
In today's interconnected world, ensuring robust application security is paramount. InfoBip, a global leader in business-to-customer communication, faced this very challenge as they scaled their operations to handle over 80,000 transactions per second across 62 data centers. While they already leveraged HAProxy for load balancing, reverse proxying, and SSL offloading, the growing threat of application-level attacks and stringent compliance requirements necessitated a more comprehensive Web Application Firewall (WAF) solution. This session delves into InfoBip's journey, from identifying the critical need for a WAF to their successful implementation of HAProxy Enterprise WAF.
This session will also explore the obstacles InfoBip encountered, including the demand for enhanced attack visibility, the imperative to reduce malicious traffic impact on their backend infrastructure, and the necessity to defend against both known and emergent threats. A significant driver was also compliance, as clients increasingly require WAF integration. You will learn how InfoBip navigated these complexities, including their need for rapid custom rule deployment to address bug bounty findings, providing essential breathing room for developers to implement permanent fixes.
Discover how InfoBip engineered a distributed WAF solution for their 62 data centers, ensuring each remains self-sufficient without introducing unacceptable latency—a critical requirement for their client contracts. This presentation provides valuable insights into deploying and leveraging HAProxy Enterprise WAF in a high-performance, globally distributed environment, moving beyond traditional signature-based detection to explore advanced behavior-based techniques and future developments.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.


































Juraj Ban
Today's topic is how we ended up in InfoBip with the HAProxy Enterprise Web Application Firewall.

We'll cover:
What our challenges were.
Why we needed a web application firewall in the beginning.
How we tested the HAProxy Enterprise WAF.
How we made the decision to go with the HAProxy Enterprise WAF.
We will also talk a little beyond just classic web application firewall and signature-based strategies, and cover some behavior-based strategies and our future plans with HAProxy.
We are a company that allows businesses to connect with their clients via various channels, and we are all around the globe.

We have 62 data centers at the moment in, probably, every region in the world. But what's important for our presentation is that we had more than 80,000 transactions per second last year on Black Friday. All those transactions went through HAProxy Enterprise and the HAProxy Enterprise Web Application Firewall. These two nice pictures are of our two biggest offices. The upper right one is Vodian, our headquarters, and the other one is in Zagreb. It's the biggest engineering spot in Infobip.

Almost two years ago, we started to test different web application firewalls. But before we continue with how we decided, it's important to know what we already had. We already had HAProxy deployed in our data centers as a load balancer, working as a reverse proxy. We already were doing SSL termination with HAProxy and we already had that stuff automated. So, SSL renewal and everything else were already automated.
Everything was highly reliable, and what we like in our production is that our services are run as containers. This was one of the benefits of HAProxy, that we can run it as a Docker container. Basically, that's how we run everything in our production. We also had high-volume networking and high-volume DDoS protection, but that's not enough, especially for application DoS attacks. So we'll see how we cover that with HAProxy Enterprise.

What were our challenges? We could say the challenges are the same as those in every other company or similar to those in other companies worldwide.

We wanted to get better visibility into attacks. We wanted to see what is happening, who is attacking us. We wanted to remove the burden of malicious traffic from our backends. We wanted to protect against known threats and hopefully against unknown threats like zero-days, Log4Shell, and different kinds of attacks.
But there is this important thing—compliance. So as we're dealing with clients, with our customers, I think that almost every customer, when they send us the questionnaire, asks a question: do you have a web application firewall? And if you say no, some clients don't want to sign a contract with us. So there is also a business reason we need a firewall. And that's also something important for us.
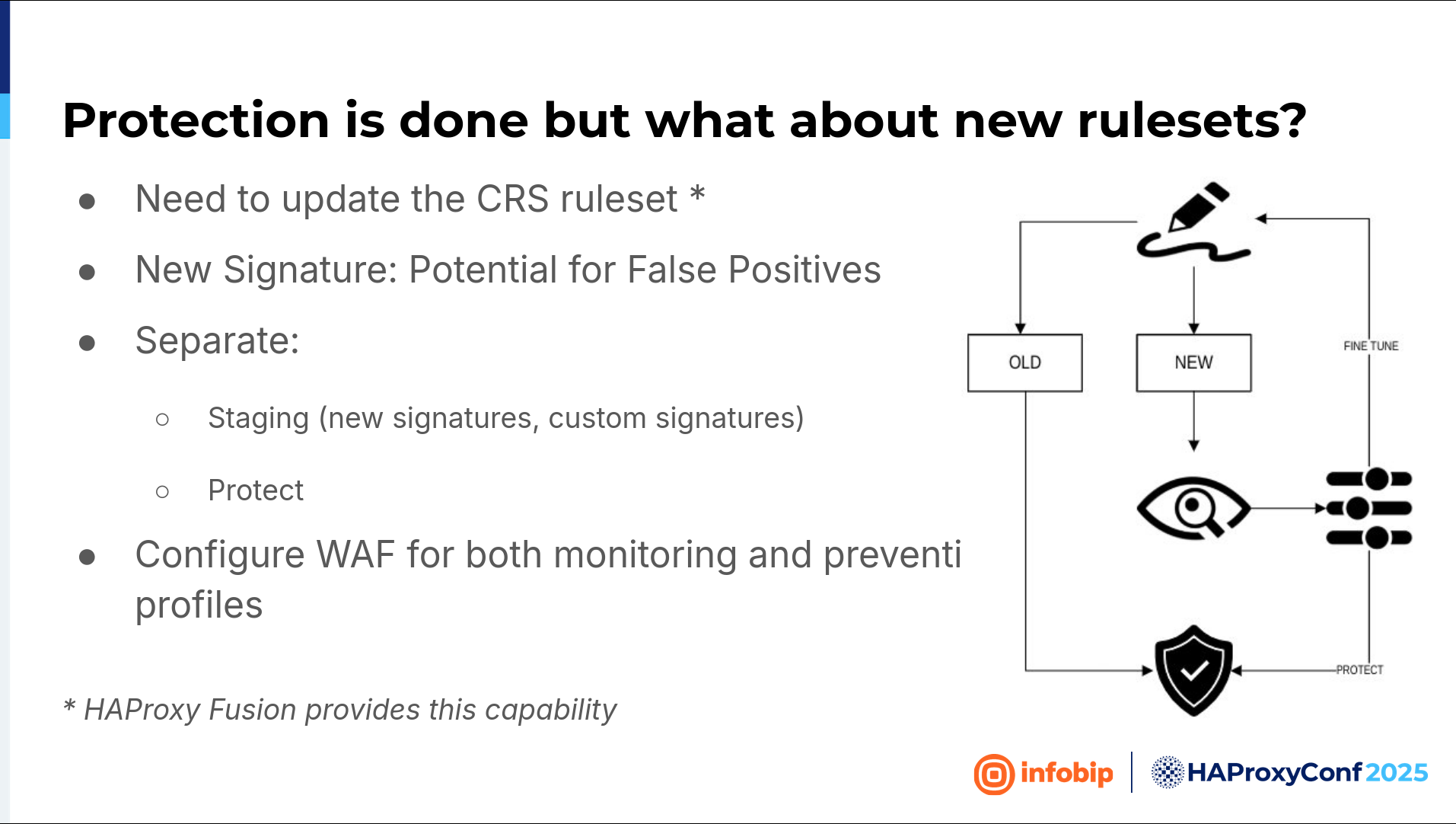
The custom ruleset. We want to create custom signatures, signatures that are tailored to our applications. We utilize bug bounty programs. When bug bounty researchers find a vulnerability, we fix it as fast as we can. We will fix it first on the web application firewall with a custom signature. And then we have time for the developers to test a fix and deploy it to production.

Our biggest challenge when we talk about web application firewalls is our design. We have 62 data centers. Every data center holds HAProxy Enterprise and a web application firewall because we want to do business in a way that if one data center is down, we don't care. If all data centers are down and only one is working, it must work for itself. So we don't want to have dependencies between data centers.
Another thing is that our solution needs to have really, really low latency. When we implement a new solution in InfoBip, we cannot introduce new latency. Why? Because we have our clients, we have customers, and a contract with a dedicated request and response time. We have clients with a dedicated latency. Then we started to explore different solutions, different vendors, and some customers had privacy concerns if we were to go with a cloud-based solution.

When we investigated cloud solutions, we also investigated software-as-a-service solutions and web application firewall vendors and what they offer. Our first question was, does it have a presence in all the regions where we are? The second question was, if they start processing our traffic, do we need to announce to all our clients that we are now using a sub-processor? Then this cloud provider should become our sub-processor. We didn't want that. If we look at the hardware appliances, we weren't satisfied with the scaling. And the price skyrockets because you cannot scale it efficiently over all of our data centers. We also don't like virtual appliances because our motto is that everything should be inside containers. That way, we can scale it as we want because we can deploy it in a number of minutes.

Our first decision was a logical one: let's try HAProxy. We contacted HAProxy Technologies. So, Boris, how did it go?

Boris Dekovic
Yes, so we reached out to HAProxy Technologies and they presented us with two different WAF solutions— the HAProxy Enterprise Advanced WAF with its fast WAF engine and strong security, and the ModSecurity WAF. ModSecurity uses the Core Rule Set, which is the de facto standard, and it's used by many other vendors.

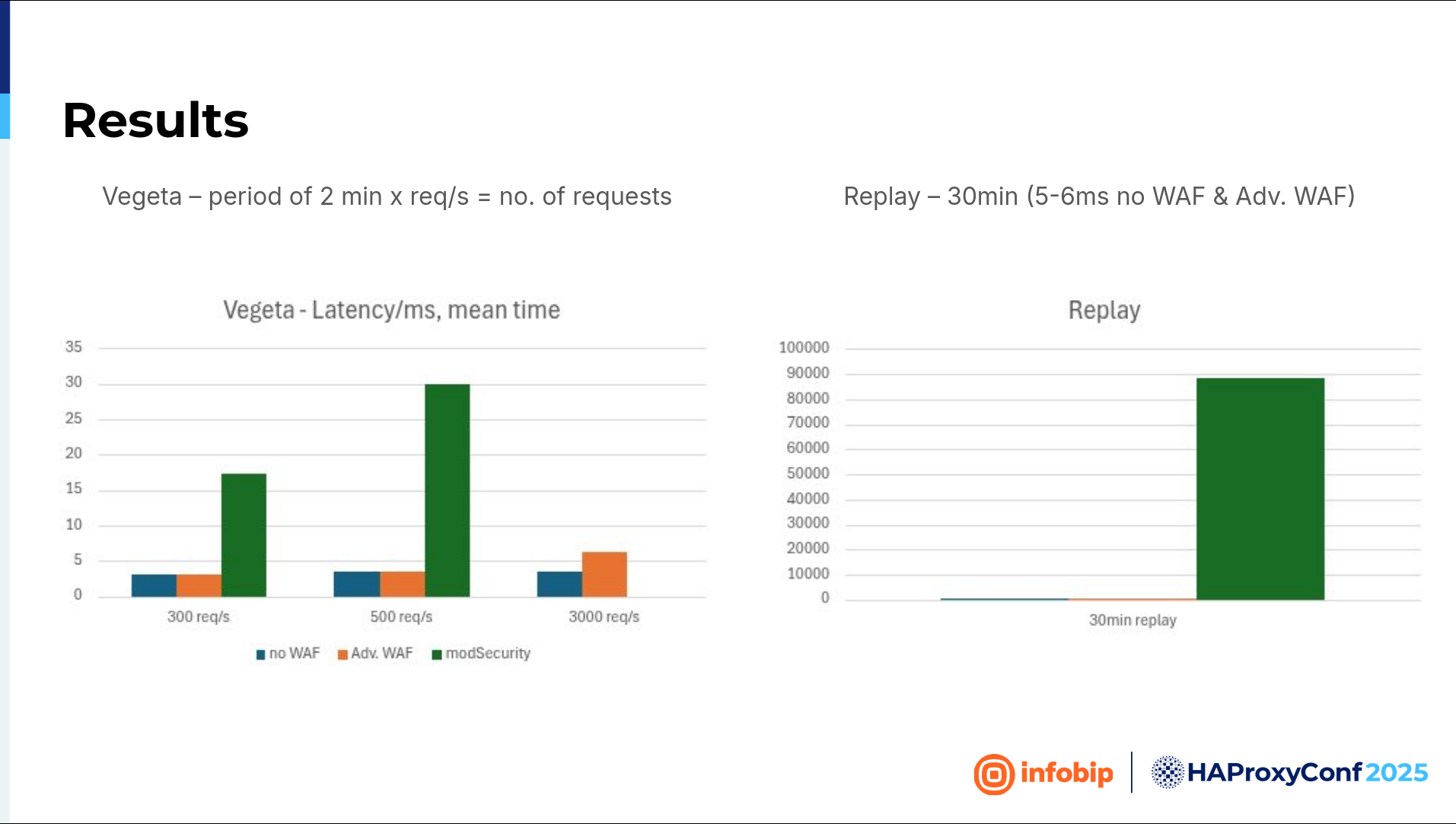
So, how did we test? We deployed one instance as a Docker container and started testing. We used Vegeta, an HTTP load testing tool, and we had two different scenarios.
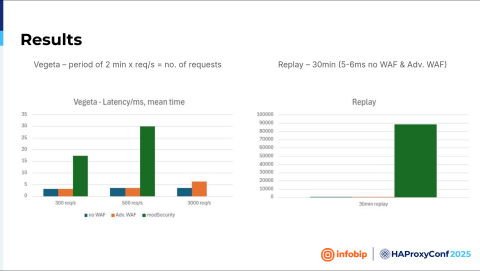
The first one was that we hit that instance with two minutes of different requests per second. And the other one was replaying captured traffic from the test. Traffic lasted 13 minutes, and we just replayed it, but three times faster.
On the left side of the slide, you can see latency. With the Advanced WAF and without WAF, latency is minimal, but the introduction of ModSecurity introduces some latency here. And in the third set, we couldn't even measure the latency with ModSecurity.
On the right side of the slide is the replay attack. So again, the Advanced WAF and without WAF are the same but in this test ModSecurity’s latency goes through the roof.
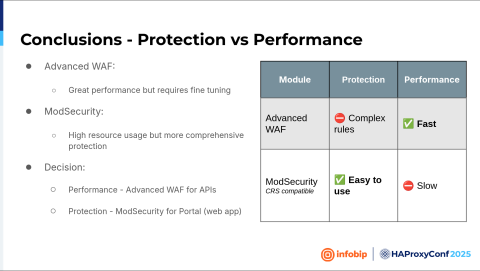
We must mention that we have both an API and web portal. On the API, we see a much higher volume of traffic than on the web portal, so the WAF must be able to handle all that volume. Regarding our testing of the Advanced WAF, it failed on the web portal. Why? It was too aggressive, so we couldn't create a whitelist here, whereas ModSecurity failed on the high-throughput API.

Juraj Ban
The difference was basically that the web application has fewer transactions per second, but it's much harder to fine-tune because it's a web application. On the other hand, the API has a clear structure, much more transactions, but it's easier to fine-tune.
Then we went back to HAProxy Technologies and said, look, guys, this will not work because we don't want to have two solutions. We don't want to have two different vendors for the web application firewall, like one for the portal and another one for the API.

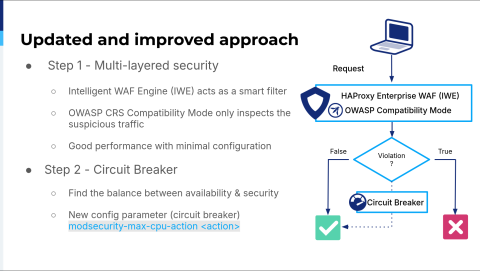
But it was a plot twist because when we contacted them, the HAProxy guy said, "Okay we have a new web application firewall called the HAProxy Enterprise WAF powered by the Intelligent WAF Engine." At that moment, it was called "Chained WAF", but now it's called the HAProxy Enterprise WAF. And everything that you see on the slide, it's nice. It's nice if you look at the brochure. I mean, they made the engine faster, more optimized, better. But what's important is under the hood. How does it actually work?
Boris Dekovic
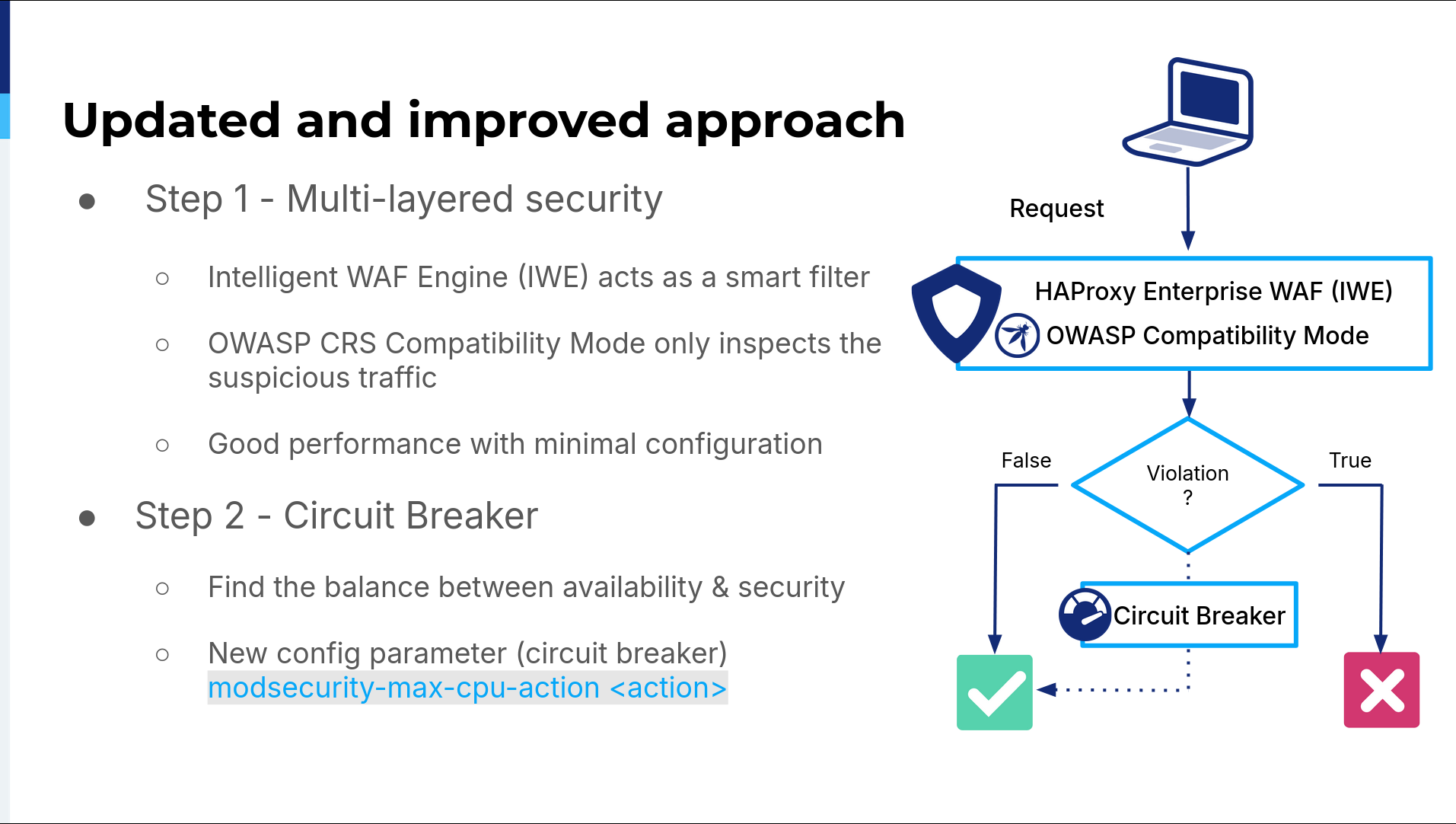
The same Advanced WAF with ModSecurity, but now the Advanced WAF uses the Intelligent WAF Engine as a smart filter, and it tags suspicious stuff, so ModSecurity will inspect that again. Also, they introduced this new feature where you can limit the CPU so ModSecurity won't hit the CPU limit.

It offers the best of the Advanced WAF, which is a fast engine, and the Core Rule Set of ModSecurity. We tested it, and it went fine, so we implemented it on the portal and then on the API.

Juraj Ban
When we knew that the stuff could work and the testing was successful, we needed to create a plan for implementing it in all of our data centers.

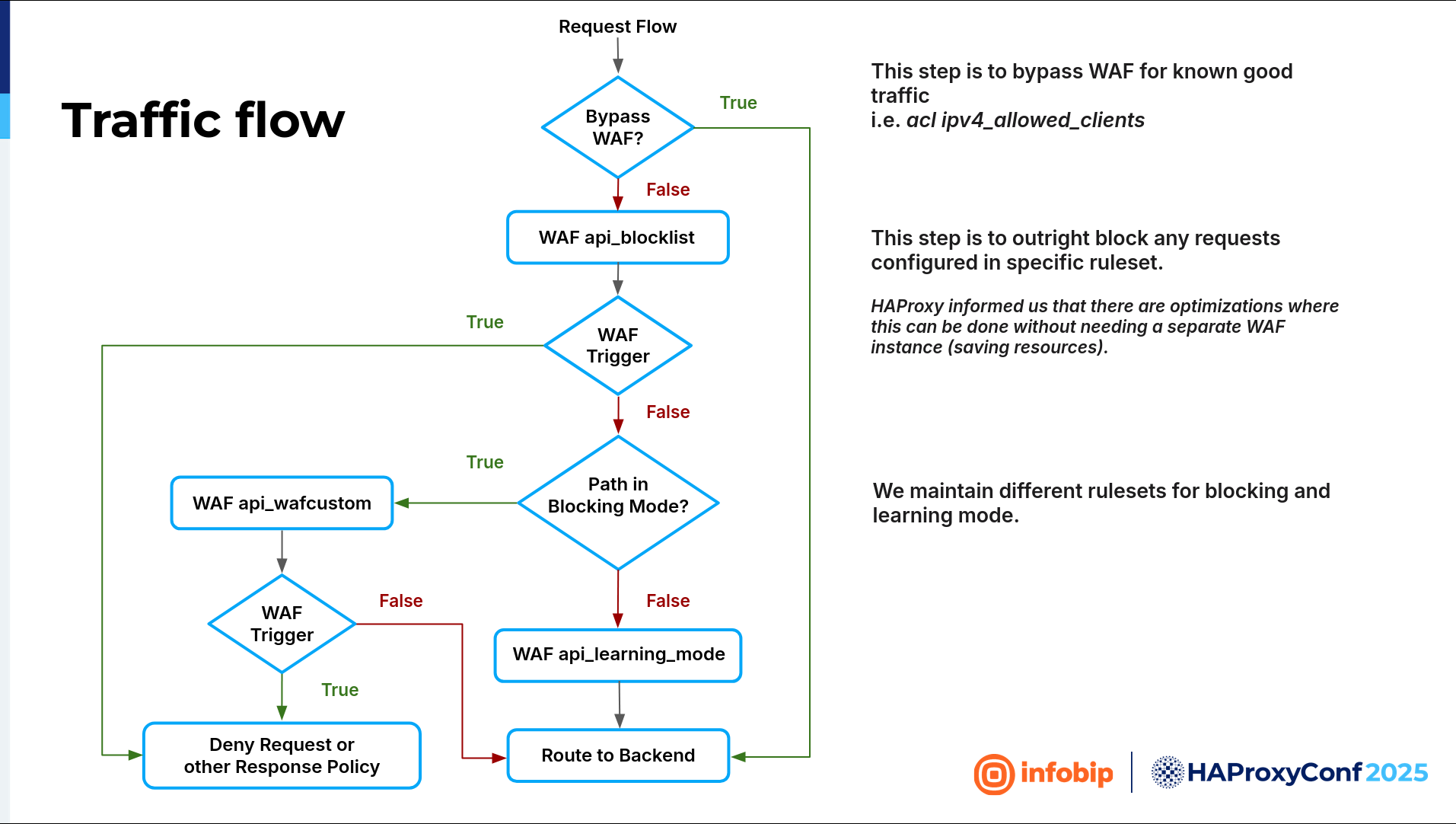
We started with deploying the web application firewall in all data centers, but in its learning mode, which is monitoring-only mode, because we didn't want to break stuff. We chose, at the beginning, to fail open, or basically we chose availability over security. Because while learning the traffic, we were learning how our application behaves, we were learning the requests, we were learning everything. We don't want to break production. If the CPU is above 80 or 90%, then we turn off the web application firewall. We review the logs, which alert us when that happens, and see if it's actually an attack or if we need to fine-tune something. Sometimes, we need to remove something so that it's not going through this smart filter.
To do that, we configure syslog; we ship everything to our log management solution and create alerts, dashboards, and everything that we need. When we started, HAProxy Fusion was not at the level it is currently at. So, that's something for the future, utilizing its latest alertings and dashboard features.
From the beginning, as we have had 60 data centers, everything must be automated from the central location because if we create some small change, I don't want to do it manually. It needs to be deployed within 15 minutes all around the globe. So this was our, let's say, baseline.

Having a baseline, we wanted to see if we could switch from monitoring-only to protection mode. And then it's okay. So, we have product documentation. Great! So we can match what is happening from the logs with our product documentation. Is it a false positive or not? Where is the challenge?
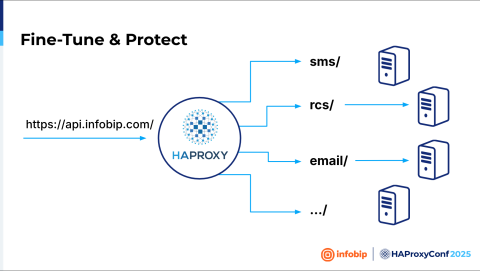
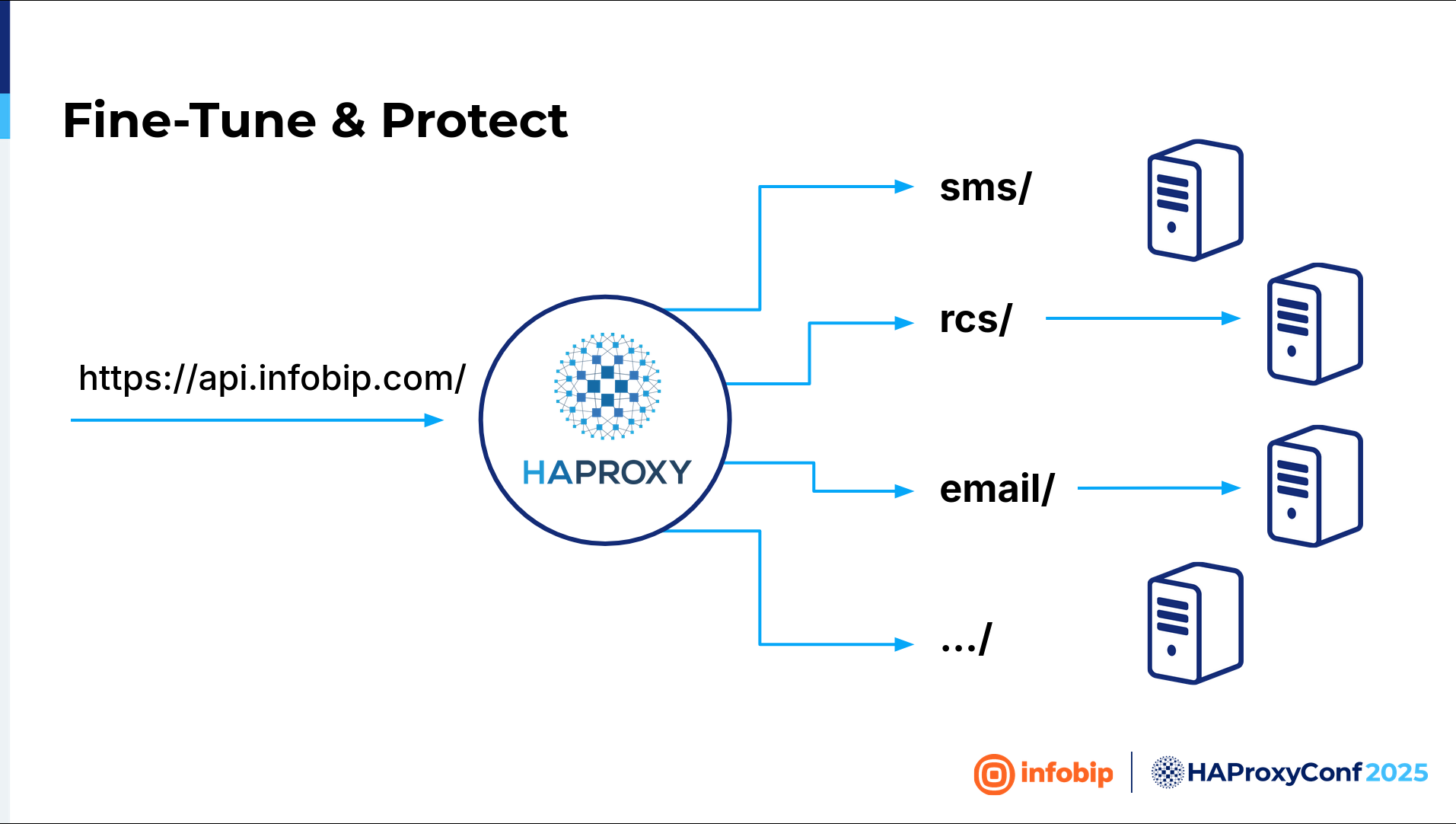
The challenge is in our design because we're utilizing this microservice design, where we have one fully qualified domain name like api.infobip.com. And then every part of that microservices design is basically another application. Like SMS, one application and one backend. RCS, another application, another backend. Email, WhatsApp, Viber, etc. We should look at everything as a separate application. So, we cannot enable the web application firewall for everything at once. We needed to create a plan.

We put everything into the WAF's monitoring mode, and then we watched path by path. SMS? Fix it. You know, be sure there are no false positives, and after you're sure there is no false positive, turn that path into protection mode.
And then we went application by application until we finished all of the applications. And then we switched the logic. Everything should be in protection mode unless we created a part in learning mode because it's a new application. And then, again, central configuration comes into play. So if a new application is up, we don't want to redeploy HAProxy Enterprise to all of our data centers. We want to configure a map file that will be automatically downloaded, and the logic will be there.
Boris Dekovic
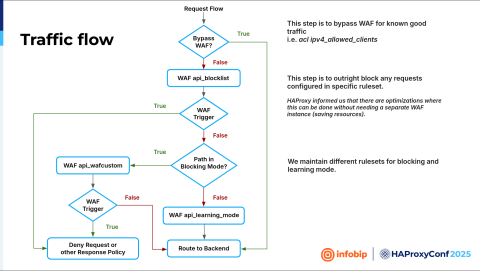
We ended up with three different WAF filters. The first one is named api_blocklist. All traffic will hit that filter. Here we can apply whitelisting, so we can bypass the WAF in some cases, for example, when we are conducting a pen test. Traffic that is not blocked on the api_blocklist WAF will go down further. So on the HAProxy Enterprise WAF, we write our whitelist, and it's the end.
Juraj Ban
We created a traffic flow for every case that you want to have. If you have pen testers, bypass the web application firewall because they require it; if we have new applications, put them in learning mode. If the application is old and everything is already set up, put it in blocking mode.
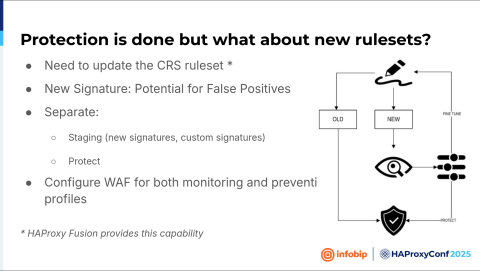
And we basically want to do the same thing for the new rule set. So if there is a new signature, every new signature is potentially dangerous because it can break things. It can add a false positive. In that case, we want to create a new signature. The new signature will go into monitoring mode again, and when we're satisfied that there are no false positives, we'll put it into the protection mode. If we aren't satisfied with the result, it's back to the fine-tuning. Monitor it for a few days. If everything is okay, put it into protection mode until we are satisfied with the result. The good thing with HAProxy Enterprise WAF is that you can create multiple web application firewall filters so that you can create logic for a scenario like that.

Boris Dekovic
Here's what this looks like in the code. We first define that circuit breaker and put that limit, and the action is to pass through. We load our block rules and extend the log format with new WAF variables.

In this slide, you can see the filter definitions: api_blocklist and api_learning_al. Those are the Intelligent WAF Engine filters. You can also see that ACL, ipv4_allowed_clients. In the end, we have a configuration for our WAF. So, this is the Intelligent WAF Engine to Core Rule Set.

Juraj Ban
When we solve the challenge of a classical web application firewall with signature-based rules, there is always a question: can we do something more with other layers offered by HAProxy?

And then we saw the stick tables. Basically, what are stick tables? A stick table is a feature that's just an in-memory buffer that stores some data. And this buffer, called stick tables, can be in the form of counters. And now, when you implement the web application firewall, you know your application. Now you know how your application works. Why? Because you created it, you fine-tuned it. You know where the login page is, you know where the unsubscribe page is, or whatever you have, logout, etc. Let's check how you can utilize these stick tables for different types of attacks. Let's say, account brute forcing, which is one of the common ones.

In our portal, when you go to the login page and write the wrong password, you will get an HTTP error code. So what can you do? You can watch in real-time, for example, one minute, five minutes, ten minutes. I mean, you define the threshold. You define one minute, and inside that one minute, watch the condition. The condition is if the URI path is login and you receive the error code, that means it's the wrong password. Then, count the number in the defined time, in the sliding window, for example, one minute. So, if I see in one minute that more than 10 times one unique source IP had the wrong password, basically received the error code, that is something suspicious. And for the next five minutes, block access for that IP. That's the logic behind stick tables. It's not that hard to configure.

Boris Dekovic
Here is how it looks in the code. First, you define that limit, and then you define an ACL. We're looking at the URI paths that begin with login or signup. Then, we define an ACL that will be set to true. If that limit is exceeded, we define a stick table where to store all that, and in the end, there is an action.

Juraj Ban
The same code can be used on different types to detect different types of common attacks. For example, how will vulnerability scanners affect your application? On our application, it will trigger redirects because if you're not authenticated, every request will be redirected to a login page. So if I see 50 redirects from a unique source IP, that is not usual for my application. Something is unusual. Why should I handle that traffic? Remove it. So block this IP.
It's the same with the error code. And there are some specific parts like login, logout, unsubscribe, one-time URLs, activation links, etc. Let's take a look at the unsubscribe. That's usually some URL with some hashed link or something like that that's unique for your email address. When you click, you are unsubscribed from, let's say, some mailing lists. So that URL is unique for me. Why should some source IP, one unique source IP, go to the 50 different unique URLs? That's also unusual, so you can block the traffic and deny that IP because it's not normal.
But what's good about HAProxy is that you can use multiple layers, like a web application firewall and stick tables, to define your logic where you can say, if the user is not authenticated, block. When you see a web application firewall alert, block it. But if you are authenticated, I may allow five web application firewall violations. I just want to be sure if there is a false positive that everything will continue to work.

And it's always a question: can you do something more? Because for the stick tables and web application firewall, you are utilizing some processing power.
If you have tools like Grafana or logging tools, you can extract information from HAProxy. For example, if it's malicious, but nobody creates a ticket that they cannot access your application...basically put all this information into a map file, create your own threat intelligence, and block it down the way.

And Boris, what was your conclusion when playing with the HAProxy Enterprise configuration?

Boris Dekovic
Starting with something new can be hard. So there is a steep learning curve here. You must learn that config language. We didn't have a UI but this is now fixed in HAProxy Fusion. But yeah, the engine is powerful and fast. Everything is working stably. So, yeah, if you want to add something.

Juraj Ban
Yeah, basically everything that we imagine with those configuration files, we can do. So we could say that this multi-layered approach from HAProxy was a success for our implementation. Why? Because we don't have any latency issues anymore. We don't have any false positives. We don't have complaints from our customers. That is the most important thing. And for future plans, we will start with the HAProxy Enterprise Bot Management Module. And we will also check out HAProxy Fusion.
Thank you. That's all for now.

Dylan Murphy
After setting up an app, do you still need much fine-tuning of WAF rules?
Juraj Ban
No. Not anymore.
Audience
Okay. Regarding the denying things that you are doing with the thresholds and so on, once the user or the attacker reaches the threshold, you deny the request. And we all know that when you deny something, this is information that you give to the attacker. And sometimes they try to fly under the radar and to change their behavior. Did you ever consider using some honeypots or some other tools like that to prevent from giving the attacker some valuable information?
Juraj Ban
Yes, we did. We have basically multiple thresholds. So, we have this thing where we redirect them to, let's say, a false portal.
Dylan Murphy
Who manages what is normal for each application? Is it the app developers?
Juraj Ban
Combination. What we are doing first is reviewing the logs. We take an example. For instance, we took one month. Then we create searches in our log management solution to create some kind of statistics. And then, in combination with the developer, let's say we ask him, look, by our analysis in the last month, this was like an average count of the hits. Is it okay with you that we put it, for example, 350 or 30? And if he says okay, then we go in that direction. And then we review it one or two months later, again, after. Why? To check if we can also lower it from our initial search because our initial search and our initial value are always a little bit above the threshold that we want, just to be on the safe side. And then re-evaluate after two months again.
Audience
Sometimes, when you're conducting an investigation into a web application attack with ModSecurity, you have to enable additional logging so you can review the post body data. Can you do that with HAProxy Enterprise's Web Application Firewall? And if so, have you done that before?
Juraj Ban
Yes, the answer is yes. The only thing you should consider is that you shouldn't enable extensive mode for tricky URLs like username and password because you don't want to see the password of the user logged in to your logging solution. So that was the only trick for us. We are using extensive logging, but we know the paths, specifically on the API, where you can authenticate in different ways. We don't log those parameters. We created basically also the exceptions in the log, like in the filter, don't log that, because we don't want to have any password in our logging solution.
Audience
Have you had any issues with false positives from situations where multiple clients are behind the same IP address, like behind a NAT or something?
Juraj Ban
At the beginning, we have a huge number of false positives. I mean, when we started, let's say in the beginning, when we tried Advanced WAF and ModSecurity on its own, we had a huge amount of false positives. But when we switched to the HAProxy Enterprise WAF, there were a few false positives. And, I mean, after we investigate, after we fine-tune it to our needs, after that, I think one or two clients only.
Boris Dekovic
Yeah, really little. Not much, yeah.
Audience
So, when you roll out a new application, how do you determine the baseline with usage? Like, is there, I guess, a process that you use to determine what's normal and what's not, besides just viewing the traffic? Like from a security standpoint?
Juraj Ban
We contact our product development, basically our developers, to provide us with the application's documentation. Yeah, to be honest, it's much harder with a web application than with an API because APIs are always well-documented. But yeah, with that application, it is a little bit trickier, but what we usually do, again, is extract the information and contact the development team.
Dylan Murphy
Excellent. Well, Juraj, Boris, thank you so much. Appreciate it.


