Roblox, a popular online gaming platform, has undergone significant infrastructure evolution in recent years. A crucial aspect of this evolution is the migration to HAProxy Enterprise, a scalable proxy solution.
We will delve into the history of load balancing at Roblox, the benefits of their new solution, and the tools they've developed to gain increased visibility into their load balancing setup. We will also explore how Roblox leveraged HAProxy Enterprise features, such as dynamic updates and Web Application Firewall (WAF), to further improve their load balancing setup.
In this article, we will discuss the challenges Roblox faced during the migration process, the tools they developed to overcome these challenges, and the benefits they've achieved with their new load balancing setup.
We were excited to welcome back the team from Roblox, who also joined us in 2022 to discuss their approach to data-informed decision-making.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.





























Chris Jones
Howdy everyone, and welcome to our talk on Dynamic HAProxy at Scale: Roblox's Infrastructure Evolution.

Chris Jones
A few quick introductions before we get started. My name is Chris Jones, and I'm a software engineer on the traffic team at Roblox. I've been with Roblox for three and a half years, but I started as an intern. I had a great internship experience with Roblox and was happy to return as a full-timer after graduation.
Ben Meidell
My name is Ben Meidell. I'm a senior site reliability engineer on the traffic team at Roblox. I've been at Roblox for about five years. Currently, I work with load balancers, but I've worn many different hats during my technical career: network engineer, wireless network engineer, security engineer, software engineer, and even tech support engineer.

Chris Jones
Quick table of contents for what we're going to talk about today. We'll start by explaining “what is Roblox?”, and then we'll get into the history of load balancing at Roblox and how HAProxy factors into that history. We'll then talk about our in-house Roblox Load Balancer solution powered by HAProxy, and then we'll discuss some tooling surrounding creating extra visibility with logs and metrics. Then we're going to talk about some HAProxy Enterprise enhancements, most notably dynamic updates and the WAF module. Finally, we'll talk about our automated build pipeline, and then we'll end with a Q&A.

Let's talk about what Roblox is and the scale of our systems.

For those who haven't heard of us, what exactly is Roblox? To put it simply, Roblox is an immersive gaming and creation platform. We provide and maintain the Roblox Studio software, a free experience creation tool designed for both accessibility and power, and the Roblox platform itself, where experiences like games and other social spaces are hosted.
The Roblox platform also offers built-in social features like chatting with your friends over voice or text, an extensive virtual economy featuring things like in-game purchases to enhance your experience, and avatar items to help our users express themselves to the fullest.
The content hosted on Roblox is almost entirely user-created, making it a unique platform for both devs and users alike. One of our most important tenets is that of safety and civility for all of our users. We want our platform to be one where everyone is empowered to create, learn, share, and thrive, no matter who you are.
TLDR: Roblox is a UGC platform where anyone can create what they want, spend time with friends, and be safe doing so.

To give some idea of the scale at which Roblox operates, here are some interesting numbers as of Q1 2025. Our platform has 97.8 million average daily active users, with 2.8 million developers creating experiences. We host 6.4 million active experiences and have reached 21.7 billion hours of engagement.
As you can imagine, these many users require high-performance, scalable solutions, which is a major factor in our choice of HAProxy as our load balancing solution. We currently manage hundreds of HAProxy instances across the globe in both edge and core data centers, and at our edge layer, we handle millions of RPS (requests per second) all the time. But we weren't always powered by HAProxy.

Ben Meidell
Now I'm going to talk about the history of load balancing at Roblox and how we migrated to HAProxy.
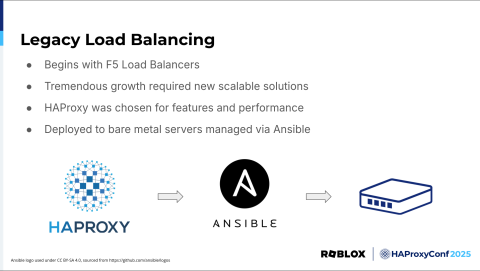
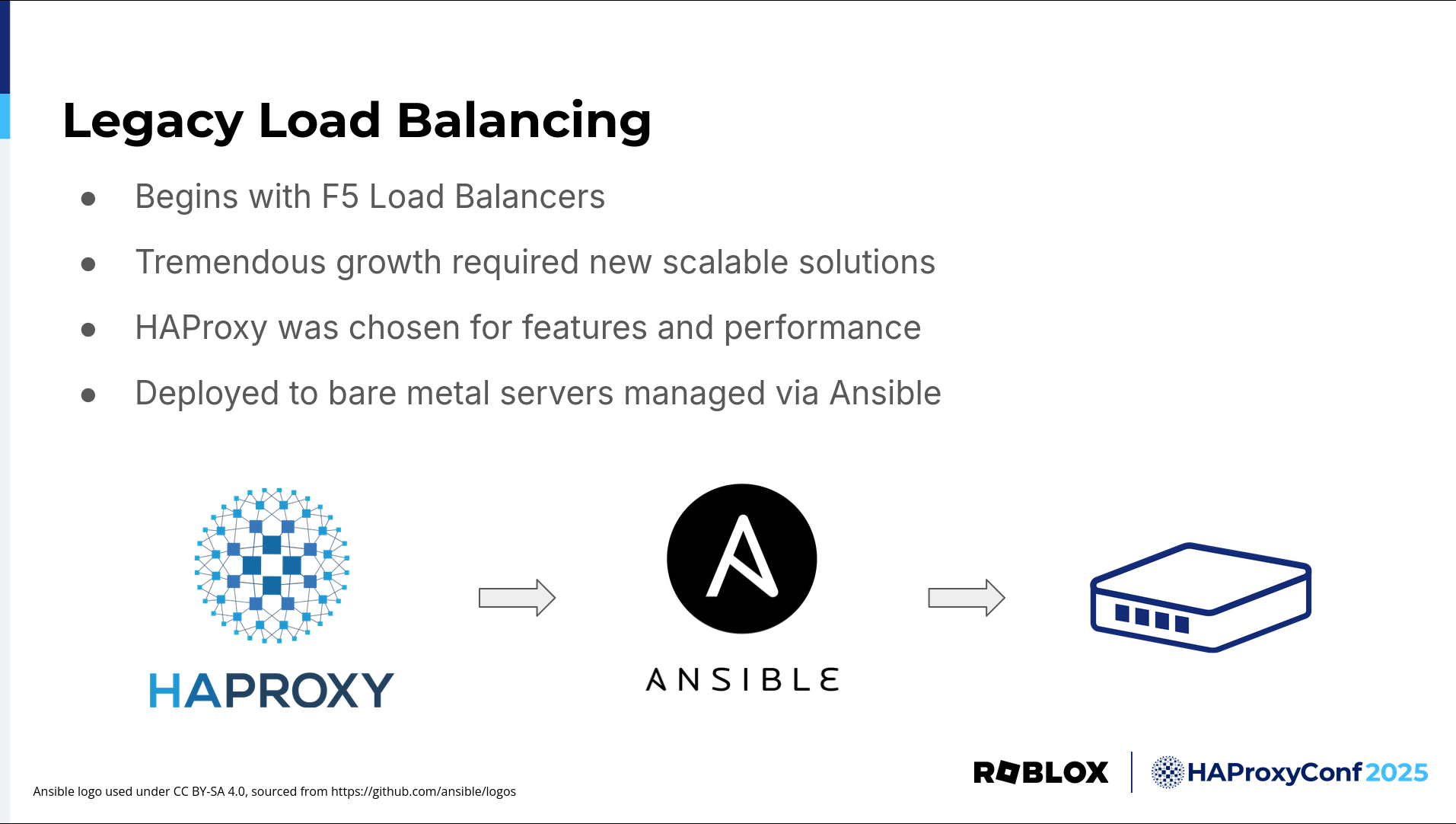
In the beginning, we had F5 hardware load balancers. They were fast and performant and met our needs up until COVID-19 happened. We experienced tremendous user growth during COVID-19. COVID-19 was a very stressful time for the world, and we were glad to provide a safe online environment for people to meet up, have some fun, and unwind.
However, such tremendous growth came with challenges and required new, scalable solutions. Using hardware load balancers was no longer cost-effective and, even if they were, we couldn't source enough to meet our needs during a time of such supply constraints.
We explored open-source software-based load balancers that we could run on general-purpose Linux servers. We considered many options, but ultimately decided on HAProxy due to it being a tried-and-true solution with the features we needed. OCSP stapling was a standout feature at the time, and most of all, its fantastic performance. At first, we ran HAProxy on bare-metal servers and managed the configuration and deployment with Ansible. This worked well for a first iteration, but it had some drawbacks that we needed to address.

There were several big disadvantages to this legacy design. First, deployments were slow. Ansible is a good tool, but it isn't the fastest, especially when dealing with hundreds of servers and expensive database calls to gather all the variables needed to render a complex HAProxy configuration.
This meant we were not as flexible as we needed to be. Pushing out updates quickly to address urgent changes was difficult. Changes include changing the load balancing algorithm for a specific service, such as “roundrobin” to “leastconn”.
Ultimately, there was a lot of engineering toil at all levels with this legacy design, and nobody likes toil. We needed a new and improved solution.

Chris Jones
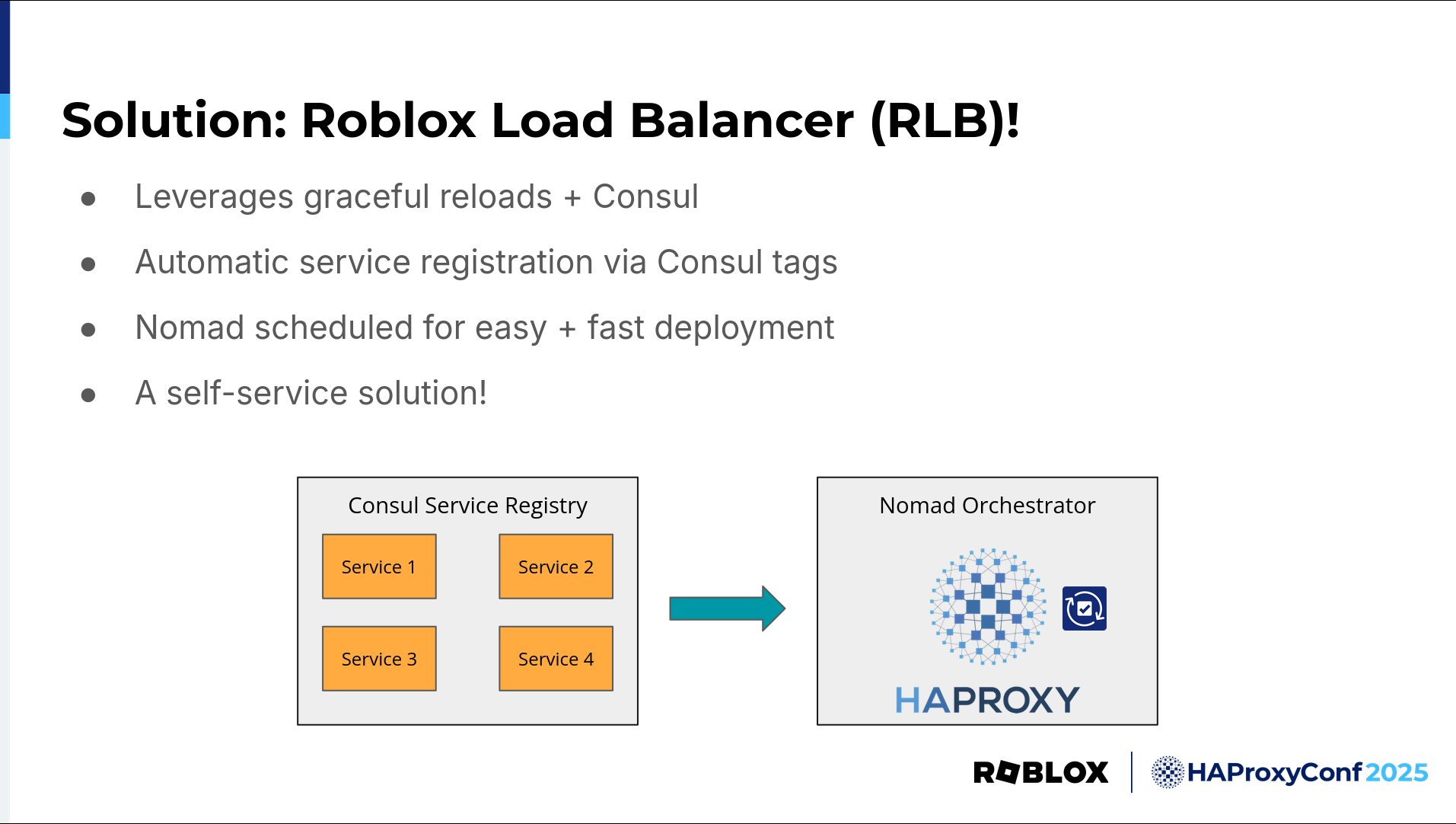
That solution is our in-house Roblox Load Balancer, or RLB, powered by HAProxy.
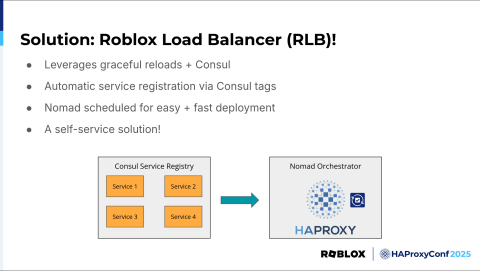
At Roblox, a simple name is the best, especially on an outage call. Roblox Load Balancer, or RLB, is a scalable proxy solution built with HAProxy. There are a few key advantages over our legacy load balancing solution, the largest of which is its self-service nature.
RLB, which is currently built on the HAProxy Enterprise Docker container, leverages Consul Template RB to scrape our internal Consul service registry, allowing service owners to self-register with RLB by simply adding the right Consul tags to their service, and then they receive traffic. We also allow configuration of features such as load balancing algorithms with Consul tags so that service owners can customize their load balancing to fit their needs. All of this can be done without any communication or involvement with the traffic team, greatly reducing engineering toil for all involved.
Additionally, RLB is scheduled on Nomad instead of running on bare metal like our legacy solutions. This means deployments are easy, fast, and reliable. Not having to worry about individual servers makes deployment much simpler. Orchestration also means the jobs are self-recovering. In the event we have instances go down for whatever reason, they're automatically rescheduled on other available servers, preventing a loss of capacity.
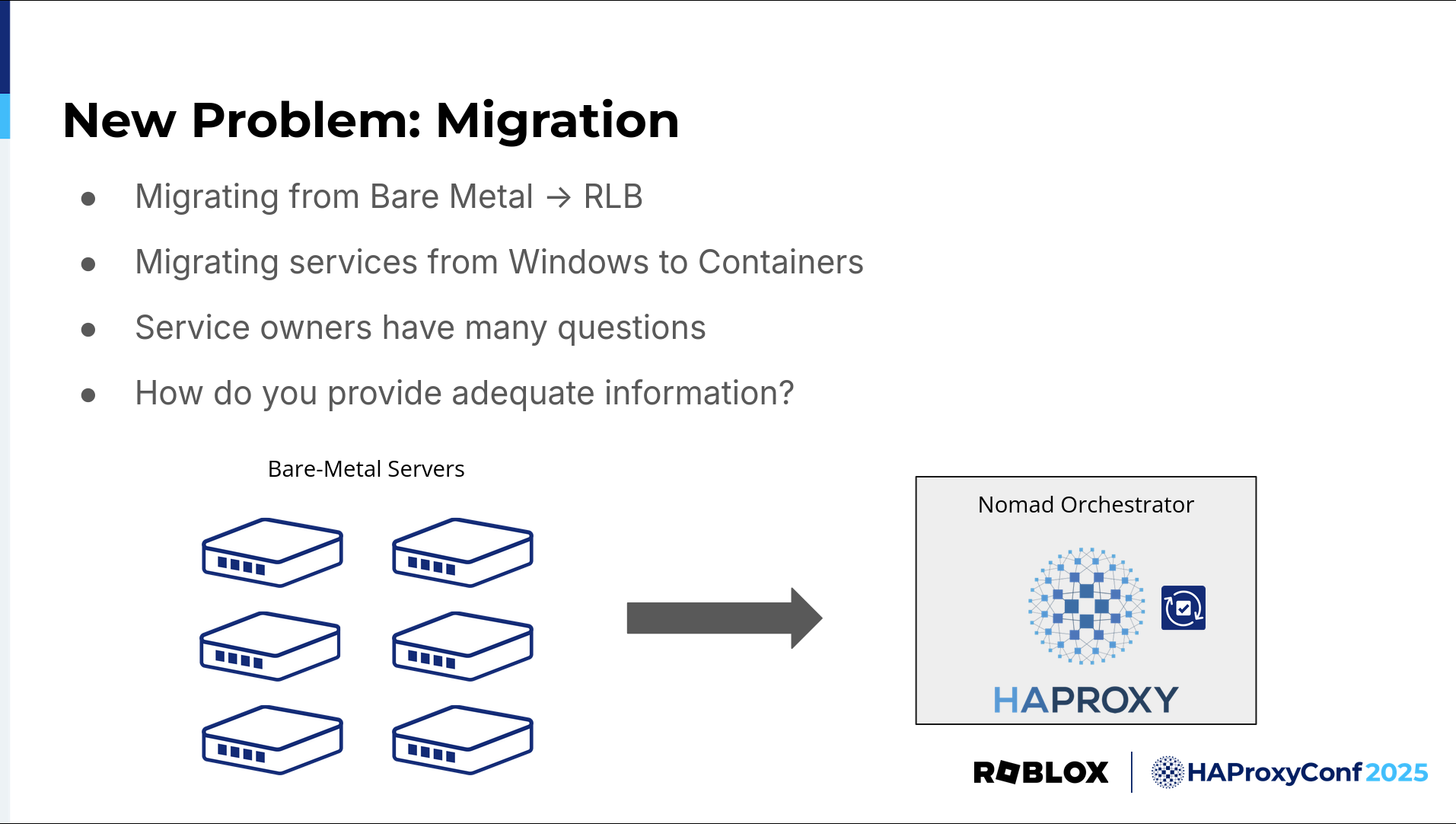
However, as you know, it's not enough to provide a cool load balancing solution. Migration from one load balancing cluster to another can be difficult, especially when your objective is to perform migrations live with zero downtime. So we now have the new task of migrating services from our legacy solutions to RLB.
But at the same time, service owners were also performing their own migrations from legacy Windows server architecture to new modern containerized deployments. There are many questions from service owners directed at us during these processes. So we need to adequately answer these questions and back up our answers with solid data. How can we provide this data? The answer is with logs and metrics.

The following section will explore some tooling we've developed that has allowed us to gain increased visibility by utilizing logs and metrics creatively.
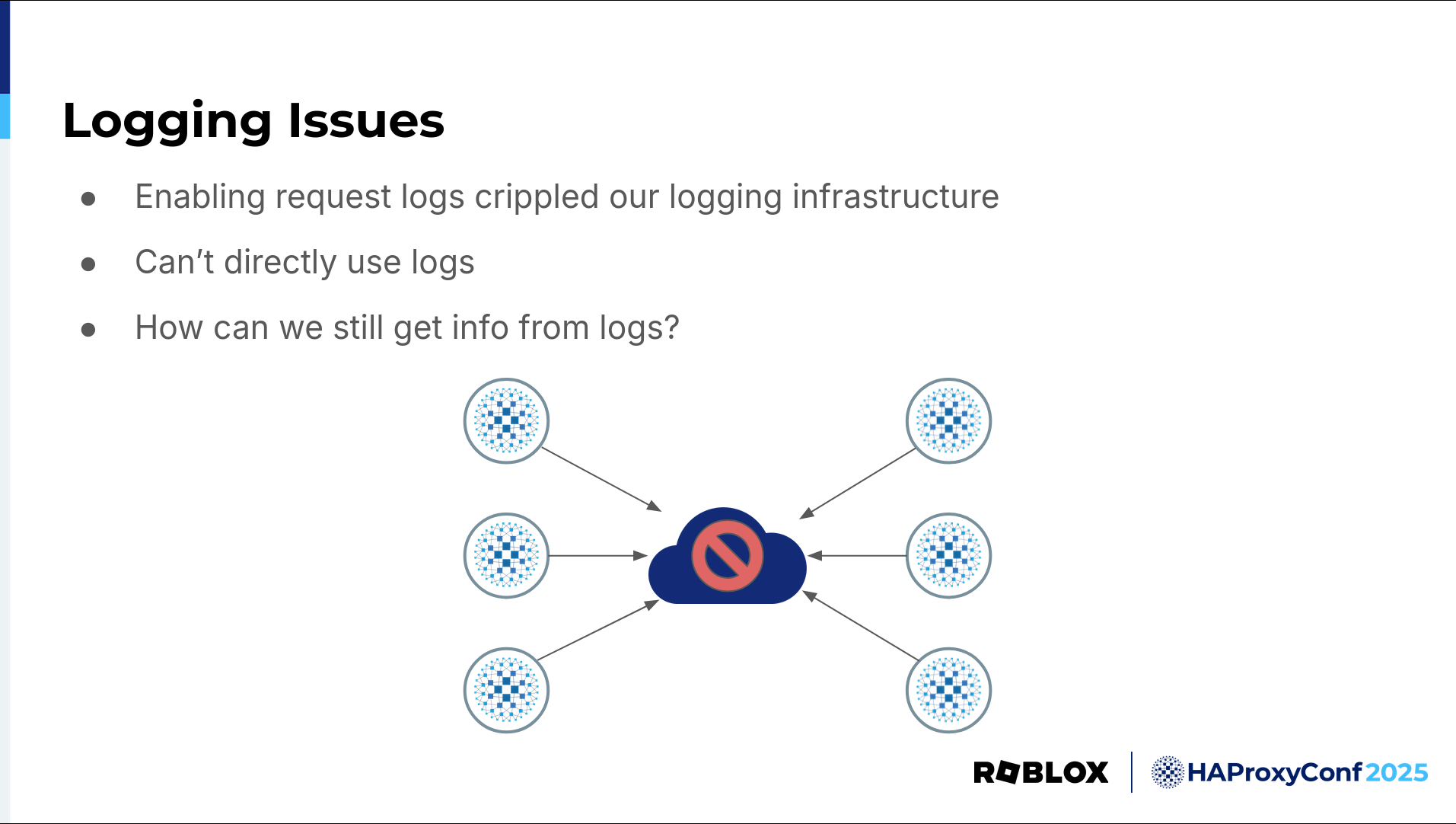
To start, here's a quick anecdote about our history with logging. When we first tried to enable logging from our load balancers to our central log infrastructure some years ago, it crippled our logging stack due to the sheer amount of logs we were sending, and our logging team kindly requested that we not do that again.
So, we learned we can't directly use the logs to help us answer questions about load balancing. How can we still glean information from those logs? We created a tool to answer this question.

Following our aforementioned simple name policy, Log2stats is exactly what it sounds like. It ingests HAProxy log lines over a Unix or UDP socket, parses them, and generates Prometheus-formatted metrics based on those logs. It's written in Go for a good balance between ease of development and performance, and lives as a sidecar container running on the same host as HAProxy.
The metrics generated from HAProxy's highly customizable logs allow us to gain visibility into information not natively provided by HAProxy's built-in stats. Most notably, this will enable us to group metrics by labels such as host header and status counter. This can be particularly useful when you have a lot of traffic flowing through the same frontend and backend proxy flow that you want to differentiate. In addition, a key field the logs provide that is not already present in the HAProxy stats is the termination code of a transaction.
For those who may not be aware, HAProxy provides a termination code for each request-response transaction that describes its final state. For example, it can help tell us if the backend server connection failed or timed out during the response, the client disconnected early, etc. The key feature of the termination code is its ability to tell you when nothing went wrong and the proxy worked exactly as expected. This is especially key during potential incidents where the root cause is not fully understood.
In these cases, it can be easy for people outside of our team to point fingers at the load balancers, and it then becomes the job of the load balancing team to absolve them of guilt, so to speak. The termination code has come in handy for this exact purpose many times. It has allowed us to speed up troubleshooting immensely by quickly removing the load balancer as a potential source of issues.
We have since upgraded our logging infrastructure to handle the increased load of HAProxy logs, but Log2stats metrics still provide immense value as a quick way to access data and correlations based on our logs. Suffice it to say, it has become a valuable tool in our HAProxy orchestration toolkit.

Another visibility issue we face is with HAProxy stick tables and other information exposed by the HAProxy admin socket. Quick rundown on stick tables: they are flexible, high-performance key-value stores built into HAProxy. They provide an easy way to accomplish tasks such as rate limiting, but it can be difficult to view the contents of these tables as they change. This and other information not found in other places can be viewed manually by sending commands to the HAProxy admin socket, but this isn't scalable or flexible. We needed a way to increase our visibility into these tables.

Ben Meidell
So we came up with Socket Exporter. Socket Exporter is a service we run as a sidecar alongside our HAProxy load balancers that periodically scrapes the socket for metrics not natively available in HAProxy. We would prefer all key metrics to be available natively, hopefully soon. Stick table data is one of these metrics.
We gather the data from these tables and then populate the data in a custom Prometheus metrics endpoint that our telemetry services can scrape. We also gather dynamic update success metrics and OCSP update metrics. Right now, we gather these metrics from the raw HAProxy socket, but we will soon start using the HAProxy Data Plane API.
More metrics mean fewer surprises. The improved visibility we've gained from Log2stats and Socket Exporter metrics has helped us with everything from service migrations to troubleshooting service and load balancer issues. We've found great value in them, and so have many teams at Roblox.

Chris Jones
While we have been able to greatly improve our efficiency at orchestrating HAProxy, with the tools and features we've discussed so far, there are still plenty of ways to improve our orchestration abilities, especially once we partner with HAProxy Technologies and start using HAProxy Enterprise.
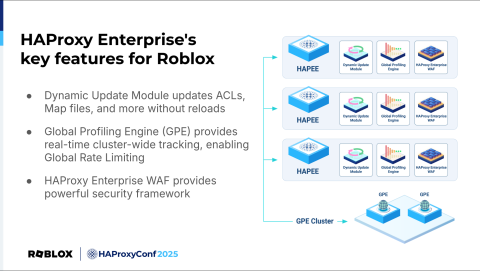
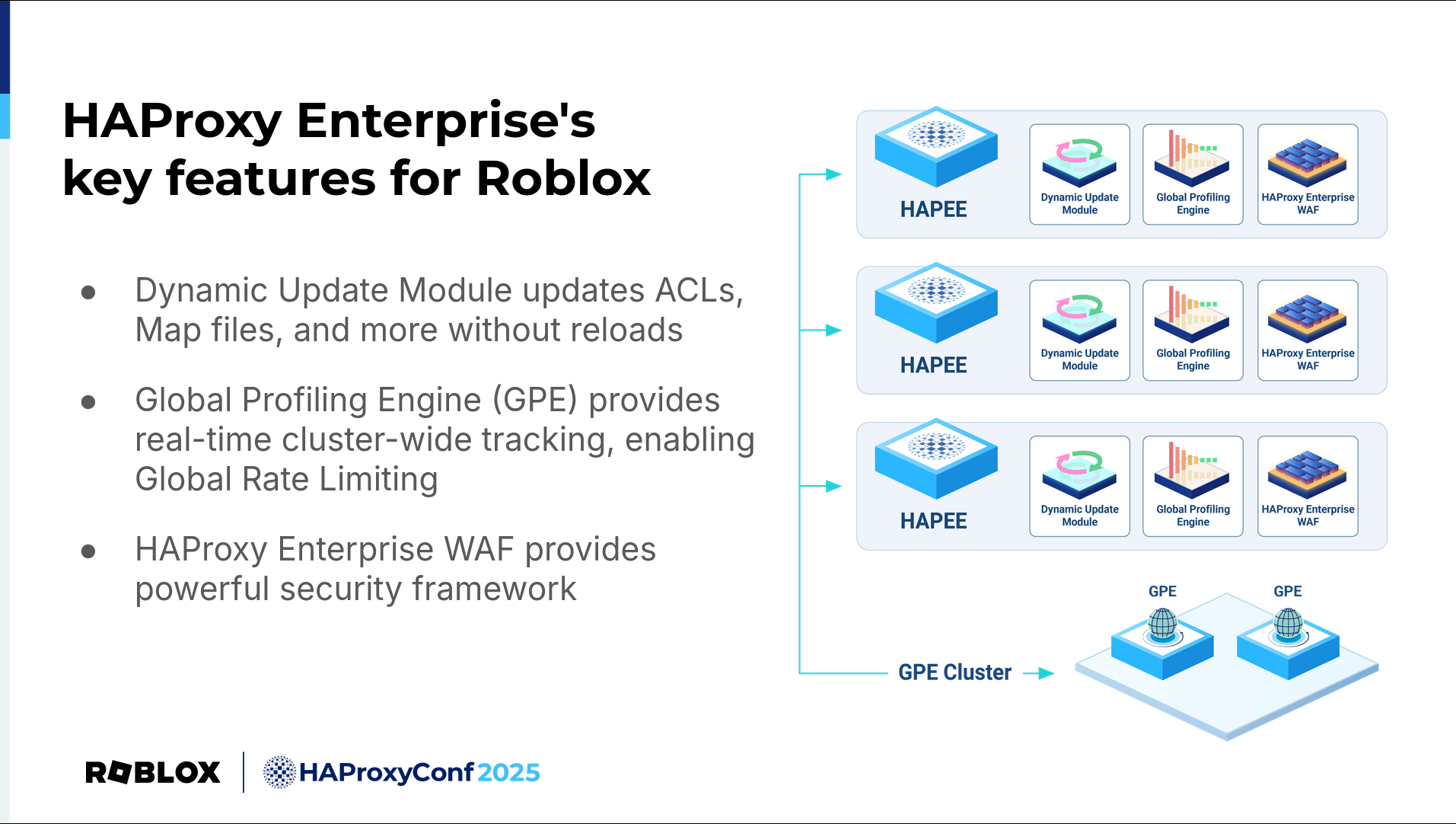
We're about to get into our usage of HAProxy Enterprise-specific features to improve our load balancing setup further. But before we do, here's a quick overview of our HAProxy Enterprise suite and some of the features we've been leveraging.
The Global Profiling Engine, or GPE, allows us to collect and aggregate the aforementioned stick table data across HAProxy instances and clusters, providing a more unified setup.
Dynamic updates allow for updating map files on the fly automatically by hosting the relevant files on a web endpoint.
And HAProxy Enterprise WAF provides a flexible and powerful security framework integrated into our existing load balancers.
Finally, I want to give a big shout-out. Access to HAProxy’s customer support has been very helpful. We often find ourselves deep in a documentation rabbit hole, trying to find specific information. In those times, it was a huge relief to be able to ask someone who intimately knows the software for input. Now let's get into the details about how we've implemented a couple of HAProxy Enterprise features.

The first of these features we'll discuss is the Dynamic Update Module.

What are we trying to do with dynamic updates? What problem are we solving? Well, map file distribution is hard. At runtime, HAProxy reads from map files and other consumable local information to make routing decisions. Map files, which can contain things like a mapping of host header to backend, are incredibly powerful and flexible but can be difficult to distribute at scale. Even with a nice orchestrated load balancing solution, manual map updates can take time and toil, with far too many engineering hours spent on what should be relatively small changes. We needed a way to distribute this consumable information quickly and easily while keeping our systems online and reliable. How can we accomplish this?
Ben Meidell
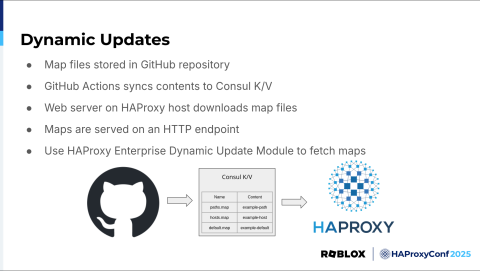
The solution? Dynamic updates using HAProxy Enterprise’s Dynamic Update Module. Dynamic updates are an HAProxy Enterprise feature that allows you to update the contents of some things, like map files, without needing to reload HAProxy. Very handy.
We implement this by storing our map files in a GitHub repository. Then, when we need to make a change, we open a pull request to update the map file. Once approved, we have GitHub Actions configured to automatically sync the contents of the map files to Consul K/V in our PoP HashiCorp stacks worldwide. Consul K/V is a key-value store for objects that's very handy for dynamically configuring applications. It also ties in very nicely with Consul Template and Nomad templates. In these PoPs, we have web servers running that watch Consul K/V for changes and automatically download them and serve them up on HTTP endpoints formatted for HAProxy to understand. The HAProxy servers then use the Dynamic Update Module to fetch the contents of these map files and update them without needing a reload. The process usually takes about 20 minutes to update all of our PoPs. The GitHub actions that sync the map file updates to Consul K/V do our PoPs in small batches and automatically watch for any negative changes in key metrics. If the metrics start to look suspicious for any reason, the update is canceled, whether or not our change is the root cause; better safe than sorry.
Many key metrics we watch are pulled from our custom Log2stats metrics that Chris spoke about. We also have a break-glass GitHub action that we can manually run if we need to immediately push out a critical update without regard for metrics, such as during an outage.

This has proven to be a significant improvement in how we manage our HAProxy servers, and here are some of the highlights.
These actions are as simple to configure as approving a GitHub pull request. Traffic splitting allows service owners to split traffic between data centers for testing and verification easily or to shift the load around. The same is true for service migrations onto RLB or between different RLB clusters, depending on the service's needs. We've successfully migrated hundreds of services without any intervention from our team needed.
We also gate certain HAProxy features using ACLs that check for values in map files, so enabling and disabling them doesn't require a full deployment or reload. Routing traffic and rewriting paths on demand has never been easier. Even subnet updates for specific traffic routing based on source IP.
These success stories are just a few of the ways dynamic updates have helped us and proven to be a valuable tool.

Chris Jones
Now let's talk about our implementation of the HAProxy Enterprise Web Application Firewall.

Another ongoing issue is our various security solutions for dealing with malicious traffic. While Roblox has tight security at all levels, that security can often come in various implementations throughout the network stack. These solutions can be inconsistent with their implementation, difficult to manage, and can create toil with our security team.
We needed a single, centralized security solution that was powerful enough to provide adequate security, flexible enough to adapt to our network and the ever-changing landscape of cybersecurity, and simple and easy to use, with full control in the hands of our InfoSec team. Bonus points if that solution can be integrated into our existing tooling and provides extra visibility to help our InfoSec team perform at their best.

Ben Meidell
Web Application Firewall to the rescue. Web Application Firewall, or WAF, is a Layer 7 firewall that you can run in HAProxy that helps identify and filter malicious requests, stopping them at the load balancer level and protecting services. It filters, monitors, and blocks malicious traffic.
Thanks to our implementation of dynamic updates, our security team can onboard services to the Web Application Firewall at their own pace. We can even enable enforcement for only a certain percentage of traffic to a service to slowly and safely ramp it up.
The required configs for this are in map files, including the host headers or paths that need enforcement and the percentage of enforcement. The host header and path are the keys in the map file, and the value is a number for the percentage of WAF enforcement. I'll share an example in a few slides.
Dynamic updates make WAF deployments very simple, whether ramping up traffic, adding allow-lists to rules files, or doing other tasks.
Finally, WAF on the edge load balancers provides a convenient centralized solution for Layer 7 security. Rolling out updates to address vulnerabilities is faster than doing it further down the stack, like on the services themselves. And it has great logs and metrics—a single pane of glass, so to speak—making it much easier to monitor.

Here is a quick summary of how we onboard a new service to WAF. Our security team opens a pull request against the map file in GitHub. Then, we approve and merge the pull request. Once merged, GitHub Actions push the map file updates to the remote Consul clusters. This is done on a staggered cadence, a few PoPs at a time, and key metrics are monitored to minimize surprises. The remote PoP web servers pick up the changes and serve them up for the HAProxy servers to fetch via dynamic updates. Seamless. We also have logs and metrics for service owners to monitor all the time.

Here's a config snippet of our WAF implementation for some more details. The top part is from the frontend config, and the bottom is the relevant map file. In the map file, we specify the paths of the services to onboard and the percentage of traffic we want WAF enabled on. This allows for a gradual ramp-up of WAF enforcement.
In the frontend config, for each request, we first set a variable that is a random number up to 100. Then we set a variable that looks up the value specified for the path in the map file, with a default of zero if the current HTTP request path isn't there. That means there is no WAF enforcement, or the number isn't specified. For foo.roblox.com here, that number is 50, meaning we want WAF enforcement on 50% of the requests to this service. In this hypothetical situation, we're in the process of ramping up WAF on this service.
Then, we check the current base in the map file to see if it's in there and should have WAF enforcement. Checking the ACL first for every request saves resources if the request isn't meant to have WAF enforcement at this time. No further action is needed. However, I do want to mention that we've been extremely impressed with the performance of HAProxy Enterprise Web Application Firewall.
We set an ACL that subtracts the random variable from the value specified in the map file and checks if the value is greater than 1. The math works out so that the number specified in the map file is the percent chance of WAF enforcement. If the ACL is true, the filter is applied, and if the WAF block ACL is true, because the request is considered malicious, the request is blocked. We also track these violations in a stick table called waf_table_enforce, and we can see them in our awesome metrics courtesy of the Socket Exporter service.
In summary, Web Application Firewall has proven to be a great tool in our security tool belt, and one of the best things I can say about it is this: picture what happens when a new security vulnerability is discovered. When this happens at Roblox, people are concerned, understandably. Which services are affected? How has the vulnerability already been exploited? How quickly can we protect our services and players from it? Well, in a situation like that, there is nothing more reassuring than knowing that we're already protected thanks to WAF. We share the documentation confirming the protection and the logs showing if bad actors have already tried to exploit the vulnerability and failed. This has already happened several times at Roblox since we've implemented WAF, and it's made for fewer urgent same-day service updates to address newfound vulnerabilities, and instead, some very reassured and very happy service owners.

Chris Jones
Now, even with the improved tooling offered by HAProxy Enterprise features, there are still enhancements to be made outside of HAProxy itself to improve our orchestration experience. Most notably, the implementation of a build pipeline.

What problem does a build pipeline solve? Well, when you're deploying manually, jobs have to be monitored, metrics need to be watched during deployment, and even a lot of manual testing needs to be done before deployment to prod can commence. Even with improved deployments, due to the previously mentioned Ansible to Nomad migration, an engineer still needs to manage deployments across sites, which is especially difficult globally.
Difficulty with deployment can lead to config and version drift, and it encourages engineers to pack multiple changes into deployments to minimize how often they occur. Not a good strategy for reliability. How can we further reduce the time taken for deployment tasks and make deployments as easy as possible?

Ben Meidell
So, we came up with an HAProxy build pipeline. A build pipeline is a core part of the continuous integration, continuous delivery DevOps principle that allows us to streamline how we push out updates to our load balancers. A good build pipeline improves trust in the system. It minimizes surprises during rollouts, especially when rolling out major updates like new HAProxy versions or new modules like WAF.
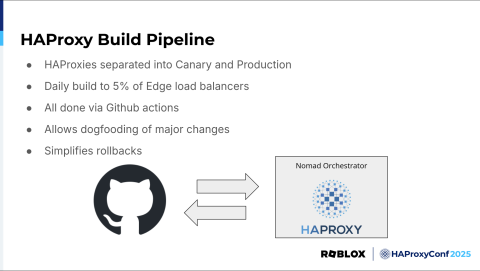
For our build pipeline, we separate our HAProxy load balancers into canary and production instances. Our canary instances are about 5% of our fleet, and we do a daily build, business days, where we pull and deploy the latest HAProxy Enterprise image for the major version we're currently running. This also keeps us up to date on things like the WAF rules binary.
Using the HAProxy Enterprise Docker container has been a big help here, a convenient base image that is easy to manage and deploy. Our daily 5% rollout is slow, a few PoPs at a time, and key metrics are automatically monitored. If there are any issues, the daily build is paused, and we are notified.
Once the daily build is complete, we can promote it to canary and roll it out to all the load balancers when ready. This is all done via GitHub Actions. This allows us to dogfood major changes and catch surprises as quickly as possible. Rolling out major changes to only 5% of our fleet at a time also simplifies rollbacks, if necessary.
In summary, our build pipeline helps us to have more confidence in our load balancers, has spared us from toil, and greatly improved our day-to-day operations. It is a big step forward in our infrastructure evolution.
Chris Jones
Finally, before we finish with the Q&A, we wanted to invite y’all, if you found our discussion today interesting, to check out our open opportunities. Today, we've talked about just a few interesting projects at Roblox, but there are always new innovations happening throughout the company on our various teams. If you find an open position you think you might be a fit for, we invite you to apply and join us.

Chris Jones
Now let's open up the floor. Thank you.
Dylan Murphy
Gentlemen, great stuff. We have a few minutes for questions, so again, raise your hand nice and high if you want to ask a question. We'll have a few. We have one that came in on the stream, so we'll ask that. We're getting the mic over there.
Audience
How does Roblox deal with the volume of logs and metrics?
Ben Meidell
Very carefully. We have a robust logging pipeline maintained by a dedicated team at Roblox that is constantly improving and updating. Some of the specifics would be beyond the scope of the presentation, but it is a constant; it is always something. Everybody wants more logs, metrics, visibility, and to be as nice to that team as possible and be as respectful of resources as possible. That's why we've been so creative with our metrics.
Audience
Hi. Knowing what you know now, what can you advise someone who's migrating F5 to HAProxy Enterprise? And what's one major consideration that you feel should have been there from the beginning, if you could do a do-over?
Ben Meidell
That is a good question. To migrate from F5 to HAProxy, do it slowly, have lots of metrics, as many logs as possible, and key metrics across the board. And I'm going to give a shout-out to HAProxy Technologies here. We originally did this without HAProxy Technologies. And if possible, I'd recommend partnering with HAProxy Technologies to get sanity checks on configurations. Also, focus on doing it as dynamically as possible from the get-go if you get to do it in a proper greenfield environment. There's the old classic analogy of you're trying to change the wheels on the bus while the bus is going 70 miles an hour. Our growth was so exponential during COVID-19 that we had to make some sacrifices in terms of some things that we wanted to tackle right away, and we kind of had to push it to the back burner a little bit, so that we could keep things going as stable with the experience that our users require.
Dylan Murphy
What sort of data does Roblox convert from stick tables to metrics?
Chris Jones
We mentioned stick tables are a really good, easy way to rate-limit. As we decide on an adequate rate limit for a given service, having something like the host header for that service combined with the request rate is extremely handy to export and graph historically. You can tell, oh, here's the absolute peak of this service's rate and the minimum. What's steady state and stuff like that? So yeah, the request rate of a given host header is extremely handy to view via metrics.
Audience
So, I was going to ask the most important question: Dundee's World or Grow a Garden for you? But really, the question is, what's next on your roadmap, personally? What are you trying to do next?
Ben Meidell
More dynamic. We would like to focus on minimizing reloads on our HAProxy servers as much as possible. That's something on our roadmap. I'm excited to hear some things in the works here at HAProxy about ways that HAProxy can be built more dynamically and require even fewer reloads than it currently does. And a few other things as well. But that's the biggest one I'd like to shout out.
Chris Jones
And I want to tackle this real quick. You mentioned Grow a Garden. For those unaware, Grow a Garden is a relatively recent experience that has recently become very popular on Roblox and has been breaking records for concurrent players in a single experience, which has been very interesting for us. And it has proven to me, especially, as I mentioned, I've only been here three and a half years, but running a user-generated content platform like this, you can't always predict what will happen on a week-by-week basis. You can try, based on historical data, but someone may show up, make the next Grow a Garden, and suddenly you have a lot more load to deal with that you weren't expecting, and you have to deal with that. So always plan for more than you expect.
Dylan Murphy
There was a question in the stream, partially answered already, but it is related to becoming more dynamic and what you mentioned. So the question is, as a user-generated content platform, how do you handle spikes in traffic for popular games like Grow a Garden and events?
Chris Jones
Nothing beats sheer capacity, which we're focusing on. We're doing everything we can to optimize our usage, blocking traffic that we don't need to transfer earlier to save CPU usage further down the stack. We are focusing not just on capacity because that's often a pitfall. If you throw enough load balancers at the equation, everything will work out; that's not always the case. You also need to focus on how you use your load balancers and ensure you use them optimally.
Ben Meidell
I also want to give a shout-out to Chris here, especially for a lot of the hard work that has been done on logs and metrics. Because as you scale, I'm sure folks here are familiar with discovering bottlenecks and pain points that nobody could have thought about. It's like, wait a second, saturating the NIC on a proxy server somewhere or a caching server, wow, that's a new one. So, having as many metrics and logs as possible to minimize surprises is always a huge plus.
Dylan Murphy
Last question. Any performance impact from enabling WAF on your traffic?
Ben Meidell
Honestly, I couldn't tell. It was so impressive. I set up everything to make it so that we can scale it. Because, of course, one of the big points about scaling up WAF is you want to make sure that everyone's comfortable and confident with enabling something as important and potentially impactful as WAF. However, I have been extremely impressed with the HAProxy Web Application Firewall. I turned it on full blast in learning mode in one of my load balancers and one of my edge PoPs when I was first messing with it. And I'm looking at my metrics, and it's like tap, tap, tap. Is that updating correctly? Is this on? It's working. Everything looks pretty good. So yeah, it's been awesome. So far, I have not been able to tell in terms of CPU, which is always one of the biggest things we monitor because of TLS. Yeah, it's excellent work.
Dylan Murphy
Very cool. Well, Chris, Ben, thank you so much. Please give it up, everyone.

