
Have you been considering an infrastructure migration, but worried about configuration or strategic continuity? In this compelling HAProxyConf presentation, Dartmouth College demonstrates how they successfully migrated their load balancer as a service (LBaaS) platform from VMware NSX-ALB to HAProxy Enterprise with HAProxy Fusion Control Plane—without disrupting their users or changing internal workflows. Founded in 1769 and steeped in tradition, Dartmouth proves that even the most established institutions can embrace modern infrastructure innovation.
Infrastructure Engineers Curt Barthel and Kevin Doerr walk through their remarkable journey of migrating 1,100+ existing structured load balancer configuration manifests while maintaining full automation and platform independence. Their motivation was clear: rising license costs without apparent value and declining vendor support following multiple acquisitions. The result? A seamless migration that preserved their existing YAML manifest format while gaining access to HAProxy's superior performance, support, and cost-effectiveness.
This presentation offers a masterclass in enterprise migration strategy, diving deep into the technical implementation details including Jinja2 templates, Ansible playbooks, and Jenkins automation. The speakers demonstrate how they leveraged HAProxy Fusion Control Plane's API-first architecture, implemented sophisticated GSLB and VRRP configurations, and created a modular automation framework that makes adding new features as simple as dropping a template file into their Git repository. With 50 users across multiple schools and departments generating about 10 commits per week, their solution proves that large-scale infrastructure migrations can be both seamless and strategic.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.






























Curt Barthel
Thank you very much, Dylan, and we thank you for giving us the opportunity to tell our story.

For today's agenda, we'll review a little bit of the evolution of load balancing at Dartmouth and then talk about how we adapted to embrace a new architecture using HAProxy One. And then we'll discuss a little bit about our automation of load balancer deployment, give a quick demonstration, and then talk about some of the successes, lessons learned, and critical success factors.

For those of you who don't know or aren't familiar with Dartmouth, the college was founded in 1769, in Hanover, New Hampshire. It's the smallest of the Ivy League schools, and it has a long storied history — and as a result, it's a place that's very much steeped in tradition.
But we have evolved, and the college built its reputation on providing an outstanding undergraduate liberal arts education. Now it's been evolving to include some professional schools and — as Dylan mentioned — research institutes.


So, load balancing at Dartmouth.
Our team—Kevin and I and our colleague Andrew Johnson, who's the project lead for the HAProxy migration—supports the load balancer platform and serves on other platform teams. Our job is to provide a reliable, innovative, and agile solution for load balancing or for any of our other platforms.
Our clients for the load balancing platform are about 50 users, including software engineers, software developers, or other IT specialists scattered either within our infrastructure group or across our enterprise and business services groups. They also reside in our Dartmouth Library system, Geisel School of Medicine, Thayer School of Engineering, and Tuck School of Business.
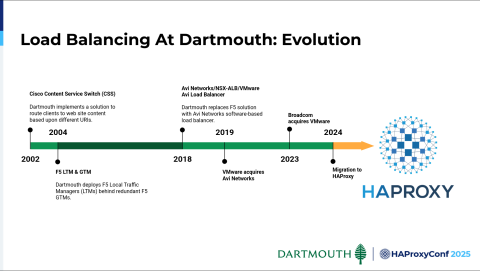
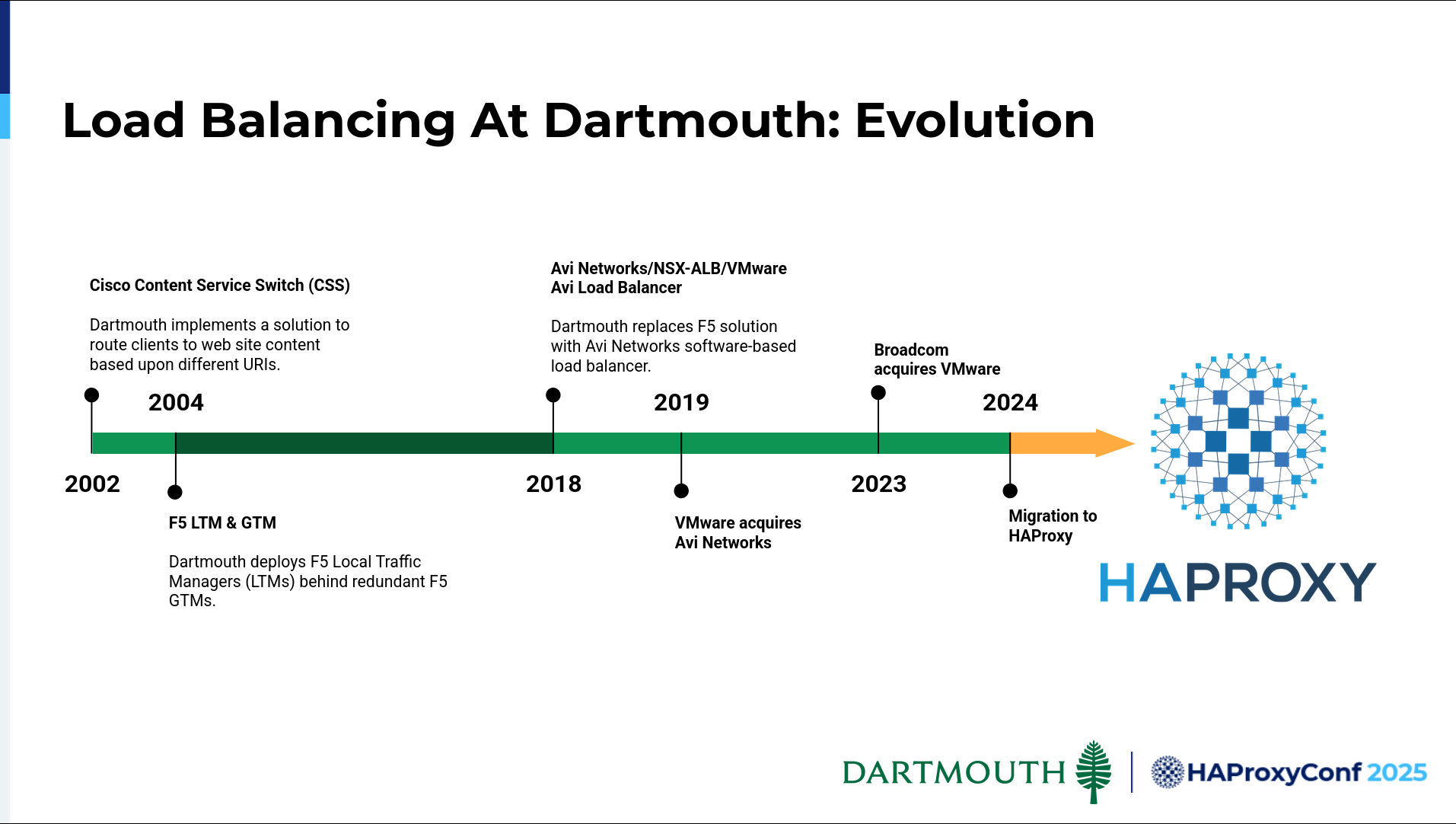
As I look at it here, our history regarding load balancing is very much the same timeline as HAProxy. Maybe within a year, we first implemented a solution, which I'm not sure was entirely load balancing, but it was content service switching in 2002. It wasn't until a couple of years later that we moved to a hardware-based platform: F5 LTM and GTM. We stayed on that platform for a pretty long time.
It wasn't until 2018 that we moved to more of a software load balancing solution. That's where we have been since. That Avi Networks solution has obviously seen some changes. In 2019, VMware acquired Avi Networks and, subsequently, Broadcom acquired VMware. In September of 2024, we found ourselves looking at the alternatives and pursuing a migration (from F5) to HAProxy.

Kevin Doerr
I'll talk a little bit about load balancing at Dartmouth. We implemented that in 2018. That allowed our clients to describe the load balancing service they needed using our specification, commit that to our configuration repo, and deploy that with Jenkins on demand so that they didn't need to wait on infrastructure. It also allowed us to limit their access to the GUI; so they could get into the control plane GUI for monitoring, but we didn’t want them in there causing configuration drift and such.
Some fun facts here: we have about 1,100 deployed load balancer manifests in our repo, and though this varies widely from business cycle to business cycle and during the academic year, we have about 10 commits per week in our repo.

So yeah, here we are at changing times. A couple of motivations pushed us to HAProxy: rising license costs without apparent value, and declining vendor support subsequent to acquisition after acquisition. Some of the goals we had were to maintain our current LBaaS implementation.
We wanted to use our existing structured data to make the migration seamless for our clients and, of course, reduce costs. Also, to maintain high availability. And a key here is to build a strong vendor partnership with our vendors to keep our innovation going.
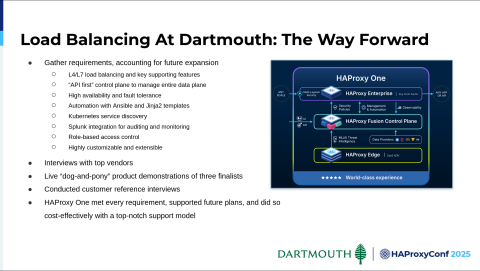
We started an evaluation project, and you can see our requirements here. One of the highlights is separating the control plane and data plane with an API-first model. Kubernetes service discovery is also important to us, so we interviewed top vendors.
Of course, HAProxy was on that list, and we did demonstrations, interviews, and such. HAProxy came out on top, particularly with the top-notch support model, which we would come to appreciate as we worked out our infrastructure implementation, which we'll talk about now.


Obviously, here are some of the key features we wanted to deploy. First comes HAProxy Fusion Control Plane. We're also going to use IPAM, GSLB, VRRP, and custom log formats.

Here's a representation of our synchronized data plane. These are some of the key services running on it, synchronized by HAProxy Fusion, and their corresponding config files are also managed by HAProxy Fusion.
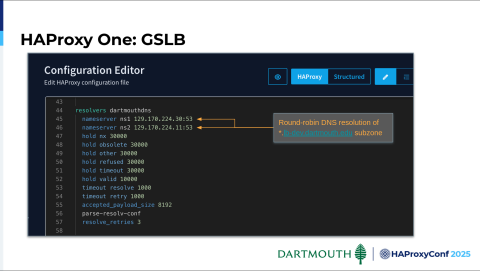
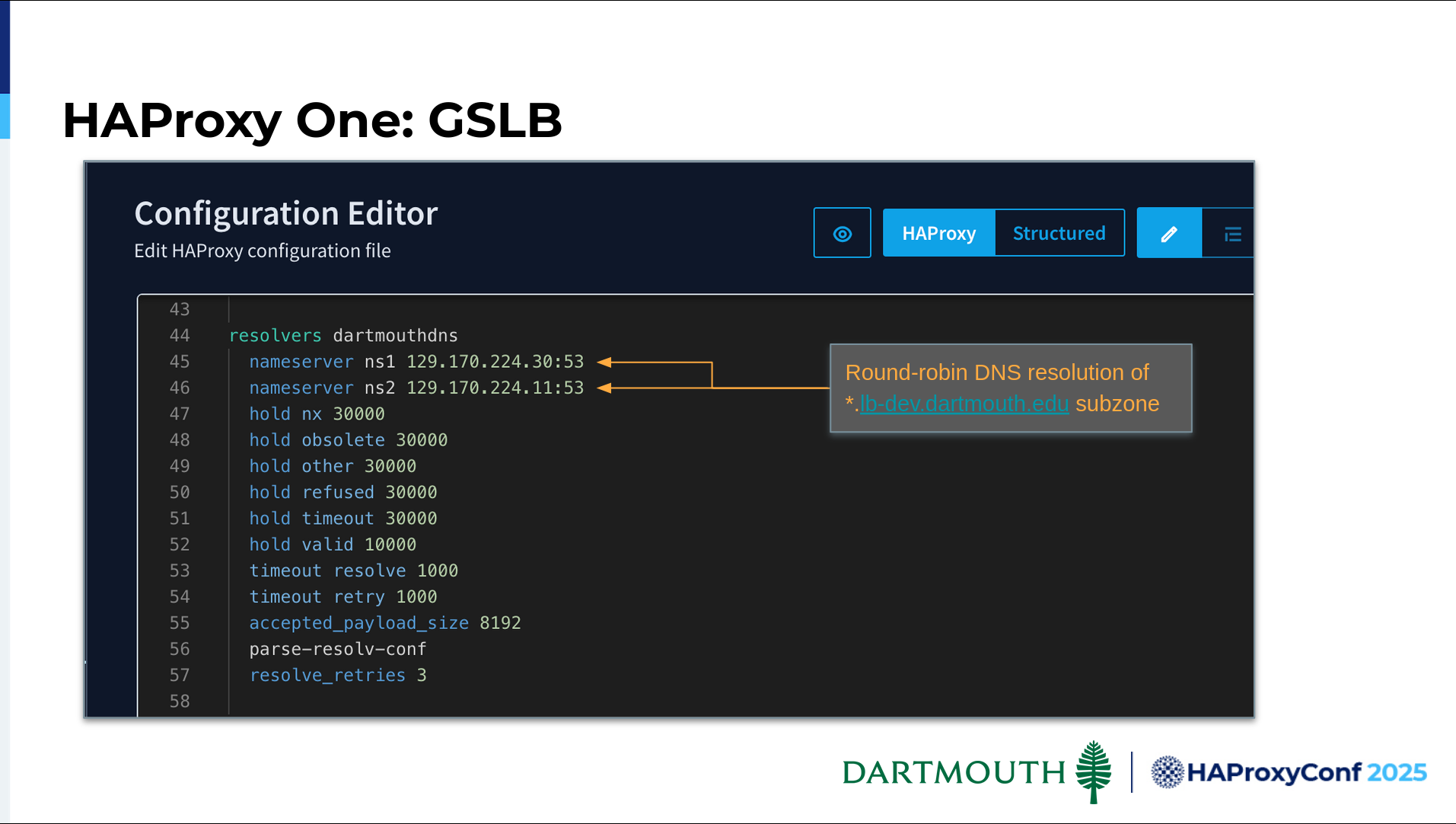
For GSLB, we have a delegated subdomain, and these are our two resolvers configured in our campus DNS for resolving load balancer services. You can see with the lb-dev domain name. Here's a little snippet of our GSLB config. You'll notice this is a map file that we are using until we have some native functionality in HAProxy Fusion to manage this. We put our config in the map file, which is then pushed out to the control plane.
We have a script on the control plane that tracks that file, updates it, and restarts GSLB when changes are pushed. Each frontend has two IP addresses associated with it. The answer list section includes those two records. Then, we specify round-robin for the answer list for each frontend. Here's an example of what a client sees when resolving.
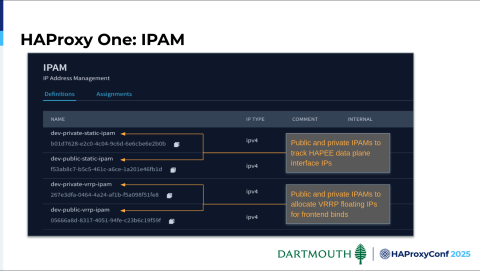
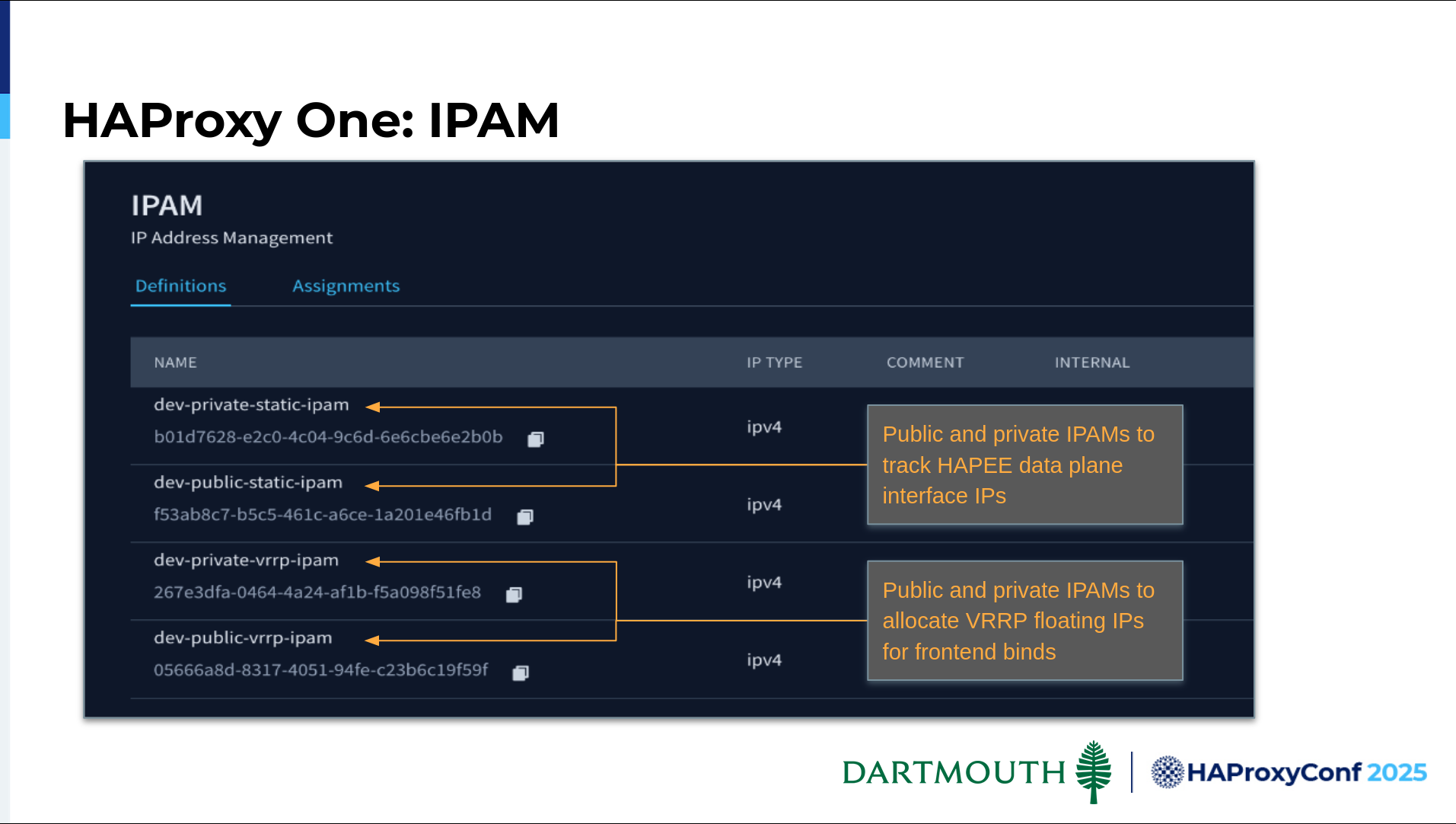
We have separated our data plane into two VLANs: one for public-facing services, and one for private. You can see we've further separated that. This is where we track the static IP addresses that are on the data plane interfaces. Plus, here's where we track the ones that are assigned to VRRP for the frontend binds.
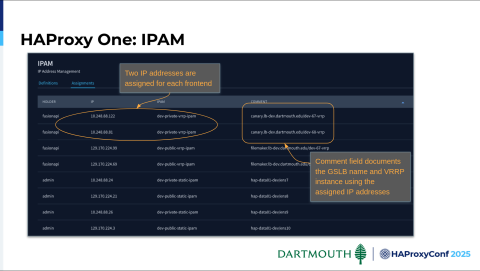
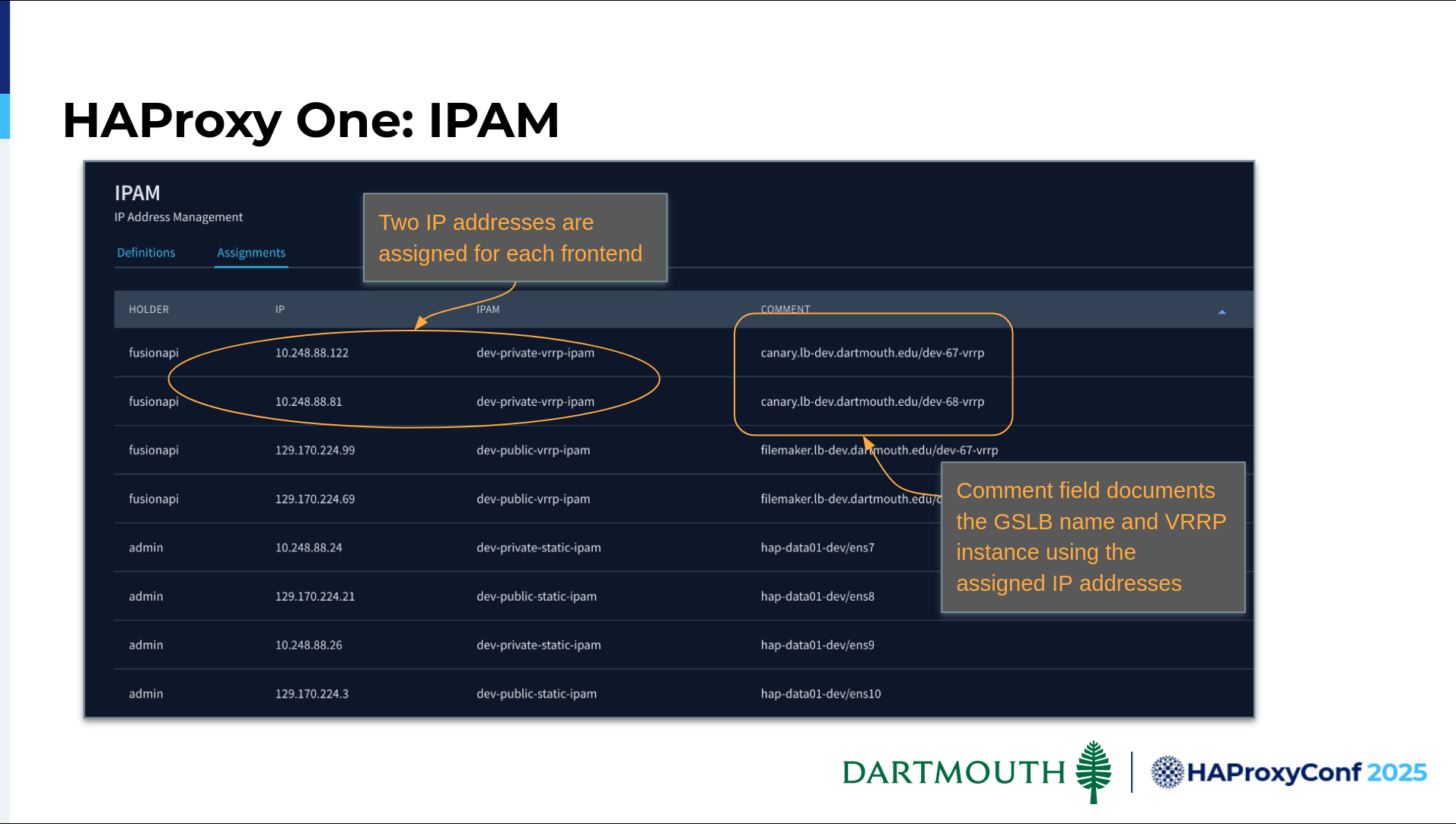
Here's an example of our IP assignments in IPAM. As I mentioned before, each frontend has two IP addresses. We've leveraged the very helpful comment field to document the GSLB that's using it and where it's configured in VRRP.

We have four VRRP instances: two for load-balanced traffic and two dedicated to GSLB because of its importance.

Here we've got our two active/active VRRPs. What we wanted was to load-balance the load-balanced traffic, so under normal circumstances, we have two data plane nodes round-robinning data plane traffic.
You can see our failover order allows us to lose node 1, shift to node 2, and so forth. We get down to one data plane node, at which point we're looking at a disaster recovery situation. Curt's going to take it and talk about automation.

Curt Barthel
Yeah, so in terms of implementing some automation, that's actually going to create all of that.

We're starting off with about 1,100 or a little more of these configuration manifests, even prior to migrating to HAProxy. Each one has a standard set of configuration parameters that are either required or optional. People have created these and copied each other's syntax, specified various settings, and then leveraged a number of optional parameters.
Here are a few of them, but not all of them. The syntax here is largely platform-agnostic. Some of the terminology was specified originally when we went to Avi and dates back to 2018.
This isn't our first migration, and with Avi we faced the challenge of trying and implementing (in automation) every option that a user would need. We had to put a bar at some point and cut off rarely-used functionality. Thus, one of the goals we had in this migration was to see if we could at least improve the amount of automation dealing with what we have currently as manual configuration. Then, we could turn that into a more robust manifest that a wider audience can use.

In our Git repo, we've got a YAML configuration manifest format that our users can use. This is their document that they can go consult, in addition to existing templates that they can go check out. And this contains a lot of settings that we've created or a combination of settings that we've created for common use cases.
We'll try to support those common use cases with a single parameter setting rather than requiring a user to set everything up, after which it gets a little bit more complicated and cumbersome for them to use through the automation. In cases where customization is necessary on their part, they can specify more comprehensive settings or configurations.

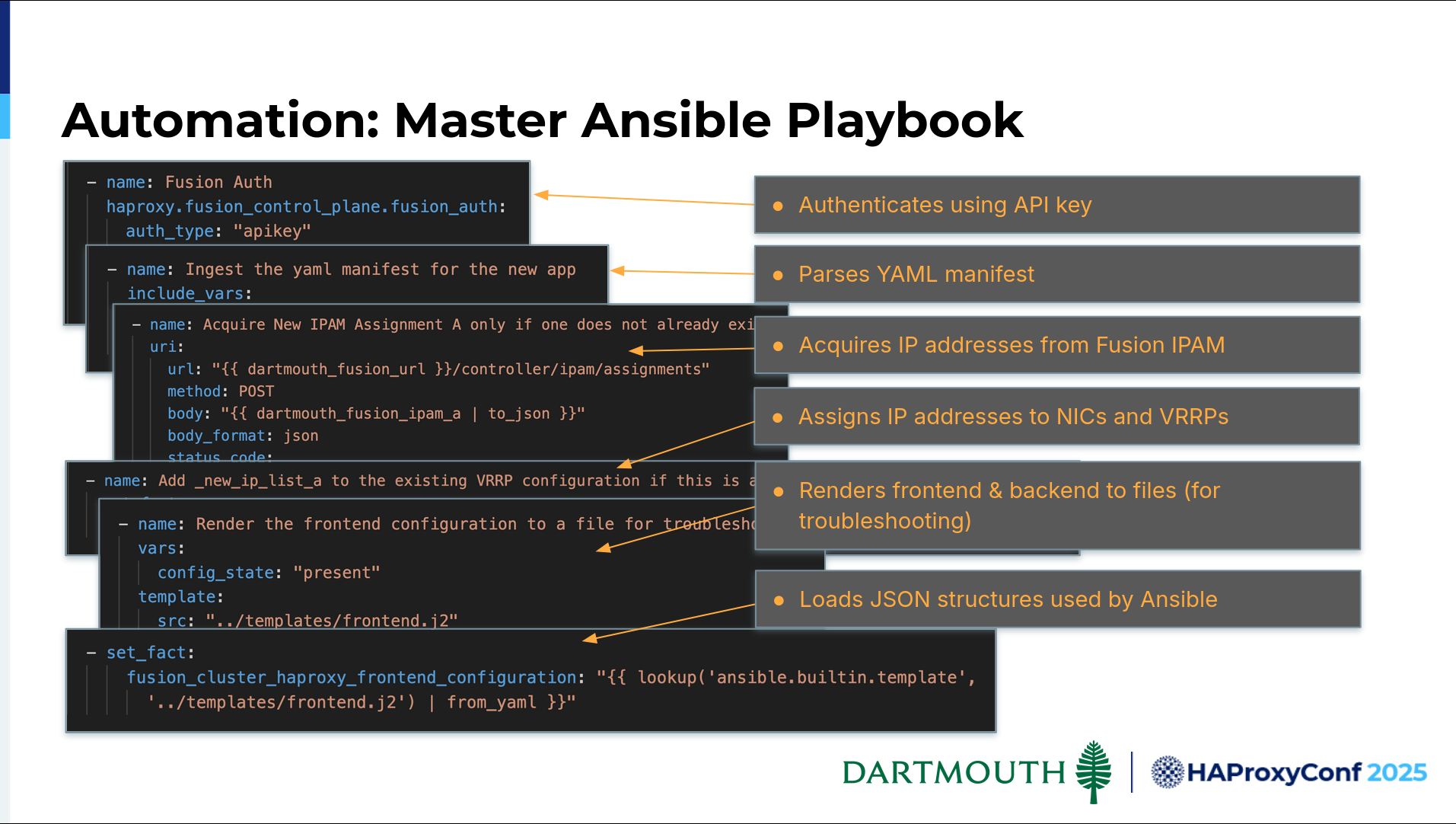
What ends up driving this for us is the same as it was with Avi. We have a master Ansible playbook that we're using. It also deals directly with HAProxy Fusion, which we love. This is going to sync the changes to the data plane and authenticates with an API key. It parses the manifest.
Next, it goes out and acquires the IP addresses — the bind IPs that Kevin was talking about. Then it goes through and it assigns those bind IPs. Actually, it determines which NIC on the host that IP address is going to be used on. Finally, it assigns those IPs to the VRRPs.
We found this useful. It renders frontend and backend configuration, which copies so we can track the configuration changes; because inevitably there are some times where we're like, "Wait a second, we thought it was this way, and now it seems to be behaving differently." We can track those changes.
But ultimately, the goal is to load all the JSON structures that we'll then be able to use Ansible for to load into HAProxy Fusion and have that configured and pushed out.

The master playbook also calls some storage playbooks. Some of these calls are optional depending on the configuration parameters that a user specifies. For example, if the user specifies an IP list, allowlist, or denylist, we'll call a storage playbook for that. It's the same for things like user agents. We've also got a scenario where we have a commonly shared frontend, which does a lot of backend switching.
So, that's very useful for us in public IP situations, where common configurations can share the same frontend, and then we use backend switching on that frontend to direct traffic. We also call a storage playbook to update the GSLB map file with the record and the answer list. Lastly, what we're doing is initiating transactions, storage transactions for map files, configuration transactions for front and backends, and then also VRRP transactions. You can see those.

So, we started off trying to adapt our Avi automation to work with HAProxy. We actually had a version of that which we got off the ground. But very quickly, as we started to try and implement some of those manual configurations in our automation, we realized that refactoring that automation was super cumbersome. As a result, we started looking at ways we could do things differently that would expedite our ability to introduce a new configuration parameter in our manifest.
We ultimately settled on organizing these frontend and backend Jinja2 templates into sections based on the standard stuff that you'd find in a frontend or backend. We've got the main section — their default. The default server section will contain monitors, SSL, and SNI information. The ACL section includes backend switching rules. All of these are organized this way in our frontend and backend, and then we leverage a couple of resource types and call a template.
This modularizes our code, so we promptly introduce a new parameter by simply dropping a Jinja2 template into a Git repo and exposing it in these frontend and backend Jinja2 templates. All of a sudden, our parameters are live.
And this was really useful as recently as last week, when people are doing testing in our non-prod environments that have been migrated already to HAProxy. Somebody said, "My frontend is not operating correctly, and I just don't understand why this setting is this way." We discovered it was a manually set parameter in Avi, and there was no automation for it. Thus, we said, "We can easily just create a new template here with a few lines of code, drop it into whatever relevant sections, or drop it into all the sections, and then the template is only invoked when it's relevant." You can kind of see the other sections there.

Ultimately, the frontend and backend Jinja2 templates in our environment call what I'll call “functionality templates”. We had a specific monitor in Avi called System HTTP, and it has all these settings. The user specified this in their YAML manifest. It was easier for us to figure out what those parameters are in Avi, adapt the Jinja2 template for that, drop it into the monitor's template here, expose it in the backend or elsewhere, and it immediately goes live.
That modular nature really has helped us implement new features. The other great thing is that we don't have to touch the actual Ansible code. Now that we've gotten all the configurations and the transactional stuff taken care of — and HAProxy Fusion takes care of all of that for us — the playbook just stays. We just use it. All we do is a little bit to enhance the functionality.

One critical factor in our solution is something that we stumbled upon. We got our Slack channel in early September, and I think on November 4th, I reached out to the HAProxy folks and said, "We're struggling to call APIs all over the place, and I feel like we might be reinventing the wheel. Is there something you have or have seen customers use that we could leverage to expedite our efforts?" Jakub replied back and said, "Well you know, maybe you should check out this thing, HAProxy Fusion Control Plane. It's this Ansible collection."
So we get the zip file, download it, and start looking at it. It does exactly what we want, sure enough. Plus, shoutout to Mark Boddington, who maintains this, wrote it, and uses it a lot. He's been super helpful with it, allowing us to customize it a little bit more to expose functionality that allows us to abstract the Fusion API calls one level from our Ansible playbook.
For example, we don't use WAF in Avi, so we're not going to use HAProxy Enterprise WAF at go-live in HAProxy. But we will in the near future. Eventually, we'll get around to needing some WAF parameters. We'll expose those. We'll make modifications to the Jinja2 templates. Then, we'll need to add an additional playbook that will take care of the WAF transactions. This collection really expedites that. Instead of making API calls and doing a lot of management on our own, we can just invoke these roles, and the functionality is immediately available to us. It's very valuable.

Ultimately, this abstracts the HAProxy Enterprise configuration for us. Our users are doing the same thing that they've been doing. They're specifying whatever parameters, or in some cases this manifest may have been sitting around for a year or so – no one's really touched it and no one wants to touch it because it's got to stay up.
We're abstracting that, and we're turning that into the frontend, the backend. We may be creating some map files. Here's an IP list map file. Here's a user agent map file. Ultimately, what we end up with is that good old frontend-backend configuration in HAProxy Fusion. That's exactly what we want.
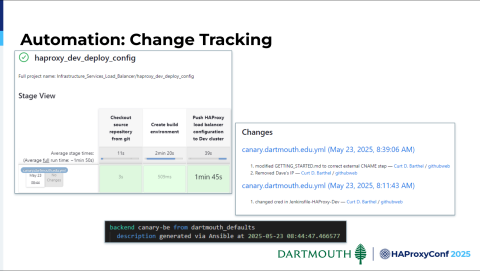
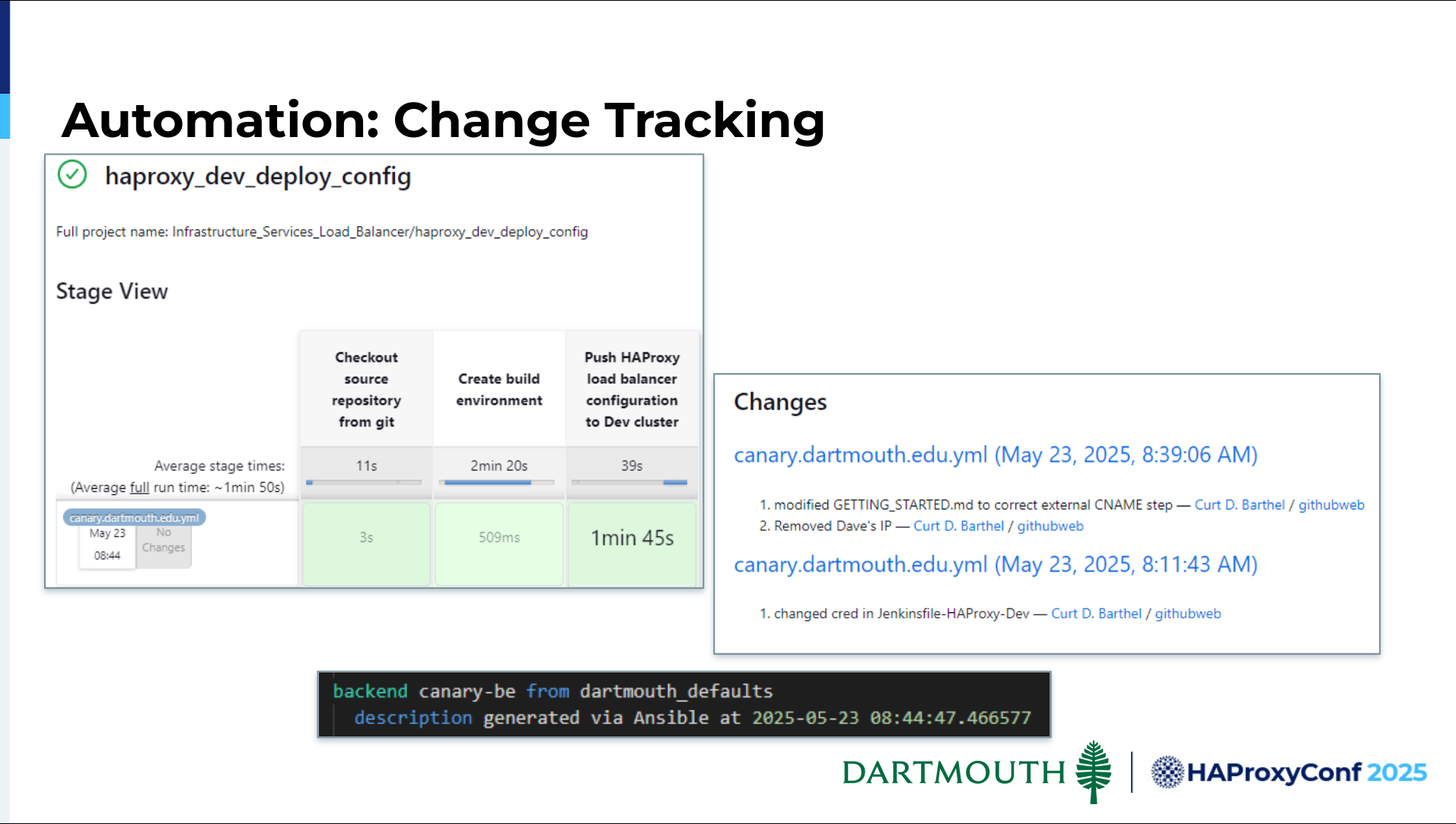
One of the things we're also doing is tracking changes in Jenkins, from which we're launching this playbook. Obviously, we can see changes in Git. But we are not allowing our users to have anything other than read access in HAProxy Fusion—with the exception of updating certs.
We leverage the description field to track when that frontend or backend was last touched. We'll eventually add the capability to see who last touched it. Teams of people are responsible for some of these manifests. They've never had the capability to say, "All right, when was the last config change for this and when did it happen?" Having the ability to track all that information is very valuable to us.

Next, we have a pretty brief demonstration of our load balancer in action. In this demonstration, we'll see how one of our users at Dartmouth might leverage our Load Balancer as a Service (LBaaS) automation to make a configuration change to a running load balancer.

In this hypothetical scenario, the user would already have been granted access to a Git repository environment called IS-LOAD-BALANCER-CONFIGURATION. The Git repository contains a YAML manifest for each load balancer that's been deployed in our load balancer environment. It also includes documentation that contains a list of all the allowable parameters that can be specified in the configuration manifest. We saw that earlier.
In this document, our users can see whether or not each parameter is required and which template (HTTP or TCP) supports its usage. Where appropriate, we've got comments that provide our users with additional guidance on parameter usage, and there's also a date-tracking field so they can see when features are exposed.
Some of the parameters accept one set of predetermined values, while others can take either a single value or be further customized using a more detailed specification. In this example, we have a monitor specification that will allow a user to specify a path or a URL, plus acceptable HTTP response codes and a successful response string. Our documentation contains usage examples for these specifications.
Let's take a look at the configuration parameters required to control a firewall setting in the load balancer. There are two parameters allowed in the configuration manifest. The firewall parameter can specify one or more IP addresses or a CIDR, while the firewall_mode parameter can allow traffic or deny traffic from IP addresses.
So here's an example manifest that's been deployed in our load balancer environment named canary.dartmouth.edu. We saw it earlier in the example. Our canary.dartmouth.edu manifest has been configured to bind on private frontend IP addresses, handles incoming HTTP traffic, and terminates SSL for two backend pool members listening on port 80. Those backend pool members are being monitored using the /healthcheck/ URI and are marked up if they return 200 or 300 response codes — and a successful /healthcheck/ response string of Healthcheck Working.
Farther down in the configuration, we can see the firewall parameters we reviewed earlier. Note that traffic can only reach the backend pool members from a single IP address. We can test that firewall setup by navigating our browser to canary.dartmouth.edu. Looking back at the configuration, we can explain the behavior observed in the web browser by noting that an outage action was specified to redirect traffic to outage.dartmouth.edu. The redirect occurred because the browser's IP address was not in the allowlist of the firewall setting in that configuration manifest.
Let's make a configuration change to the manifest to allow traffic from my browser's IP address. We'll commit that change to our repository, save the changes, and push them. Next, we'll launch Jenkins — just like our user would — and use the haproxy_dev_deploy_config pipeline. This is our dev version of it. We'll build with parameters and submit canary.dartmouth.edu.yaml.
That manifest will then be fed to the pipeline, ingested, and hopefully, our configuration will be deployed to HAProxy. It's sped up for time here. Now that the configuration has been applied, if we go back and check our web browser to see if the IP address is allowed, we can see that it's working.
As you can see from this simple demonstration, we've completely abstracted all of our load balancer implementation details from the process that our clients use for deployment. Some of our users don't yet understand what a frontend or a backend is — nor do they understand what ACLs or map files are — and arguably, should they? Their procedure for deploying a configuration to HAProxy has remained exactly the same as it was when deploying their manifests to Avi.

Kevin Doerr
So in conclusion, we can highlight some of our successes. The new automation fully supports the existing load balancer manifest, which means that our users don't have to change a thing. We expose multiple new features through automation. Some of them are listed here.
A key thing — particularly, as Curt mentioned earlier, with refactoring the way we're using templates — is that it allows us to be responsive when users want new features implemented. It helps us ward off requests for admin rights in the control plane.
We're prepared to fully go live with a simple switch of a CNAME. We switched the service in our campus DNS to the new delegated subdomain, and that service is live in HAProxy.

Curt Barthel
Lessons learned for us? We had to get all 1,100 load balancer manifests deployed well in advance of go-live — so we're done. We haven't gone live in production, so we're sort of straddled right now. Non-prod is all migrated alongside a few production things that have self-selected to go live, but the remaining prod configuration is still in Avi. But we're ready, and we're done.
It's a CNAME switch at this point. It was really important for us to get all of those things deployed well in advance, so that we could confirm all those configurations are syntactically valid and result in the intended HAProxy configuration. It also validates all of the existing manifest features, plus the new ones we exposed. And thus we've prepared for a scenario where early adopters are like, "Yeah, I'd like to go live now instead of going live at a scheduled time." That's very handy.
It's also been great to have the production environment ready for training our power users on working with the HAProxy Fusion GUI. Now it looks like it will look when they go live. Our whole model is predicated upon the idea that we're operating the new HAProxy load balancer side-by-side with Avi. This setup affords us that simple and quick migration strategy. It provides us with a simple, quick fallback option if we encounter problems.
It even accommodates our ability to say: oh, there's this additional manual configuration scenario that we really didn't test adequately, or the users who own a certain manifest didn't test adequately. We can now discover an issue and perform a side-by-side comparison before rapidly deploying a new parameter change in HAProxy. This fixes the problem and enables us to go live with that service, as well.

Next, we have critical success factors. That HAProxy Slack channel is impressive! I'll use the word unparalleled. I'd say remarkable, but people use that all the time in different contexts. But the Slack channel is just unparalleled.
It's been amazing as we're trying to learn these technologies, because as I said, Kevin and I are responsible for other platforms and not just load balancing. And so the amount of time we get to spend with this particular platform doesn't allow us to be the masters of everything. We've got to learn it, spin it up, go live, and be able to rely on it. Having that wealth of expertise is absolutely invaluable. Shoutout to the amazingly patient and knowledgeable support team, Nathan Wareman, Mark Boddington, Jakub, and everyone else. I could name everybody, but it's just been amazing. Thank you so much.
Another critical success factor was having regularly scheduled check-ins. We didn't always need them, but it was just really great to say: all right, we've got these three punch-list issues that we really need to get answered sooner rather than later, and we knew exactly when we could expect to be able to chat with somebody. That really helped out a lot.
Finally, engaging our power users early in the project was so critical. Once you have trust, you don't want to squander it. The critical period in this process is really the ramp-up to go-live. We got that early trust — that buy-in — and people are using HAProxy. They're in HAProxy Fusion saying, "This looks great. This is much better than what we used to have." That's the kind of feedback we want to hear. Having the ability to test important services way earlier is key, and gives us time to treat those projects more like pets than cattle while ensuring their go-live success.

Before we end, I'll harken back to Kelsey's analogy with the Tetris blocks. I think some of that applies to our environment, because I feel like what we've done is limit the number of Tetris shapes that our users need to work with. Can you imagine what it would be like if there were 20 different Tetris shapes and you had to try and fit them together? I feel like that could have been the case. But it wasn't.
Now, teams can get busy figuring out how to connect these blocks together to create new solutions. HAProxy was the key to providing that. Thank you.
Dylan Murphy
Gentlemen, amazing. That was a lot of breadth covered. Our first question in the stream: is there any feature you don't use?
Curt Barthel
Is there a feature we don't use? Well, I said WAF. There are some other features we don't use, but we want to.
Dylan Murphy
That's what the follow-up was — when do you plan to do that?
Curt Barthel
Yeah, so the Security Control Plane is very intriguing. We're doing elementary stuff with regards to blocking and allowing and things like that. If we could give the power of that technology to our users by exposing a few simple parameters that we can kind of scope down into a single or a few blocks for them, that's harnessing power.
Kevin Doerr
Yeah, that and the UI that lets them understand what's going wrong with their application, who's attacking it…and from where.
Dylan Murphy
I love the Tetris callback analogy. That was clever. A question about Slack. A lot of folks — probably everyone — use Slack in some capacity. We do have the HAProxy community Slack as well. Which is the one that you were talking about?
Kevin Doerr
We've got a customer support Slack channel. We wouldn’t be on the timeline that we’re on without that. We would be months away from going live.
Dylan Murphy
Another one in the stream: is the manifest so far restricted to what Avi used to do? You converted every Avi capability to HAProxy capability without issue?
Curt Barthel
So our new manifest, or the new version of the manifest, is now fully supporting every configuration that we used to have in Avi. Some of those were manual — now those are all implemented in our manifests — and we’ve exposed new parameters already in HAProxy only. What’s nice is having a single Git repo, and we’ve got another Jenkins pipeline that goes against Avi. What we do is sort of track the changes and keep them in sync.
As Kevin said, the volume of changes is such that we can afford to do that. What we don't have to worry about is introducing this new parameter in the manifest and having Avi struggle with that parameter, but who cares? The Avi automation and its Jinja2 templates don't read that parameter. So it's not a problem.
Dylan Murphy
This is an RBAC question. How do you use HAProxy Fusion to limit access for some users to read-only, and how much flexibility do you have in setting user-access permissions?
Kevin Doerr
Right, as we mentioned earlier, our users have read-only access. They can see all the metrics and stats. They can even use that for troubleshooting. But if they want to deploy changes, they're going to do that through deployments to the pipeline.
Audience
Hey guys, great job. You must have had an excellent sales rep that you worked with in the evaluation process. What was the thing that swayed your decision during the evaluation process to work with HAProxy versus the alternatives?
Kevin Doerr
Probably the responsiveness to our questions. Less grandiose marketing in the initial conversations. We wanted something on-prem as well.
Curt Barthel
I would agree with Kevin. It felt like we didn’t get this massive team that showed up to try and show us all these features that we weren’t going to necessarily use. And what you did was listen to us and allow us to express our use case. Then you assured us that what you provide is not vaporware.
You actually helped close those gaps between our knowledge and what you do. That’s so important because there’s always that 20% that you just don’t know about. I think you’ve reduced our blind spots substantially.
Kevin Doerr
…Or that stuff that works on paper, but doesn’t work when you try to implement it?
Curt Barthel
Right, right, right.
Dylan Murphy
Excellent! Gentlemen, thank you so much. Everyone, again, give it up for Curt and Kevin. Thank you.
