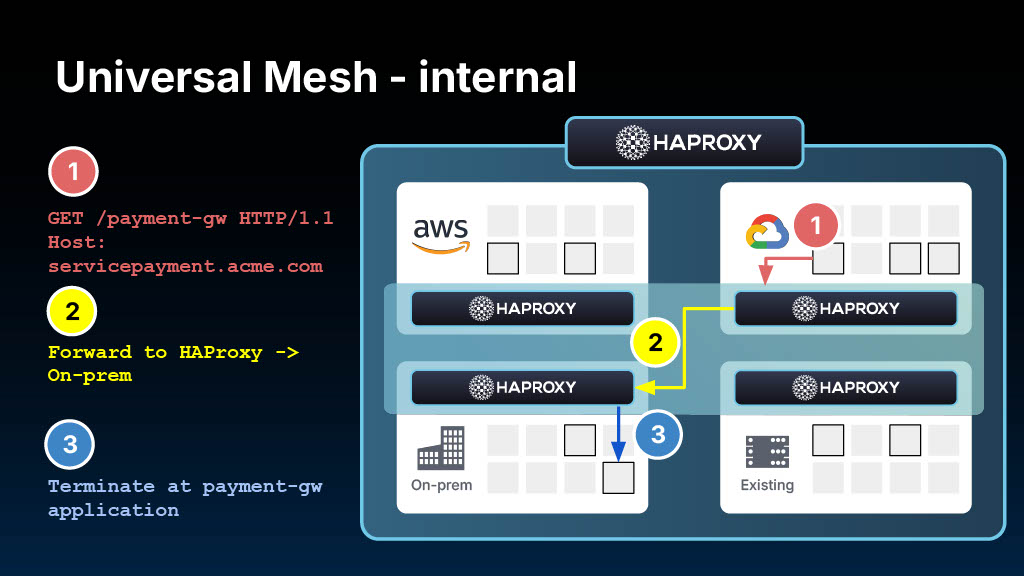




How it works (the 30-second version)
Universal Mesh deploys HAProxy gateways at strategic network boundaries. These gateways handle all cross-boundary traffic, whether that's between clusters, between Kubernetes and VMs, or between cloud providers.
Services within a trusted zone communicate directly without proxies. When they need to cross a boundary, the gateway provides security (mTLS), observability (e.g., metrics and tracing), and traffic control (routing, failover, rate limiting).
The result: you get mesh benefits without per-service overhead.
Why Universal Mesh resonates
Universal Mesh addresses the real-world pain points we heard at KubeCon:
Performance first: It eliminates the latency and resource overhead of sidecars by leveraging the world's fastest software load balancer at strategic points. No more 2x proxy hops, no more gigabytes of RAM consumed by mesh infrastructure.
True flexibility: It allows for mixed topologies — running gateways external to Kubernetes for traditional infrastructure or within clusters for cloud-native workloads. This bridges the gap between legacy systems and modern applications without forcing a rip-and-replace migration.
Simplified multi-cluster: The architecture is designed with federation and multi-environment spanning in mind, without architectural compromises. Organizations running clusters across AWS, Azure, GCP, and on-premises data centers manage them all through a unified control plane.
By shifting focus from the service to the boundary, Universal Mesh offers the benefits of a service mesh with a fraction of the cost and complexity.
Real-world validation: PayPal's "Meridian"
This isn't just theory. PayPal runs this architecture at massive scale across hybrid cloud environments. They call their implementation "Meridian," and it handles billions of transactions monthly.
Their HAProxyConf 2025 session details how they eliminated the “mesh tax” while improving reliability and simplifying operations. They describe the specific challenges they faced with traditional mesh approaches and how the boundary-focused architecture solved them.
It's a powerful real-world example of Universal Mesh succeeding at enterprise scale.
Who should care about Universal Mesh?
Universal Mesh is particularly relevant if you:
Run multi-cluster Kubernetes deployments across cloud providers or regions/availability zones
Struggle with service mesh resource overhead or performance issues
Need to connect Kubernetes workloads with legacy systems, VMs, or serverless functions
Manage hybrid cloud environments spanning on-premises and multiple public clouds
Want mesh benefits (mTLS, observability, traffic control) without the operational complexity
What's next?
The KubeCon response confirmed what we have long known: organizations need a better way to manage modern connectivity challenges. We're committed to helping you adopt this architecture.
We will be releasing a detailed implementation guide in early 2026. In the meantime, contact our solutions team now to discuss your specific infrastructure and discover the measurable performance and cost benefits of adopting the Universal Mesh architecture.
Thank you to everyone who stopped by our booth and attended our sessions at KubeCon. The conversations were invaluable, and we're excited to help you eliminate the mesh tax.
Subscribe to our blog. Get the latest release updates, tutorials, and deep-dives from HAProxy experts.



