The traffic stack at LinkedIn acts as a bridge between the user device and LinkedIn Services. The aim is to provide a consistent user experience with the best possible latency for a wide spectrum of use cases. It also provides a platform for DDoS and anti-abuse defenses, authentication, security, and other common business logic applicable to all online/API traffic.
With millions of QPS, hundreds of clusters and thousands of servers to load balance, the stack needs to be highly efficient and scalable. Because of LinkedIn’s deployment infrastructure requirements, the stack needs to be highly dynamic and customizable as well.
The current stack is based on another open-source proxy with several LinkedIn customizations. In the last few years, our business along with our traffic requirements has been evolving fast. At the same time, the HTTP stack has also evolved, and we are also exploring the move to the cloud. These rapid changes in the ecosystem forced us to revisit our stack, which was built several years ago.
In this talk, you will learn about our experiments with HAProxy in the past, our current HAProxy use cases, and the plan for replacing the existing stack with HAProxy. We will also talk about our evaluation process, why HAProxy came out as a winner, and how we are planning to leverage HAProxy’s features to modernize our traffic stack which will make us better prepared for the future.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.

















Transcript

Good morning everyone, thank you for the introduction. Of the two names that I mentioned, I am Sri Ram. My colleague Sanjay couldn't be here in person he's going to be joining us virtually. We're going to talk about our recent efforts to modernize LinkedIn's traffic stack.

To give a better understanding of our motivation, we're going to give an overview about LinkedIn and about our traffic infrastructure, and the growth we had in the recent years, and how we had to scale our traffic infrastructure to keep up with the growth, and some of the challenges we ran into while we were scaling our infrastructure, and how it made us realize that we need to revisit our traffic stack, starting with our choice of proxy, and how we evaluated prospective proxies, and how we narrowed down on the proxy to redesign our traffic stack around.
Now I'm going to hand it over to Sanjay to give an overview about LinkedIn and our traffic infrastructure.
Hello, everyone. My name is Sanjay, and I work for the Traffic Infra team at LinkedIn. Traffic Infra is basically the reverse proxy workflow for all incoming LinkedIn.com requests, and I specifically work on the service discovery and load balancing aspects of the same reverse proxy workflow. So, to understand the HAProxy's evolution in LinkedIn's traffic stack, let's first try to explore what LinkedIn is and what the various business use cases and how they are tied up into LinkedIn's traffic stack.
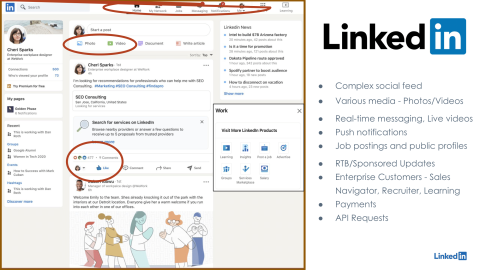
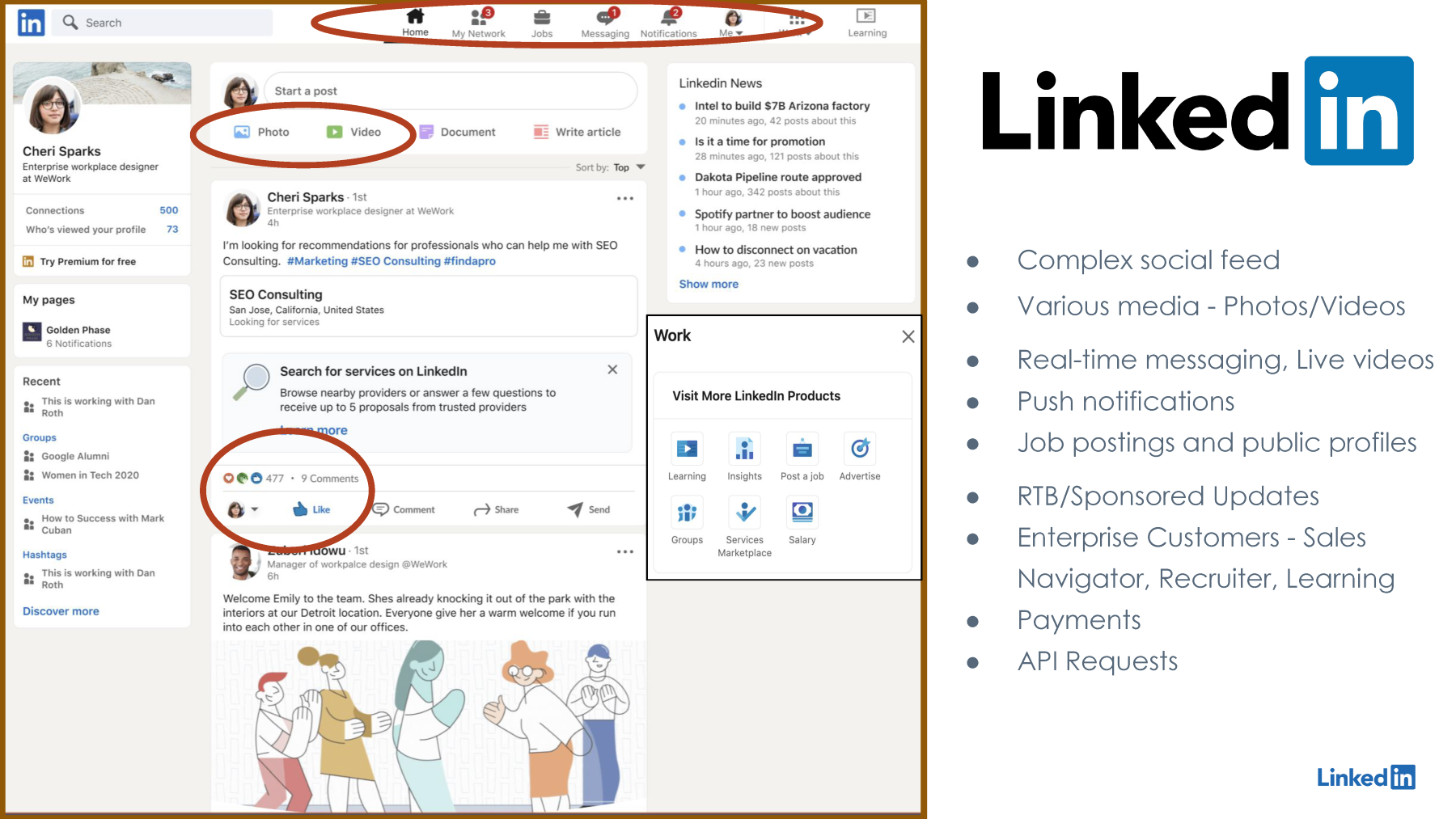
This is a sample mock for LinkedIn's feed page, and on the first impression, it looks like a complex social feed. So, if you see this feed basically consists of the various user activities that we like to call. The activities are something like likes from the users, reactions from the users, comments from the users, or it could be the post itself from the users. So, this whole feed is basically an interconnected, complex data structure of these user activities from the users' first-degree, second-degree, or even sometimes third-degree connections on the LinkedIn social feed. Now, this is handling millions of user activities in order to ingest or populate on this LinkedIn feed. So, this is handled specifically in LinkedIn's traffic stack in order to provide the best user experience, in order to render this feed within a reasonable amount of time by going through these millions of user activities. Now, we not only support text-based user updates; we support rich media as well, where we can update high-quality photos, high-quality videos, even documents, and an update as a LinkedIn post. That needs to be handled separately in the LinkedIn traffic stack because this involves a large amount of data transfer in order to ingest or publish these types of user activities. Apart from this, we also support real-time messaging, push notifications, and also live videos as well. These use cases are important and need to be handled separately in the traffic stack because they require us to handle long-port connections, long-lived connections for real-time messaging and push notifications. Also, we have support for public job postings and public profiles, and these are special to handle for LinkedIn's traffic stack because of the public endpoint. Due to this endpoint being public, we have to have special handling of member trust and anti-abuse protections around these endpoints.
So, apart from all these LinkedIn feed features, LinkedIn also has a certain set of products that are offered for certain enterprise solutions. For example, we have an ads platform which helps us to put up ads on LinkedIn. Like any other ads platform, it has strong latency requirements, it has strong resiliency requirements because it has a direct impact on the company's revenue. At the same time, we have Sales Navigator, which helps various salespeople to generate sales leads, recruiter to handle the recruitment process, LinkedIn Learning to help with the skill uplifting of the members. These are special enterprise products and need to be handled specifically in the traffic stack because of the strong consistency requirements around the payments workflow. At the same time, these also support login from multiple users under the same account for these enterprise solutions. We have to handle the strong consistency across those multiple users because they are under the same account and they are not being under the same account.
Apart from that, we have API requests as well, which are handled separately in the traffic stack. APIs are basically the endpoints which are exposed by LinkedIn, which are accessed by our partners in order to gain access to LinkedIn's data in a GDPR-compliant manner.
So now that we understand what the various business use cases for LinkedIn are, let's take a look at LinkedIn's Traffic Infra stack and try to understand how these fit into the business requirements.
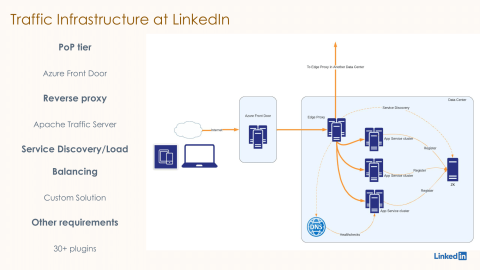
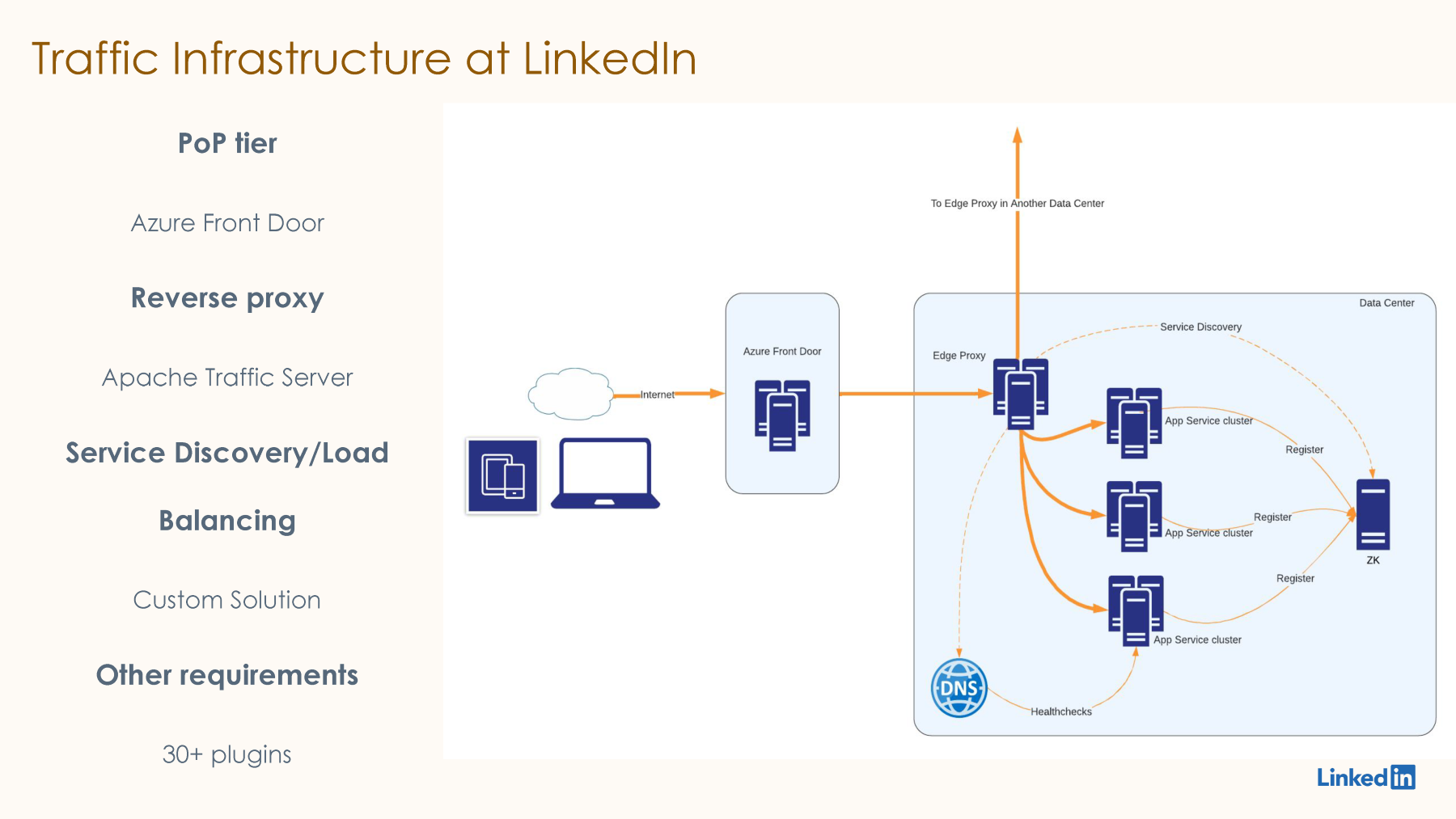
So, this is how it looks like on a very high level. The traffic infrastructure at LinkedIn is basically Azure Front Door as our PoP tier, which is responsible for receiving the requests from the internet. Then it forwards the request to one of our data centers, one of LinkedIn's data centers, and within the data center, the request is first received by our Edge proxy, which is currently based on Apache Traffic Server, also called ATS. ATS runs 30+ custom plugins that we have written in order to support the various business needs that we talked about earlier in the previous slide. After running these 30+ plugins, it forwards the request to one of the application servers in the same data center or sometimes in a different data center as well. In order to do this discovery and load balancing of these application servers, we have also written a custom solution for service discovery and load balancing in the same reverse proxy workflow. This custom solution is based on a combination of service registry like Zookeeper and DNS-based health checks.
This architecture is currently deployed in multiple LinkedIn data centers. This reverse proxy workflow fronts hundreds of thousands of servers. There are thousands of microservices behind this reverse proxy workflow, and we are handling around millions of QPS currently using the same architecture.
So, the question is, do we need to change this architecture in any way since it's already doing well? Of course, yes, because the business requirements are changing very rapidly, and at the same time, the industry has been also moving and technological advancements have been happening in the industry.

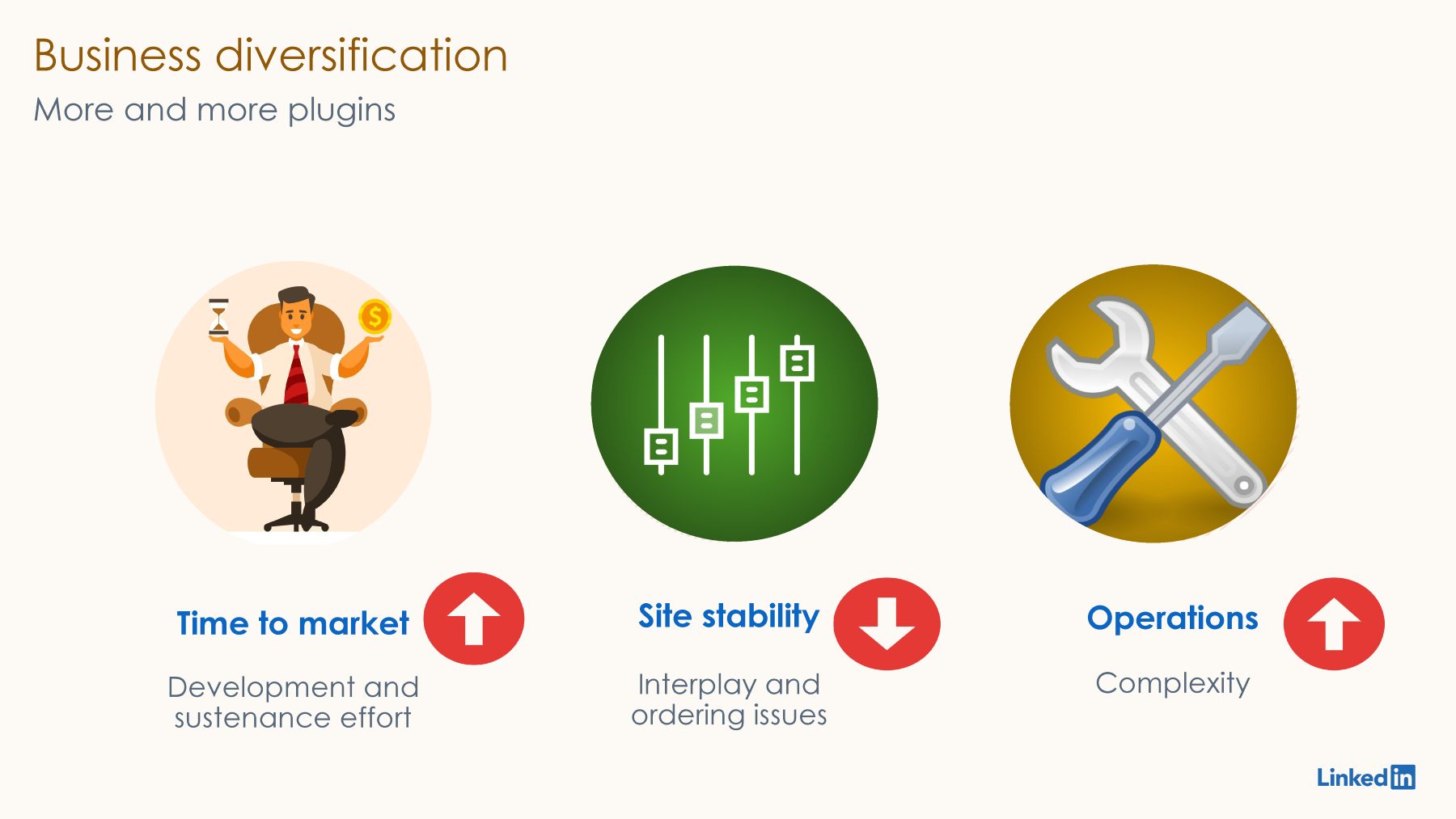
Let's take a look at the major drivers of change across LinkedIn's traffic stack. The first one is, of course, the organic growth of LinkedIn itself. We are already doing millions of QPS, but our member base has been increasing very rapidly, which is leading to more QPS, which means we have to add more servers at some point. That translates into more microservices behind this reverse proxy, and eventually, the reverse proxy has to scale up and scale out according to the projected site QPS growth. We have to keep up with the site QPS pace. The next driver has been the business diversification of LinkedIn itself. LinkedIn as a product is coming up with new requirements, like there are new enterprise solutions that are being built up and will be offered as a separate product. Then there are changes around the geo-specific requirements; for example, for Europe, for China, we have a separate specific set of custom requirements to be processed across the traffic stack. We have been getting custom requirements from our ads platform as well, where the site QPS requirements are bumping up very unevenly. There are certain bumps because of a large client being onboarded on our ads platform.
Last but not the least, the driver of change has been the technological advancements happening in the industry. We are already seeing that there has been adoption going on for HTTP/2. HTTP/3 has been being adopted, and we are moving towards QUIC, GraphQL, and gRPC. All these modern features are coming up. This is also important for LinkedIn's traffic stack because we need to keep up with the pace of the industry, and we have to be ready for all these modern features. The stack needs to evolve or be updated in order to support these modern technological features.
Now I'll hand it over to my colleague Sri Ram who will talk about the various strategies we have been doing around for these major drivers, what are the various challenges that are coming up, and how we are overcoming those challenges in order to satisfy these major drivers.
Thank you.
Yeah, thank you, Sanjay.

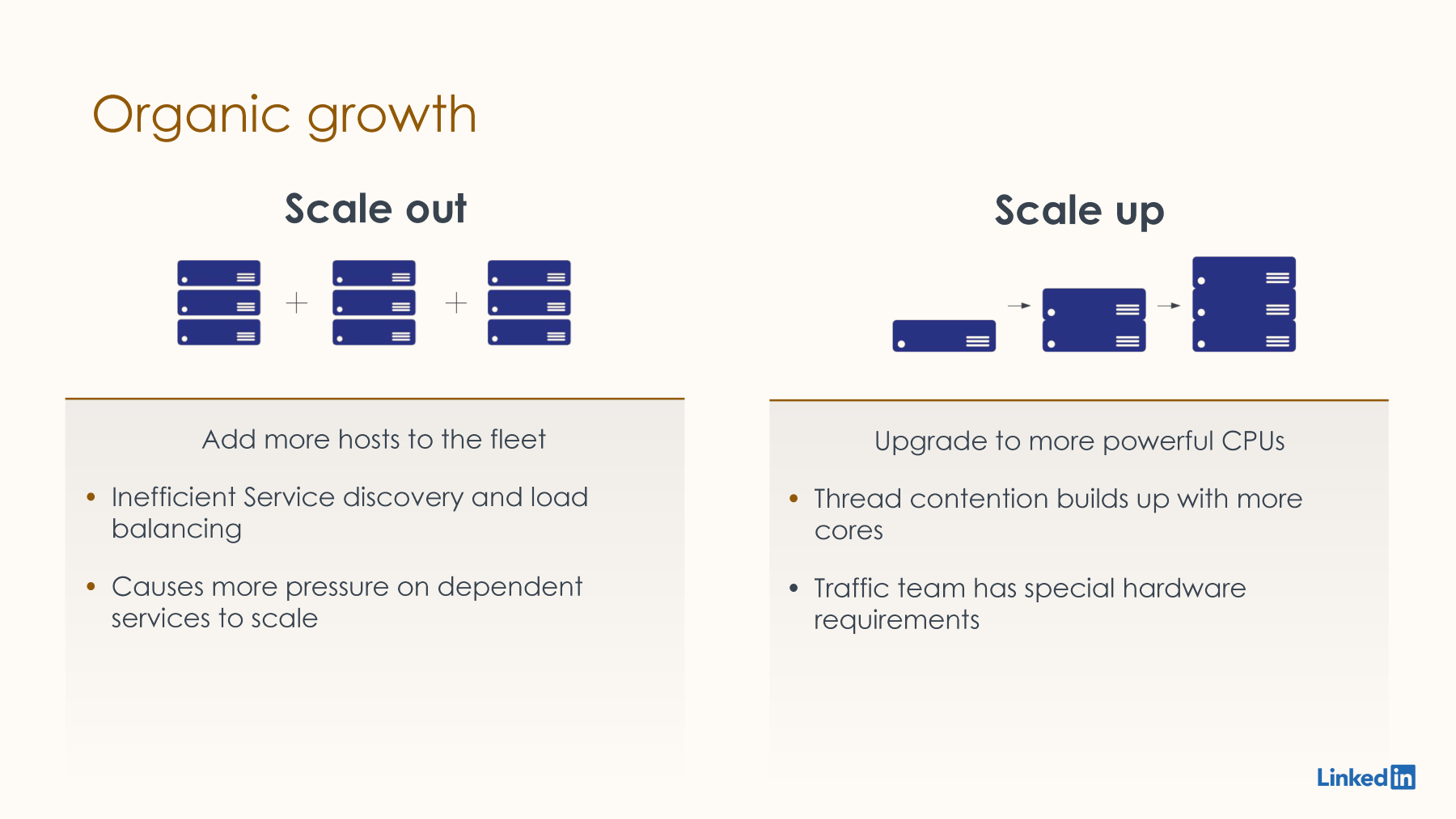
Let me dive deeper into some of the drivers that Sanjay just mentioned, starting with organic growth. We've seen an increase in the number of active users and, consequently the QPS on the site. How do we handle this? We scaled our fleet horizontally, but that came with its challenges. One challenge with scaling our fleet horizontally is it cannot be done in isolation. It has a cascading effect, so we need to find all the services we depend on and scale them appropriately; otherwise, the bottleneck just shifts to another spot.
Other than the effort of scaling horizontally and the cost involved, the other challenge is some of the features that we added before the growth, for example, passive health checks, are becoming less and less effective because now we need more traffic for the proxy layer to figure out that one of the downstream services' server is not behaving as expected. Along with scaling our fleet horizontally from time to time, we also upgrade our hardware. Recently, we upgraded to AMD 64-core machines, but we didn't get the expected performance out of it. We had to tweak Traffic Server quite a bit to make it work on these machines, but we didn't see the results we were expecting. We were only able to bring down our fleet size by, let's say, 12%
As a result, we cannot keep scaling our fleet horizontally indefinitely. We think that traffic infrastructure could become a bottleneck for growth in the future because of performance limitations of our current proxy.

Along with the increasing QPS, we've also seen an increase in feature requests from our application team. For example, route differently or perform a certain action based on the geolocation of the request, or do some different action or route differently based on some request metadata, for example, user agent, client IP, or some custom cookie that we have in LinkedIn. We need to keep evolving our anti-abuse protections from time to time, keep improving our data center failover mechanisms, and keep adding more authentication mechanisms.
So, how do we keep adding these features and keeping up with the feature requests? We can extend Apache Traffic Server. The way to do it is by adding custom plugins. We kept doing that from time to time to address our feature requests, but the challenge with doing this is, over the years, as Sanjay mentioned, we have 30 plus plugins now. Adding more plugins is time-consuming and more complex because now we have to worry about how it's going to interplay with the plugins already existing and ordering issues, etc.
Another challenge is these plugins are shared libraries, so we don't get very good fault isolation. Because of the complexity, in case we introduce a bug, we end up bringing down the entire proxy and cause unavailability to the site. So, as a result, we see that traffic infrastructure could become a bottleneck because we lack native constructs to capture our routing requirements, and writing plugins is going to take some time.

Along with these custom feature requests, we also keep getting requests from our application teams for the next generation of network protocols and frameworks such as HTTP/2, gRPC, HTTP/3. The problem in supporting these features is these features are not yet supported in our upstream, and it is a very high investment to try to build them in-house, and it would take a very long time. As a result, our traffic infrastructure can soon become a bottleneck for developing the next generation of applications at LinkedIn.

Due to all these limitations, we've decided to redesign our traffic stack around an alternative reverse proxy. How did we go about our proxy exploration? To begin with, we created a wish list. We want the next prospective proxy to be open source and to have a very strong open-source community. Of course, it has to be very performant. It should be able to handle the scale at LinkedIn. We wanted to have some very rich constructs to model our routing and requirements so that we can minimize the amount of custom code we need to write and maintain. We will have some custom logic, so we want well-defined extension points to add our custom logic and also have very good fault isolation there. We want it to support the modern network protocols and frameworks to support the next generation of applications at LinkedIn.

Yeah, so we started off with evaluating the top proxies in the industry. We looked at Zuul, a Java-based reverse proxy. The reason we looked at this is because LinkedIn is predominantly a Java shop, and we have a lot of tooling and infrastructure for Java applications. Currently, we are a C/C++ application and we get very limited support from our tooling and infrastructure. If you have a tooling issue, we are on our own, trying to solve it by ourselves. So, this was attractive because we could get some of the features with respect to service discovery for free since we already have that for Java applications.
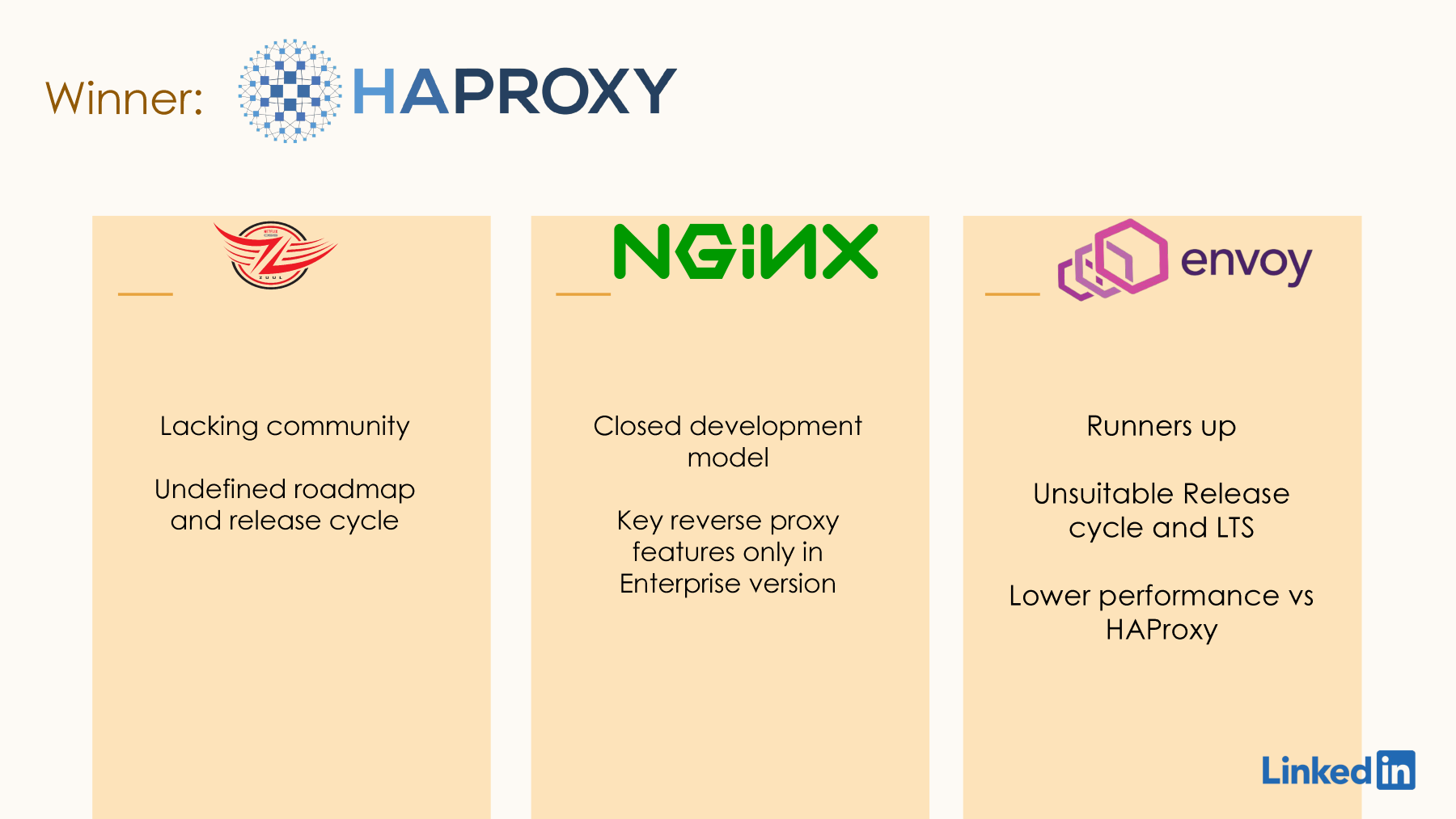
Why didn't we go along with Zuul? It didn't check off a lot of things on our wishlist. For example, it didn't have a strong open-source community, a clear roadmap on a release cycle, support for the next-generation protocols and frameworks we were looking at, and it was not as performant compared to the other proxies on our list. For this reason, we dropped Zuul pretty early in the race.
We also looked at Nginx. Nginx looked promising; it was performant, had a good open-source community, and we had people at LinkedIn already with some hands-on experience with their web server and proxy. So, what were the limitations? Why did we not pick Nginx? One of the cons for Nginx was their development model. We felt that all the features were in the Enterprise version, and we didn't see a clear roadmap on when they would be ported to the open-source version. Also, we saw that some of the key reverse proxy features were only available in the Enterprise version, for example, some advanced logging features, connection sharing, and configuration via API. These were something we were looking for in the next proxy, and these were only available in the Enterprise version. For that reason, we continued looking.
The next one we were interested in was Envoy. To be honest, Envoy was the front runner when we started off our search. It is performant, had a good open-source community, and we had a couple of teams at LinkedIn already using Envoy. It is already deployed at scale in the industry with companies of similar scale. So, why did we not pick Envoy? Parallelly, we were also looking at HAProxy, and HAProxy did all this and did it better than Envoy. Another thing was their release cycle, which didn't really suit the way we do things at LinkedIn. They had a major release every quarter and long-term support for 12 months for each release. What that would mean for us is they could have a backward compatibility-breaking change every quarter, and we would be forced to keep upgrading more frequently. That would mean we would take the focus from developing our features to focus more on upgrade activities. For that reason, and also because HAProxy was better on the wishlist we were looking at, we decided to pass on Envoy and select HAProxy.

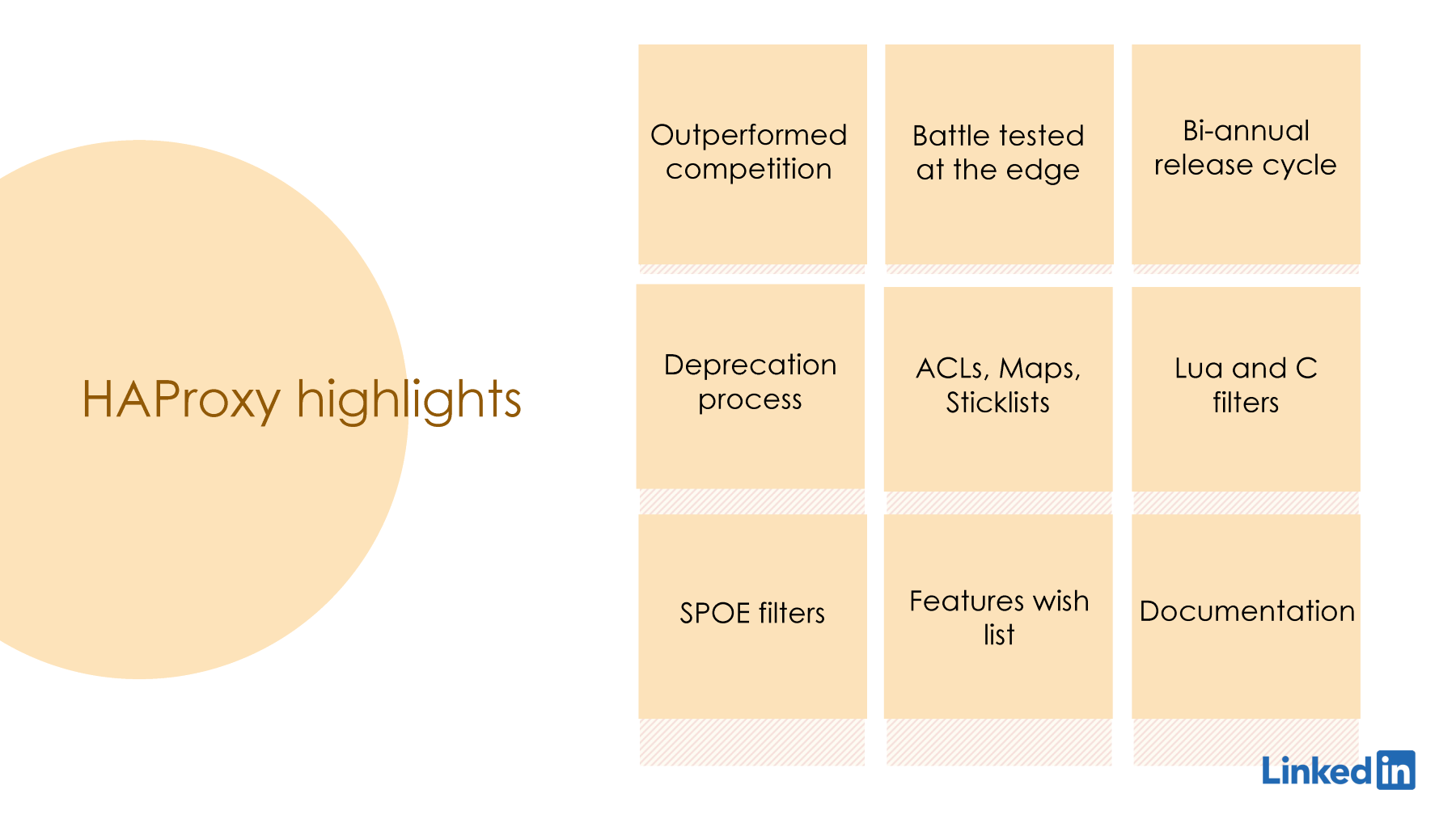
Now, let me go over the highlights of HAProxy and why we love HAProxy. One, it is performant; it outperforms the competition by a big margin, and it is open source with a very strong community. It is battle-tested at the edge in companies with similar scale, so that was another big plus for us to make the effort to redesign and go to a new proxy. We also spoke to some of our sister companies who use HAProxy, and they had good things to say about their experience. We also like HAProxy's release cycle and the long-term support. It suits our model; we can find the balance of developing our business logic and also focus on operational activities. We don't have to worry about backward compatibility-breaking changes in immediate releases, so that's another plus.
We also like the rich native constructs that we can use to model our LinkedIn routing requirements, and the extension points. We've tried creating some prototypes using Lua, and it was very straightforward. It gave us the fault isolation that we're looking for, which was very important for us. We also got our hands dirty by going and changing some of the C code to add our custom converters, actions, and features in case we want more performance. This was an option for us, and we were able to do it pretty easily.
Next, the SPOA filters; this is a very good feature for us. We plan to implement some of our anti-abuse functionality using SPOA filters, basically create a very good contract, offload some of this processing outside the proxy, give it the information it requires, and in response, we get like okay, allow or deny, or some friction. So, we can move all this to another agent. In case something goes wrong there, our core proxy still is available. Another good thing we see is we are covered for the future. They already support some of the modern network protocols and features that we were looking for and the requests our application teams are requesting, so that was another plus. Last but not least, documentation. It is very well documented, and there's a lot of material that we can find online. This is very important for us because we are onboarding the entire traffic team and the SRE team to a new proxy, and this would help onboard faster.

Now, let me go over some of the functional prototypes that we did with HAProxy. What we were trying to achieve by these functional prototypes was to capture all our routing requirements, see how it would look in HAProxy, if it can handle our scale, and how it looks? Using all these native constructs can minimized the amount of code that you're writing and yeah, we have some requirements where we fetch some data which we use for routing, but we fetch it from another service. Like, how that would look like in HAProxy.

Yeah, one, okay, starting with the route volume. Currently, let's say we have five parts that get routed to the same front end. The way we do it in Apache Traffic Server is we, for every path that we want to route, we create a rule. So, as a result, you can guess we have a very high rule volume. We currently have 16,000 rules. It gets complex, it adds complexity during operations. So, let's say we need to add some custom feature for everything that's going to that front end. So, those plugins have to be added to multiple rules. So, let's see how that would look like in HAProxy. So, HAProxy has a very good feature where I can fetch a pattern from a file and apply it to a rule. So, that pretty much brings down the number of rules we have to 250. That's pretty much the number of backends that we have.
So, this would make our operations very simple. This is how we think like, any traffic going to this front end, do this extra logic. So, I only have to change that one rule instead of changing it in multiple places. Yeah, so this is how simple it would look in HAProxy.

Next, we're looking at some of the custom code that we have and see how we can capture the same thing using the native constructs in HAProxy. So, currently in ATS, we can only route based on domain and path. Any other way of routing, we need to add a custom plugin. Compared to that, in HAProxy we can just write an ACL. Let's say I want to route using some special cookie, write an ACL for it. Now, if I want to do something different for a mobile user, an ACL just looks at the user agent, compiles it with a set of user agents that I can fetch from a file. Very easy, my file looks very simple and is just captured in one ACL line.
Do something for a request coming from a certain geolocation. Yeah, that's also an ACL.
Yeah, and yes, so we have some, as I mentioned before, we have some requirements where we make routing decisions based on information we fetch from another service. So, how do we do that in, how can we do that in HAProxy? Let me give an example to better understand this example. So, we have a feature called member sticky routing. So, what we want to do is to achieve read after write consistency for a member. We want to consistently route the member to the same data center. So, the way we do it is we do some offline analysis to figure out which is the best data center to route a member to. One of the criteria is the location, we want to route them to the closest data center, but that is not the only criteria. So, once we've done the calculation, then we upload the data to a service, and that has the mapping between the member and the data center.
So, we actually don't query the service for every request. We use a routing cookie to cache this information, so we keep routing to the same data center. But yeah, we do data center failovers, load testing, so from time to time we want to route the user to another data center. So, we need to query the service to figure out which is the best secondary data center to route it to. So, we implemented all this logic with a simple Lua script and a fetcher in Lua and yeah, just this one line, fetch the data center for this member, and if for some reason we're not able to reach the service, by default route it to the best data center, and yeah, we were able to capture this in two lines in our config.

Next, so we also did some prototyping for the next generation network protocols and features to get the hang of config, how the config would look like. We also validated HAProxy support for H2, gRPC, and WebSockets. Yeah, we were able to find a lot of information online and we were able to achieve it pretty straightforward.

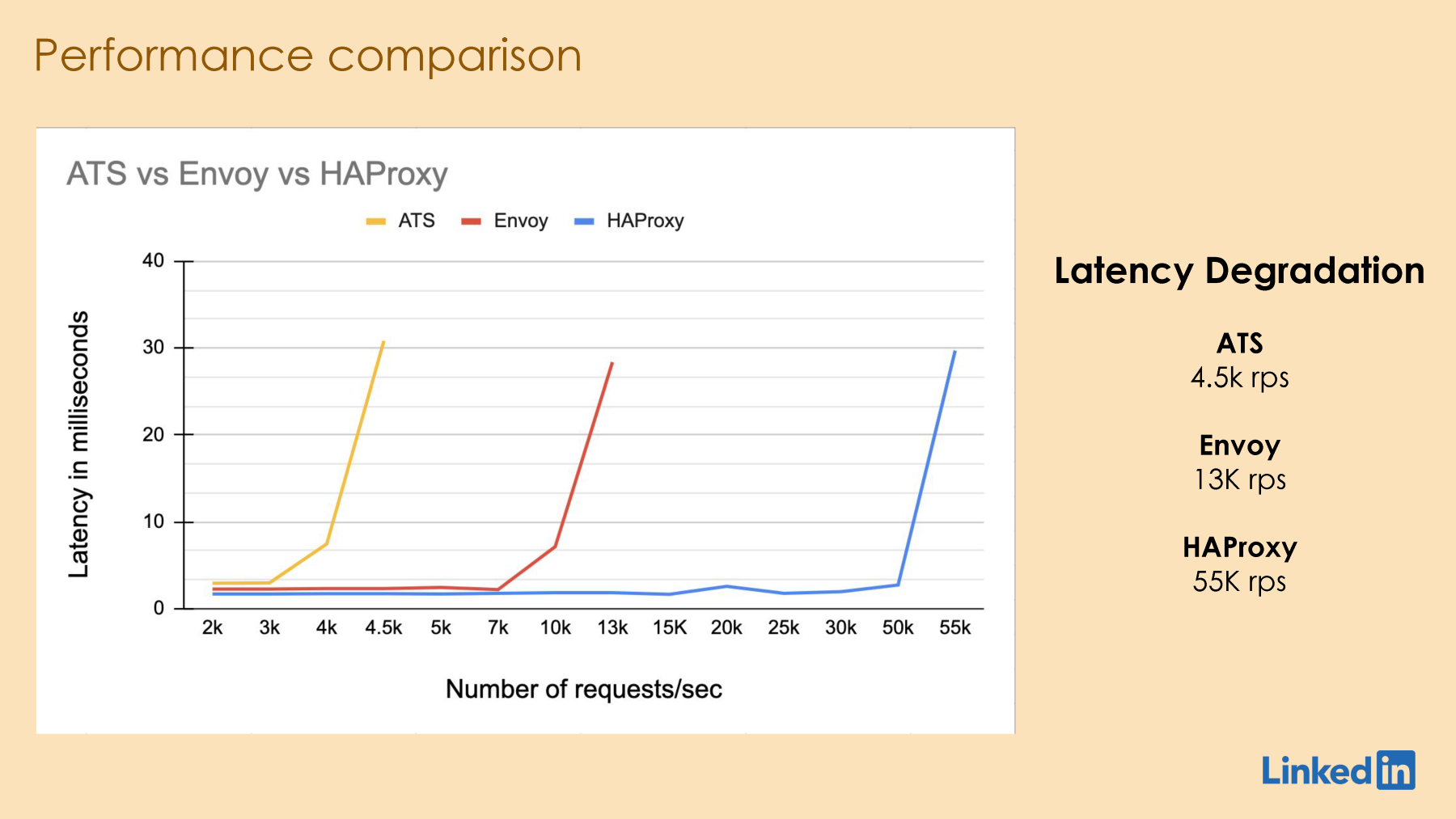
Yeah, we also did some benchmarking to get a taste of HAProxy's performance. Not at the same level as the blog that had the 2 million requests per second, but yeah, to some level. So, the methodology we used, what we're trying to measure is the end-to-end average latency.

Now, the procedure we used is we kept increasing the requests per second until the latency went over 10 milliseconds. The tools we used were similar to what was used in the benchmarking for the 2 million. We used WRK2, and for the backend, we used HTTPTerm. We ran it on a pretty low-end server and we dedicated four cores to the proxy and four cores for the client and the backend. Now, we also added a 1KB payload in the response and a delay of one millisecond to kind of simulate a server.

Yeah, as you can see, HAProxy outperformed the competition by a big margin. We saw the latency go above 10 milliseconds pretty quickly in ATS at 4.5k requests per second. On NGINX, we started hitting the limit at 13k requests per second. In HAProxy, we kept going, and at 55,000 requests per second, that's when we saw the latency go over 10 milliseconds.
I'm sure it can be tuned further to do much more than this, but for the purpose of our observation, yeah, this was good.
So, in conclusion, yeah, we love HAProxy. It checks off all the items on our wish list. It is very performant. We anticipate that it's going to drastically reduce our fleet size and get a lot of gains in performance, cost, and the amount of effort required to manage our fleet. Because of the native constructs, it is going to help capture our routing requirements very easily and kind of minimize the amount of code we need to write and deliver features faster and not become a bottleneck for our future application teams. We are covered for the future because it has all the next generation protocols and frameworks that we're looking for.
So, what's next? We are currently working on the redesign. We are creating an MVP using HAProxy with very minimal features and we plan to go into production sometime in the next quarter or two. Once it is there, we get much more hands-on experience on how to operate HAProxy and we start migrating features one by one and slowly increase the number of features in HAProxy.
That's all we have for today. Let us know if you have any questions.
Thanks. So, we should have Sanjay joining us as well. So, Sanjay, are you able to hear us? Sanjay, thank you for joining us. You have the distinction of being much larger than everyone else in the room. So, as a reminder to everyone in the audience, if you have a question, please raise your hand nice and high. One of our speaker runners, either the microphone runners on either side, will bring the microphone around to you. So, don't be shy if you'd like to ask these gentlemen any questions. Please do. As a reminder for everyone online in the stream chat, you can submit any questions and also on Twitter if you hashtag #HAProxyConf. Our team is on the lookout and will feed me the questions. We did have a few that came in during the talk, so I'll start there.
So, at the top of your list for a load balancer was it had to be open source. Is this true for LinkedIn as a whole? What is it that you love about open source? It's free. What I meant was, yeah, reliability, especially from the edge perspective. The advantage I see is reliability. Whatever we can find, we fix it. What we don't know, we don't know. So, basically, we'll be extending our team to the community and have some experts find issues before we can and fix them for us. And yeah, also going back to your question, LinkedIn is also big into open source. We've been giving back to the community. A good example would be Kafka and the reliability of Kafka has gone up considerably after we made it open source. So, yeah, we believe it will help us and we can also help.
Yeah, Sanjay, do you have anything to add to that question? Is there anything you know? What is it that you love about open source and what is LinkedIn as a whole? You know, what is LinkedIn's relationship as a whole with open source? Yeah, I think Sriram summed it very well. I don't have much to add, but yeah, like he said, I agree on the reliability part. There are multiple eyes looking at the same code. It becomes much more reliable and then, at the same time, we can focus on the other product side of things where LinkedIn, as a product company, wants to build products which are providing great user experience and we can worry less about the other stuff. So, I think going open source is like...
Thank you, we have a question in the audience. Thank you very much. Looking at your scalability issues, it was not clear to me that your data centers are on premises by your own. Did you consider moving to the cloud? Yes, currently, you're right. We are on-premise data centers. We considered, in the recent past, to move to Azure, but we put it on hold for now. So, for the next couple of years, we're going to still be on-premise.
We have another question from the online audience. Let's see, does LinkedIn want to use the commercial offering or the community version? For now, all the features we need are in the open source version, but we see, at least during the conference, I've learned some of the good features in the enterprise version, so we'll go back and evaluate. Yeah, no decision yet.
And there's another one online. So, Sanjay, maybe we can start with you on this. You said that a requirement to support HTTP/2, HTTP/3, and gRPC. Does your team always stay on the cutting edge? And maybe, can you expand upon that, the desire to use the latest and greatest available? Yeah, definitely.
Like I said, our main focus is to provide a great user experience, like the best user experience possible for us. Given that, the new features that are being built, at least the promise is, it will give you more flexibility in terms of the user experience or there would be a better latency or there would be... hundreds of these kinds of features are being built in the industry. So, as a team culture, we also like to be updated and we also like to experiment with the pace of the industry and make sure that we are able to provide whatever is best available out there. So, that's why we have a separate focus on all these new modern features that are coming up. It's not just the traffic team, but it's LinkedIn as a whole company. So, we like to keep ourselves updated and at least be able to experiment and be able to establish a theory where we can either accept or reject. We should be in that place.
And Sri Ram, if you have anything to add about the choices with any of these cutting edge technologies? Yeah, like Sanjay pointed out, one of the values at LinkedIn is members come first. If we can improve the member experience somehow by using these new features, we want to use them. Let's say using gRPC, if we can provide a good experience for a region which has a slow internet connection, then we want to use it if we can do it reliably. If we can improve the latency by using H3 reliably, then we want to do it. Yeah, why not? Yeah.
Excellent. Well, that's all the time that we have for questions. Sri Ram and Sanjay, thank you so much. Sanjay, I'm so thrilled that you were able to join us, and thank you so much for your talk. Thanks.

