
How do you connect thousands of applications across multiple cloud providers when they all share the same IP address space? This was the complex challenge facing PayPal's engineering team as the company grew through acquisitions and expanded its hybrid, multi-cloud infrastructure. With business units spread across AWS, Google Cloud Platform, and Azure—all using overlapping 10.0.0.0/8 IP ranges—traditional networking solutions simply couldn't provide the secure, low-latency connectivity required for PayPal's global scale.
In this HAProxy Conference session, Kalaiyarasan Manoharan, Senior Staff Network Engineer at PayPal, and Siddhartha Mukkamala share how they solved this problem by building Meridian—a unified connectivity fabric powered by HAProxy. Their solution not only resolved the IP overlap issue but also delivered a 24% latency reduction while enhancing security and observability across PayPal's 3,500+ applications.
You'll discover how PayPal leveraged HAProxy's multi-tenant capabilities to create seamless connectivity between business units, implemented innovative traffic routing using domain names and URI paths, and built a self-service model that dramatically simplified application onboarding. This real-world case study demonstrates how the right architecture can transform complex multi-cloud networking challenges into streamlined, scalable solutions.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.














Kalaiyarasan Manoharan
My name is Kalai. I'm a Senior Staff Network Engineer at PayPal. Today, we're going to talk about building bridges across the public cloud. It's the PayPal way: how we solved the business challenge we ran into by using HAProxy.
I'm partnering with Sid, who will give us some background about PayPal's global infrastructure and the challenges we face today. Then, I'll discuss the solution, and we'll discuss the results and the closing thoughts further. Over to you, Sid.

Siddhartha Mukkamala
Thanks, Kalai. Good afternoon, everyone. My name is Sid.
This is the agenda that we'll talk through. We'll talk about PayPal's global footprint, the challenges that we ran into, and the solution we came up with, some results, and then the closing thoughts.

Before we go into the technical details, I want to give you a quick overview of who we are and the scale we operate at. PayPal was founded in 1999. We started as a simple online payment platform, but then we evolved into one of the most trusted financial institutions in the world.
We have a number of business units. You might know all these already.
Venmo is a social peer-to-peer payment platform.
Xoom provides international remittances.
Zettle provides a POS solution for small businesses and supports in-store payment options.
Honey provides digital rewards and shopping tools.
Braintree provides payment processing for businesses.
HyperWallet provides a mass payout option for businesses.
And finally, PayPal Credit provides financial options for consumers.
We currently have 436 million active accounts or users on the platform, operate in 200+ countries, and processed $1.6 trillion in total payments last year. To support all this, we need a global presence and a global, scalable infrastructure to serve our customers.
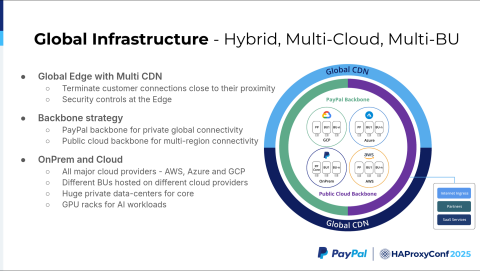
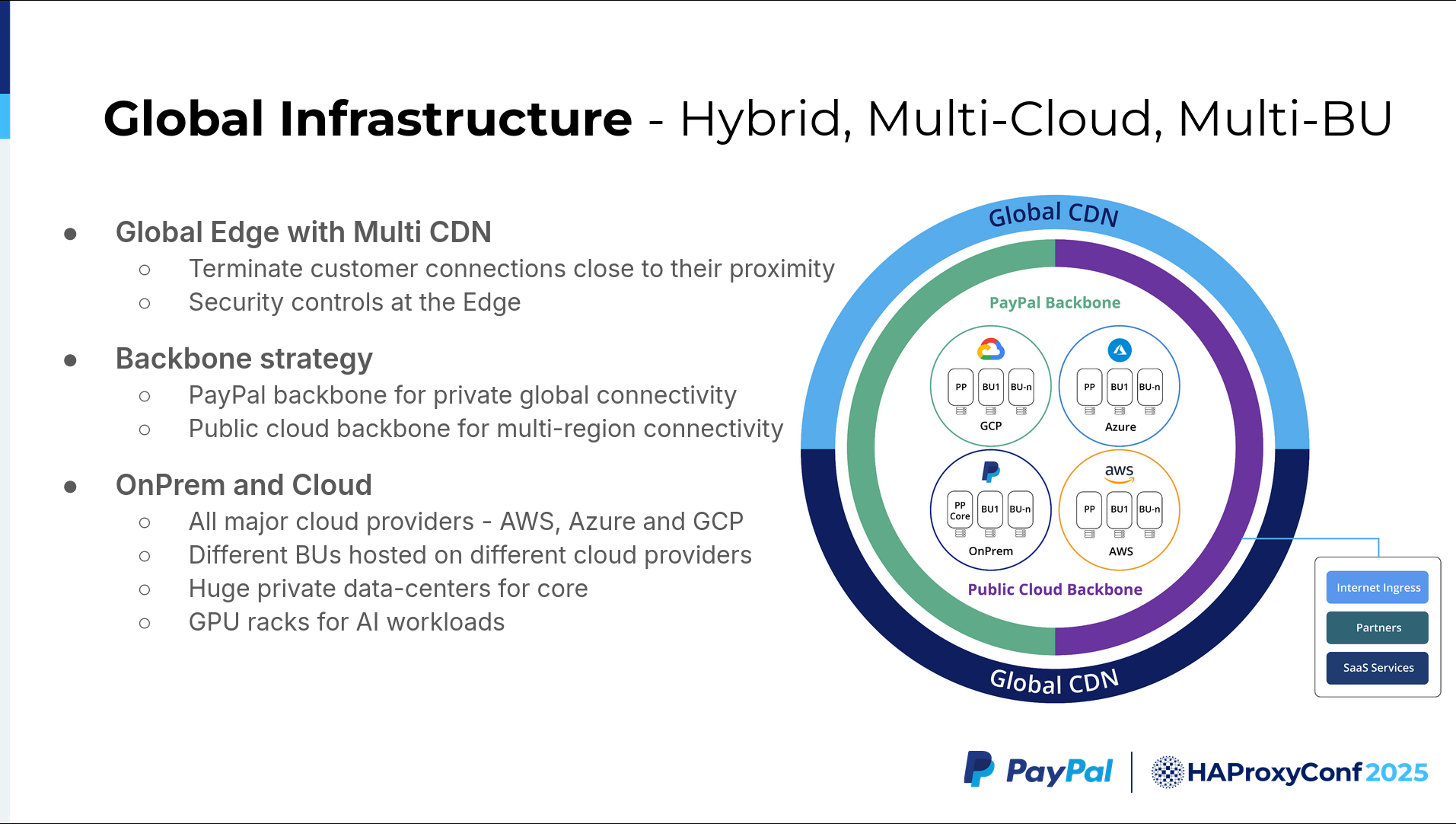
PayPal operates a hybrid, multi-cloud infrastructure built on a three-tier architecture with global edge distribution. The company distributes its infrastructure globally using multiple CDN providers, which terminate customer connections close to their location. This approach reduces latency and delivers better performance for customers. PayPal also implements security controls at the edge to stop malicious traffic before it enters the core network.
PayPal uses a hybrid backbone strategy. The company owns its private backbone, which provides connectivity between data centers and Points of Presence (PoPs) across the globe. This backbone also serves as an on-ramp to public cloud providers through Google Cloud Platform interconnects, Amazon Web Services Direct Connects, and Azure ExpressRoute connections.
The company also leverages a public cloud backbone infrastructure. For multi-region communication between cloud regions, PayPal uses the cloud provider backbone rather than routing traffic back to on-premises infrastructure. This strategy helps gain latency benefits.
For compute and services, PayPal maintains a large on-premises presence while also operating in GCP, Azure, and AWS. Business units are distributed across all three cloud providers.
This hybrid, multi-cloud infrastructure provides PayPal with global reach and resiliency. However, it also introduces complexity. The company must manage multiple cloud providers and determine how to connect all business units together across this distributed environment.

PayPal faces several core challenges today. One of the core challenges that PayPal faces is because of acquisitions. Before the acquisitions, all of these entities were independent platforms. They didn't need to talk to each other before. But after the acquisition, as we started to integrate the services, as we started to make them talk to each other, we discovered that all the organizations used the RFC 1918 IP address space. They all used 10.0.0.0/8. So it's an issue to make them talk to each other with that overlapping IP space.
There's no easy way to expose the services between the entities without going over the Internet, but going over the Internet would degrade application performance.
So with business units spread across multiple cloud providers—let's say we have the payments API in Amazon Web Services, which wants to talk to the risk API in Google Cloud Platform, then wants to talk to a compliance API in Azure. It's very hard, from the latency perspective, to achieve all that.
Also, we have limited visibility into the flows. If something happens, there is no single pane of glass to see the traffic flow end-to-end. It's hard to detect what went wrong since you don't have the end-to-end visibility of the flow.
Finally, the standards across public cloud providers differ. With each provider, everyone enables things differently. AWS has PrivateLink, GCP has PSC. They are different, so it's hard to have that uniform deployment across the providers.
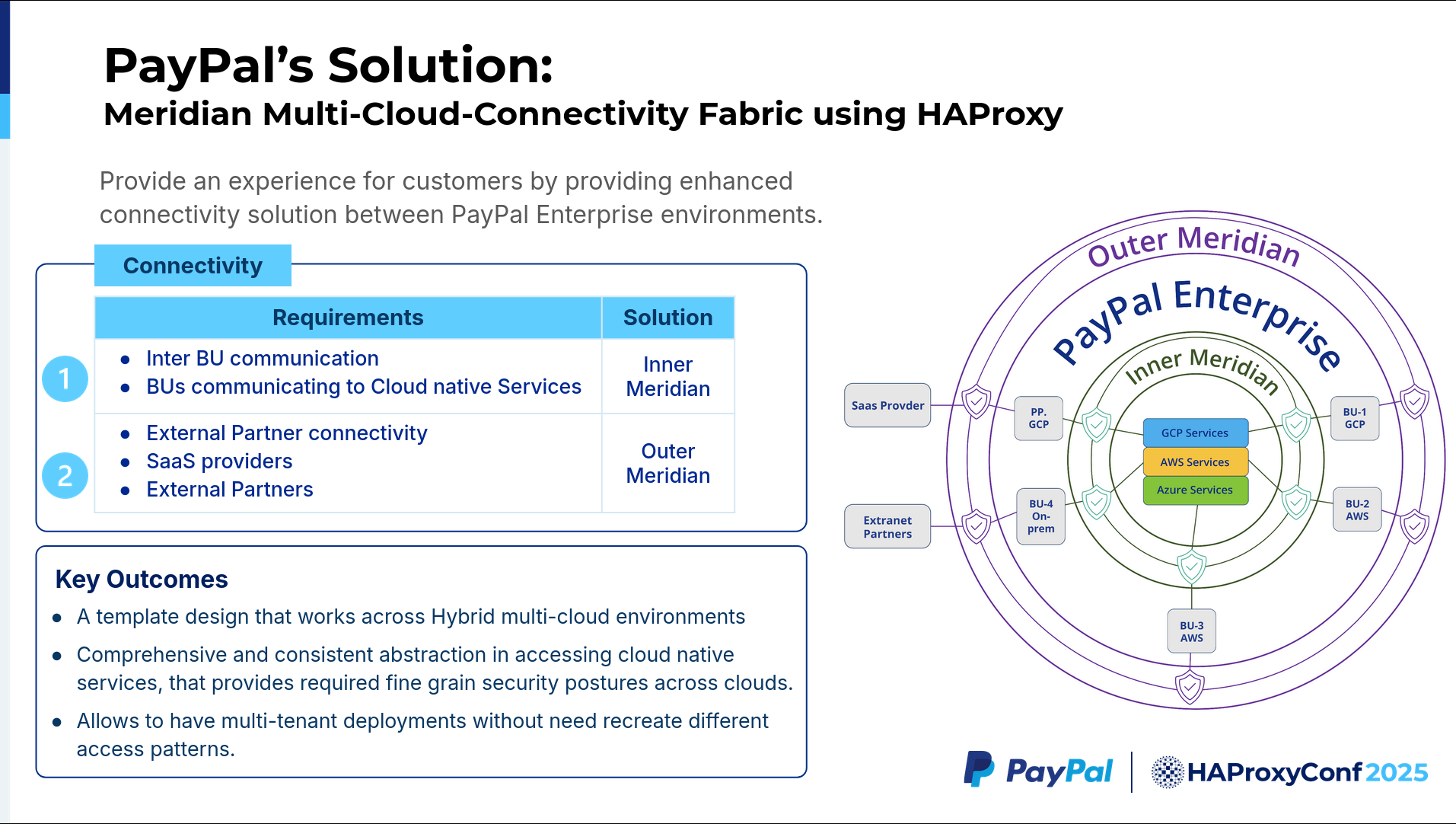
Given the complexity and scale of our hybrid, multi-cloud environment, we actually wanted to have a reusable solution that can abstract the complexity of the cloud providers. That's where Meridian comes in.
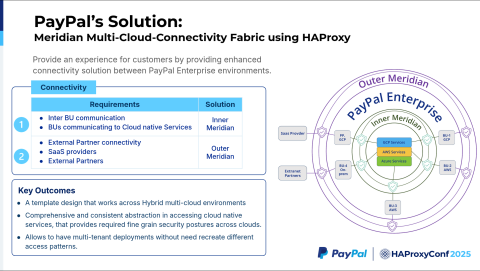
Meridian is the name of a project within our company that refers to a hybrid, multi-cloud connectivity fabric providing a unified and straightforward solution for the business units to talk between themselves. We started Meridian using public cloud providers' native services like AWS PrivateLink and GCP PSC. But soon, we realized we were spread across multiple cloud providers. Our business units are across cloud providers. We are on-premises. We soon hit a roadblock, figuring out a uniform solution across all the cloud providers. So that's where HAProxy comes in.
We leveraged HAProxy as the core component of our solution. HAProxy provided a unified, multi-tenant solution without reinventing an access pattern for each cloud provider.
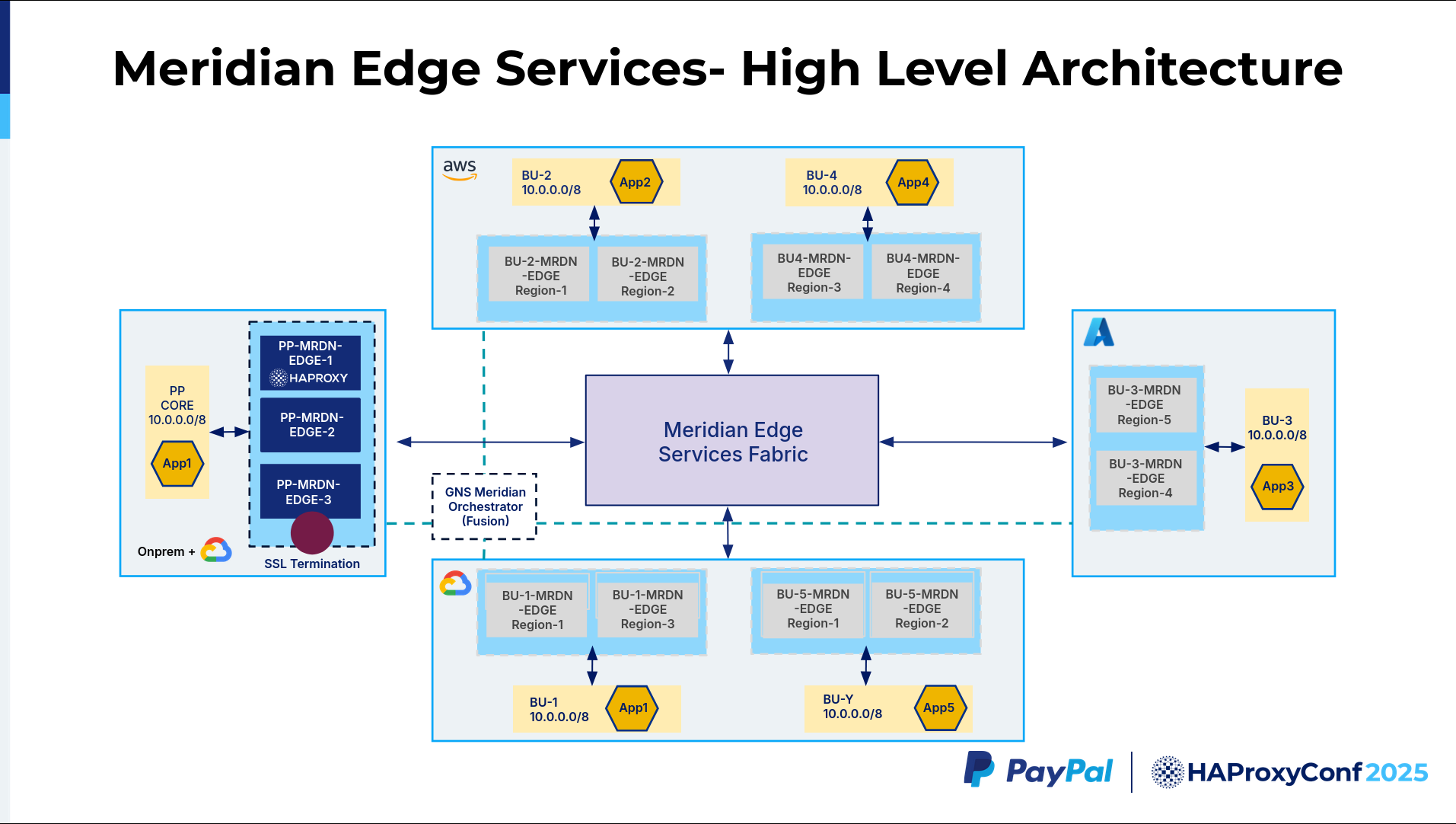
This is the high-level Meridian architecture. As you can see, we have two layers in Meridian. The inner layer of the circle we call Inner Meridian, and the outer layer is Outer Meridian. Inner Meridian provides connectivity between the business units. If one business unit wants to talk to the other one, it uses the Inner Meridian layer. If a business unit wants to talk to any of the cloud services, like AWS LLM or GCP LLMs, it uses Inner Meridian.
Outer Meridian provides connectivity for the business units in PayPal to talk to the external companies, the SaaS providers, or the partners. As I said before, HAProxy provides us with a multi-tenant solution across the cloud providers.
Next, we'll go into the solution. Kalai will take you through it.
Kalaiyarasan Manoharan
Thank you, Sid, for giving us a quick background on the complexities and the solution.
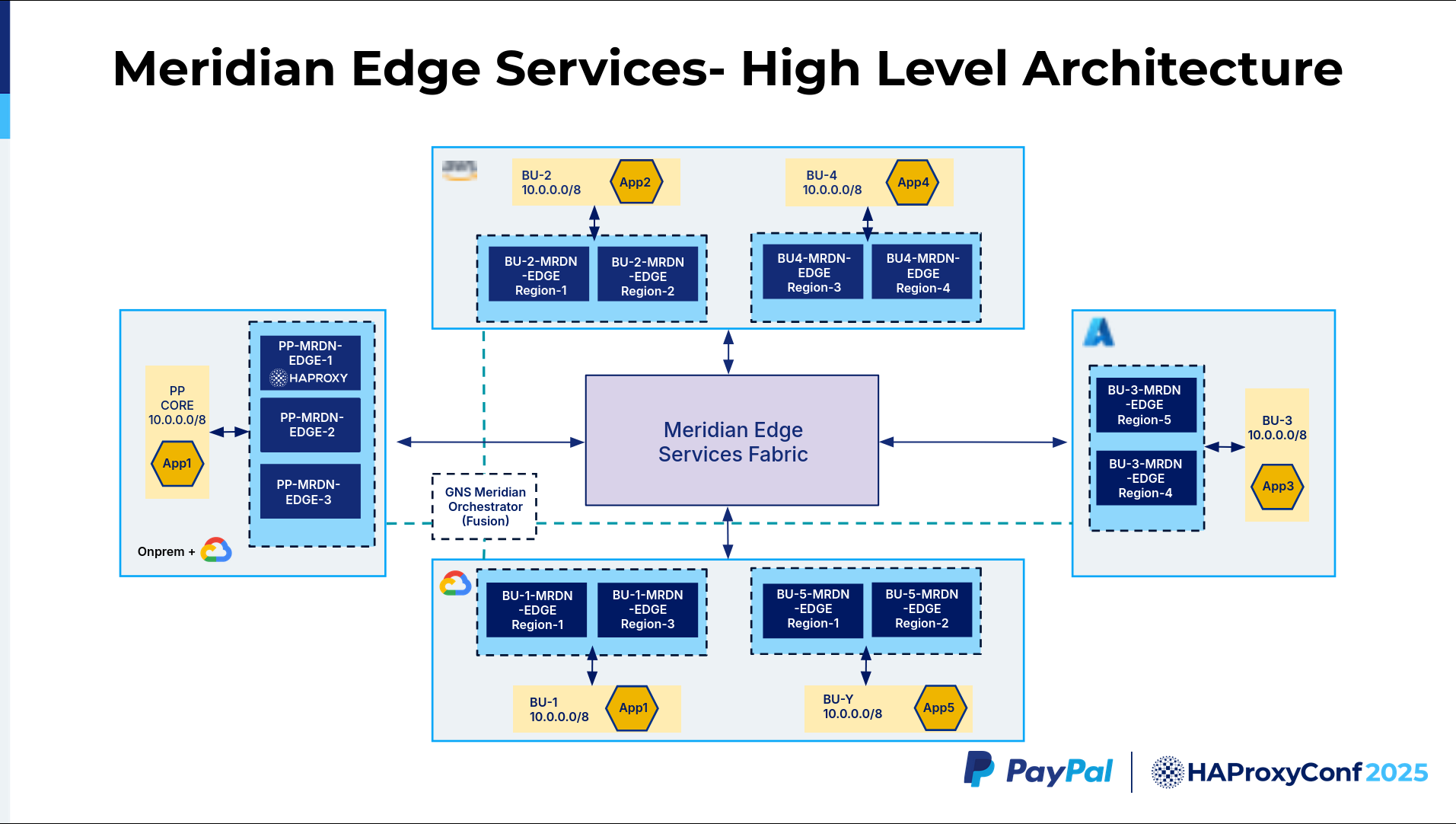
Let's jump into one of the solutions we built that fits into the Inner Meridian architecture. We call it Meridian Edge. Our business units are distributed across the cloud, and they all have the same 10.0.0.0/8 IP address space. They are also distributed across different regions. The boxes, which we call Meridian Edges, are the HAProxy clusters. To achieve high availability, we have multiple HAProxy clusters distributed within each cloud provider for each business unit.
Then, we have the GNS Meridian Orchestrator, which uses HAProxy Fusion as a core component. HAProxy Fusion helps manage all these clusters, onboard new frontends or new services, update map files, and help with other operational and observability tasks.
All these different Meridian Edges across these clouds are connected using the Meridian Edge Services Fabric, which leverages PayPal's global backbone and the public cloud backbone to route traffic via the lowest latency path.
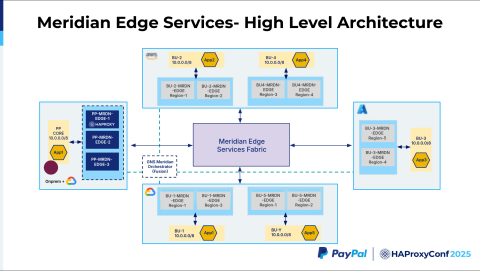
In this example, we have a PayPal core system. We call it App1 on the slide. It reaches an application in AWS in Business Unit 2, which is App2. What we want is a way to reach Application 2, but there are multiple ways to reach Application 2. How does the Meridian Fabric identify that this traffic is destined to Business Unit 2 and this application? And how does it do the routing?
The idea we had here was to use a domain name and a URI path combination to indicate the application instead of identifying it by a unique subdomain. We chose a domain name plus a URL path combination to distinguish it and figure out what Meridian Edge the traffic should be routed to. In this example, we can take that the endpoint name could be example.paypal.com/bu2/app2. Application 1 will be configured to reach this particular endpoint with a specific URL of bu2/app2.
Application 1 performs a DNS resolution. We use our F5 Global Traffic Manager or the cloud provider's native DNS solution to give us the low-latency, closest-path answer. For on-premises, we use an F5 Global Traffic Manager, figure out the closest Meridian Edge, and then the packet goes to that Meridian Edge.
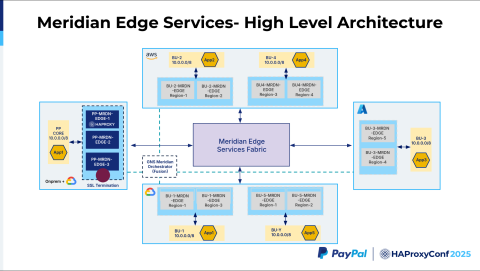
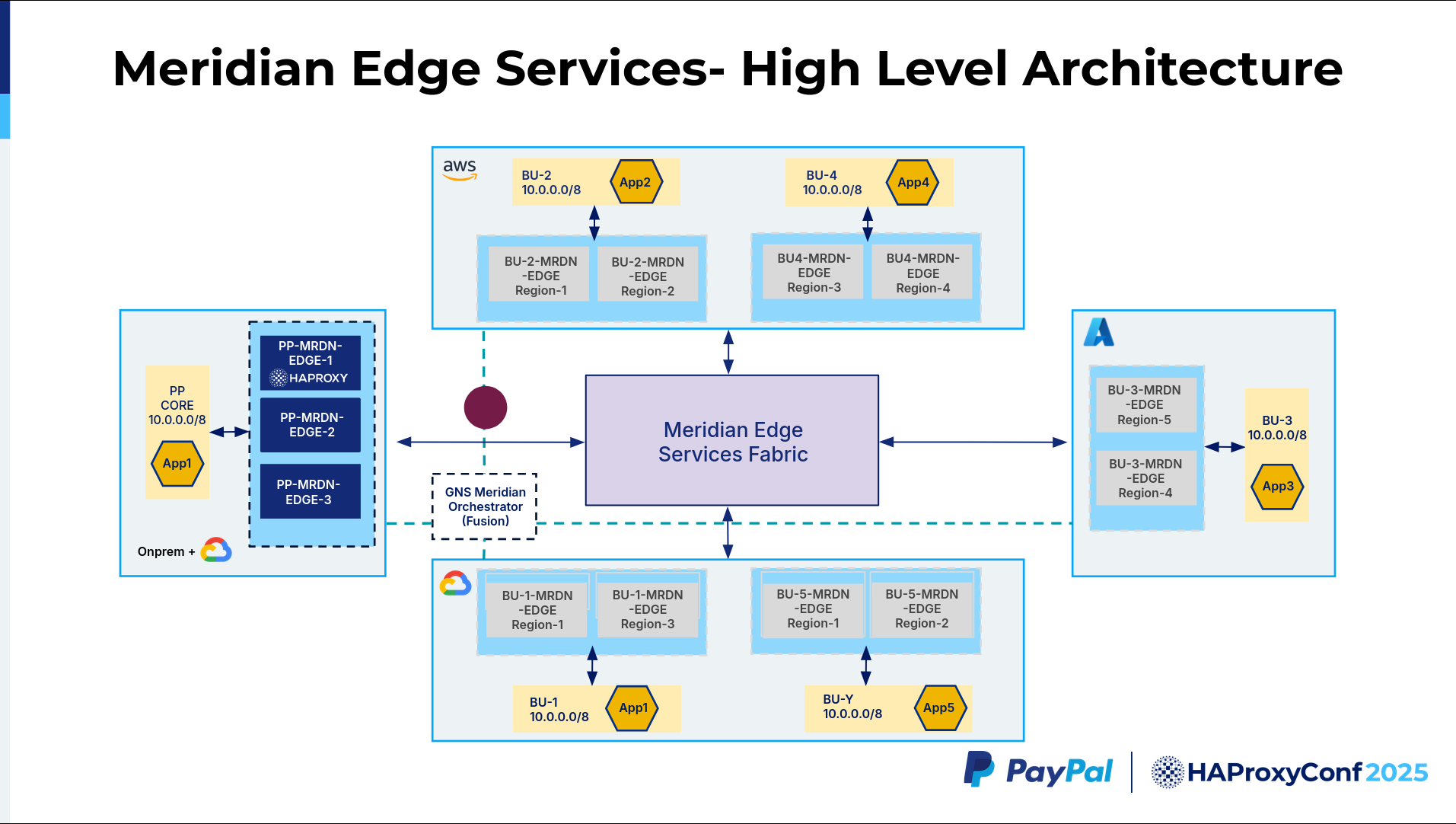
As you can see, the packet goes to Meridian Edge 3. When it goes here, one thing we noted is that the source IP address is going to be the RFC 1918 10.0.0.0/8 IP address. The destination address is going to be within the Meridian range. The interesting part is this Meridian Edge Services Fabric. They all have overlapping IPs. How can they talk to each other?
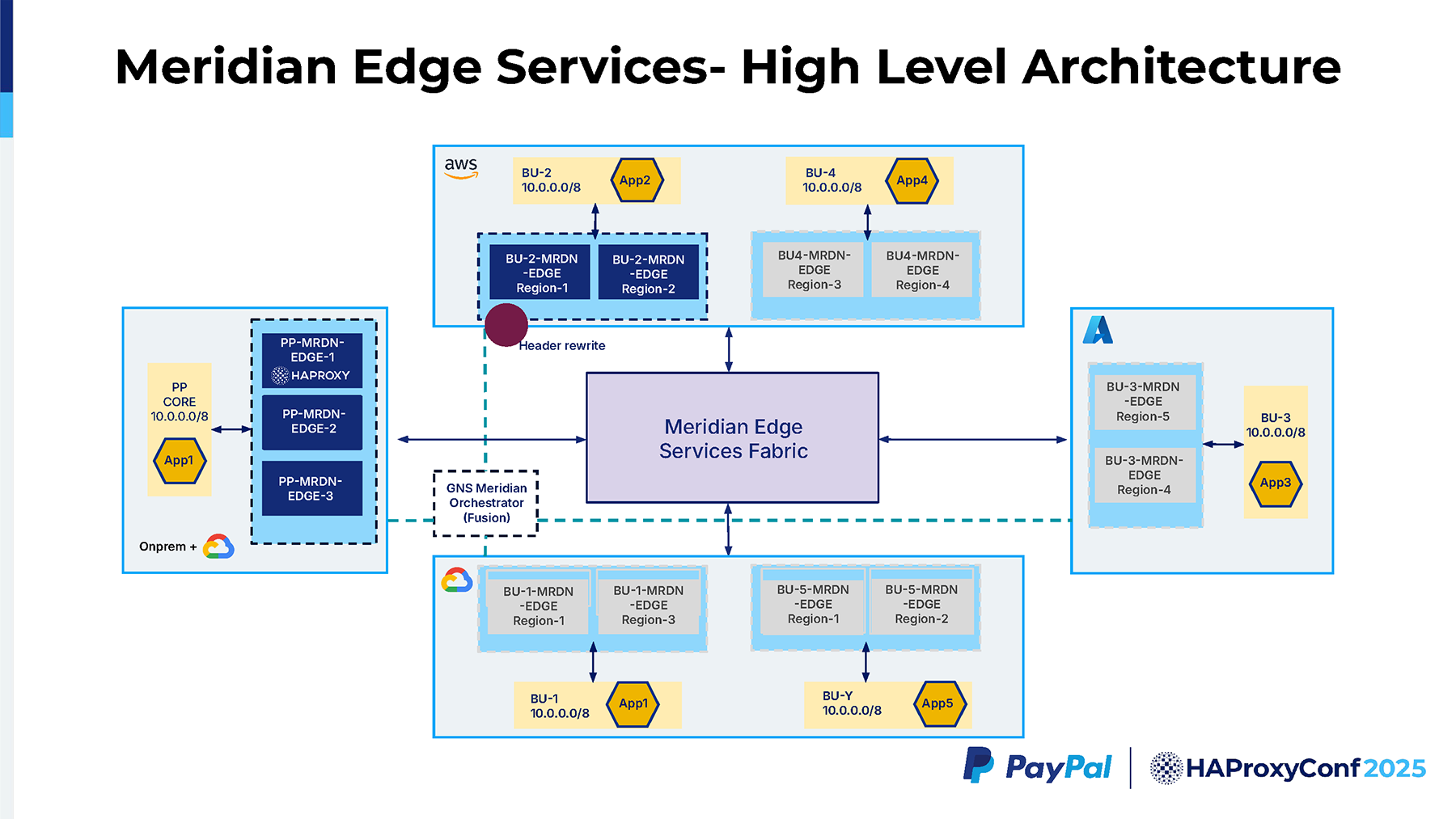
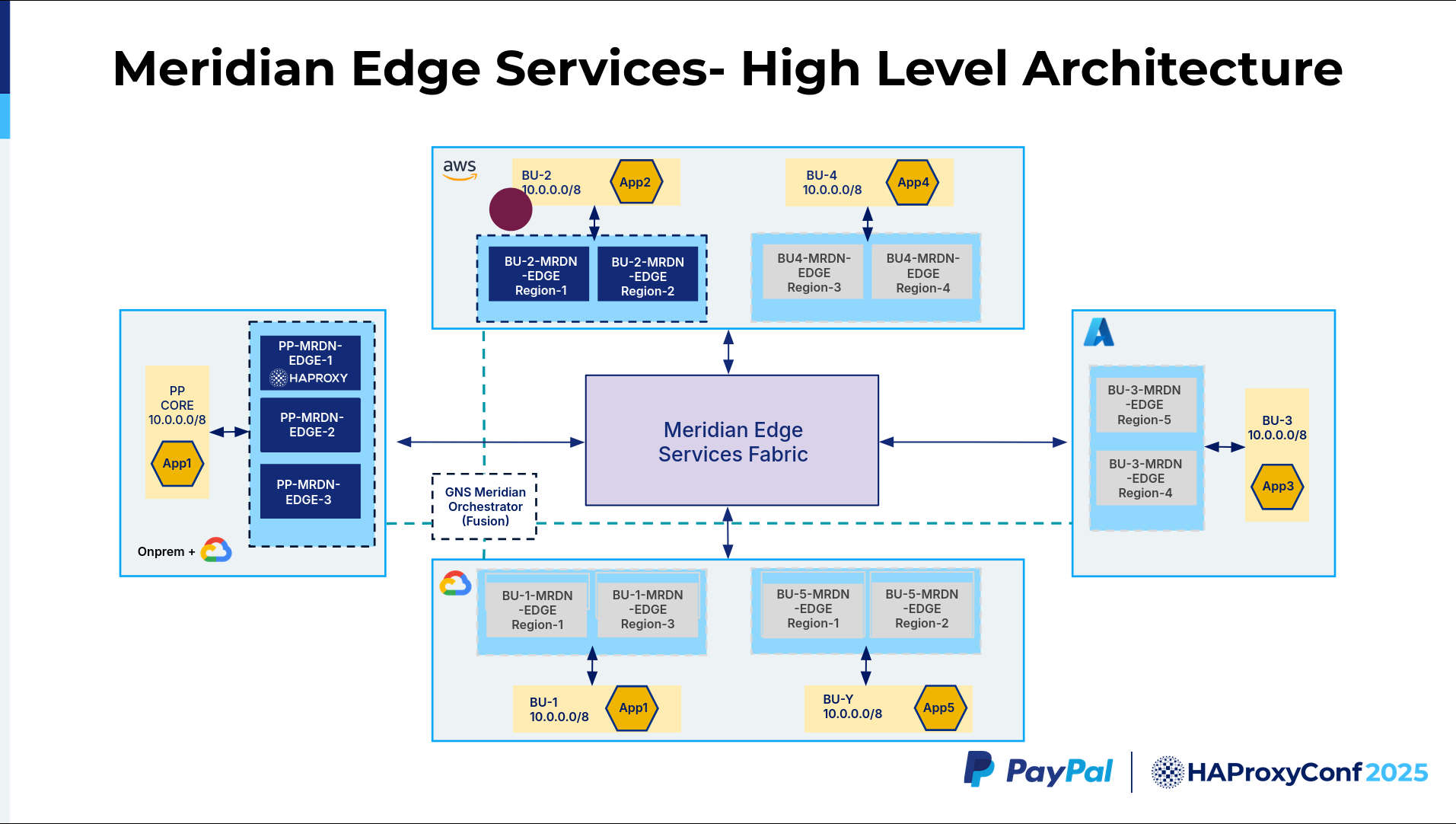
This Meridian Edge Services Fabric is built using the RFC 5785 IP range, which is the 198.18.0.0/15 range. We built this whole fabric with this non-overlapping range so that all these business units can talk to each other without carving out a unique public IP space or anything. So, that acts as a non-overlapping IP fabric across the business units. When the traffic hits Edge 3, it's going to be in the 198.18.0.0/15 space, and the Meridian Edge 3 performs SSL termination.
After doing the SSL termination, it has to decide which Meridian Edge Services Fabric it should route to, whether it's Azure or GCP, whatever it is. In our particular example, it's going to go to BU2 because the URI path in the map file says that it has to go to bu2/app2. So, Meridian Edge 3 has a map file config that does this routing lookup. It figures out it has to go to app2.
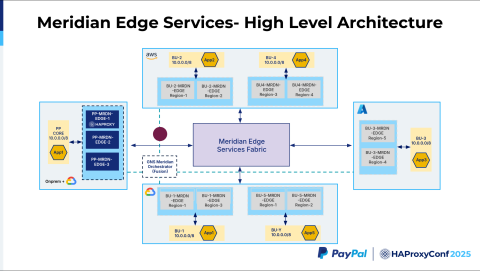
The traffic travels through the PayPal Meridian Edge Services Fabric, which underlays the PayPal global backbone.
It reaches the AWS Meridian Edge, which accepts the packet, rewrites the host header, and then strips the URI path. The idea is we want to have the Meridian Edge Services Fabric as seamless as possible to the customer. We don't want them, in their application, to understand all these additional components that are introduced in the path. So, we strip the URI path information, and then we route the request to Application 2.
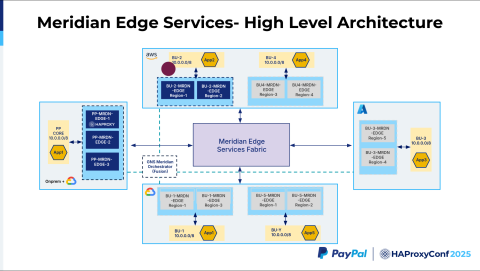
As we route this request from the business unit to Meridian Edge, it does an SNAT conversion, where it translates the source IP address from the Meridian range to the application's range in 10.0.0.0/8.
If you look at this whole architecture, what do we get? What is the advantage we achieve by introducing this extra layer of NAT? In other words, the whole problem can be solved by just introducing a specific source NAT on each side, right? Now, what do we get by introducing HAProxy into this mix?
The biggest advantage we got is a performance improvement. As you can see, these systems are distributed across different regions. With introducing HAProxy closer to each of the clients, we do a closer SSL termination. And then the second one is the Meridian Fabrics, they all have persistent HTTP/2 connections enabled, which means that we don't have to, every time, establish a TCP and SSL handshake because they're all persistent connections. We were able to quickly pass the package to the next Meridian Edge. That's the biggest advantage we get from this architecture.
Observability is also a big piece. Like Sid mentioned, earlier we had a challenge where when we'd go through the Internet or through any cloud providers, often we run into an issue. Application teams will say, "Hey, I had an application timeout." They'll assume that the problem is with the network, and so will jump to a conclusion and ask us to find the networking issue. When there's no clear observability, we know only that the packet left our infrastructure and that it didn't reach the other side.
With this new architecture, we were able to get the logs from each of the layers. As you can see, when the packet traverses the first layer of the Meridian HAProxy, we take a log, and then we have a second layer HAProxy, and we tie them together using a specific correlation ID using HAProxy Fusion. Now, HAProxy Fusion is a single pane of glass where we can look into the logs and see that, okay, this is the time taken for the application to process the request. And we have this round trip time. And we confirm that, okay, the problem stems from the application. It's a problematic response. It's not the network. That gives us better observability.
Another big area of flexibility we got with this architecture is we have multiple Meridian Edges. So we can seamlessly swing the traffic to different Meridian Edges and do maintenance for the teams.
That's the idea about the Meridian Edge. Now that we've covered Inner Meridian. Let's move on to the next level of the architecture, which is an example of our Outer Meridian service offering.
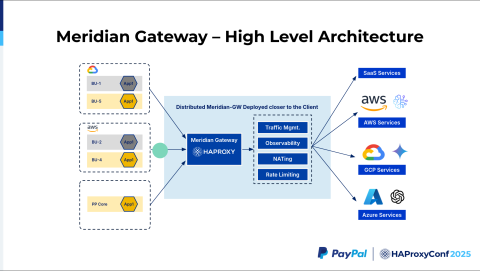
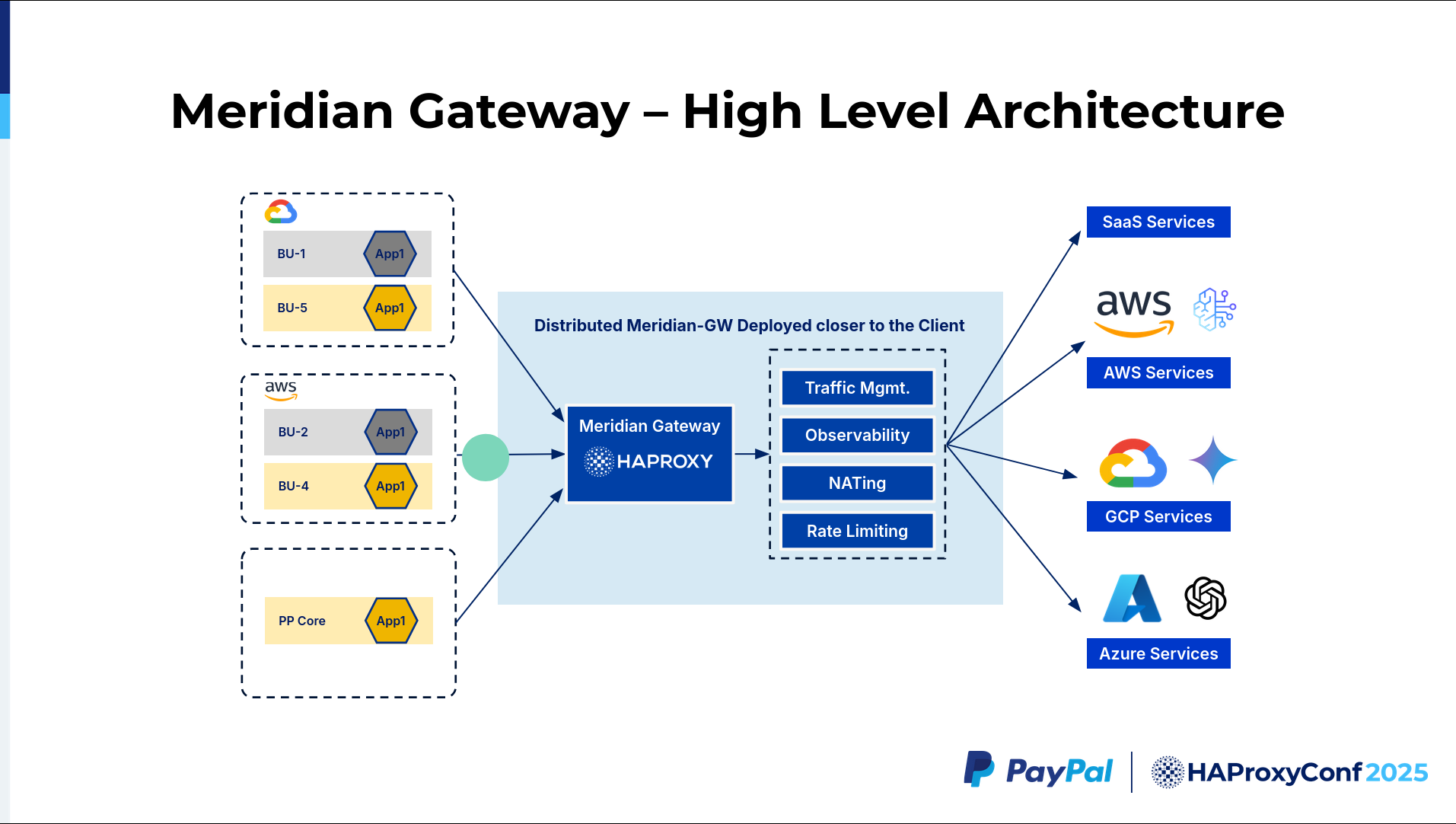
This is very similar to the previous architecture, but a different view of the system. We call this Meridian Gateway because, as I mentioned, it falls into Outer Meridian, where we want to have a central control point that we want to expose to all these different native services.
We have a common use case where we have a business unit in AWS that wants to talk to GCP. There is no way to send the traffic privately. Most of the time, you have to either go through the Internet or PNIs with those providers. Those systems are not as secure as we have in our infosec mandate. Also, sometimes we want to have some kind of control point where, if we want to have any kind of observability or introduce any new services like DLP or WAF, we need to have a central inspection point for those things. The idea here is that we will build something called Meridian Gateway, an HAProxy system distributed closer to the client. This HAProxy will terminate all connections from the business units, and then we will do all the required security inspection controls there. Then we route the traffic to the specific provider. It could be AWS, GCP, or a SaaS partner.
One major use case that we recently solved here is with AI. Everyone wants to connect to AI systems. We have many business units that are interested in exploring AI systems. We wanted to connect an AWS system to a GCP Gemini model. So, let's just understand the flow. It'll help us to go through the various actions that happen here.
We have a system in AWS that wants to talk to a GCP LLM model. The packet from AWS goes to the Meridian Gateway. We assign a specific subdomain for this. It could be gcplm.example.paypal.com. The traffic gets terminated at the closest Meridian Gateway in this case, where we have a mapping in the map file that says when I get a request for this particular Meridian Edge, I want to route the traffic to GCP because the subdomain is gcplm.example.com.
It's not just going to do the map file lookup and forward. One of our challenges is the GPU availability in different cloud providers. In US Central, they have certain GPU flavors, while in US West, they could have something different. So we also want to do traffic management. The AI team might have a requirement to route certain traffic to certain regions. We have to make that particular traffic management decision. As we get the requests from the clients, we figure out which particular regions and route the requests to them.
Another part is NATing. NATing is the basic feature here because we have all these business units that have these overlapping IP ranges. We want to make them unique. So we do a NAT to the Meridian range that I mentioned. We also do rate limiting. We don't want any of the business units to consume all the services. So we apply rate limiting based on the business decisions that we receive from the teams. And we route the request to the specific GCP LLM model.
That's a use case about the Meridian Gateway, which is our Outer Meridian system. With that, we deployed the solution. Like Sid mentioned, we went through multiple evolutions of the solution. We went with cloud-native, and then we tried HAProxy. And here are the results with HAProxy. I wanted to call out what things we achieved by applying this architecture.

One of the greatest advantages we saw was we got a 24% latency reduction in the application calls compared to the public CDN path. Before the Meridian architecture, when these business units wanted to talk to each other, we had to expose a risk API or payment API through the particular CDN provider where the business unit is hosted to the PayPal or other system they wanted to connect to. They would go through this public CDN path.
We onboarded the same application into our Meridian Edge Services Fabric and performed benchmark testing. We achieved a 24% latency improvement, but that's not where it stops.

The biggest value we had was that as soon as we pulled out those applications, just as they were exposed, because we wanted to let the other business units consume them, there was no real reason to put them in the public phasing property.
Our security has predominantly increased because the Meridian Edge Service Fabric is an entirely private path. We have all these applications that can be securely accessed. The attack surface is completely reduced, and the performance gain is also super good. That's one of the benefits we got as a result of this.

Another great thing we observed is that, because of this whole Meridian Edge Services architecture, whenever we want to expose a service - in the traditional way, every time we open a service, we have to open a firewall ticket from A to B, C to B. It's a difficult task, right? We have to expose the same application to multiple teams. With this Meridian architecture, once a service gets onboarded into Meridian, we onboard it only once.
And we have a service directory where the other business units can come and say, "Oh, the service is already onboarded. I just want to connect to it." And they can connect to it. So that's a big plus for our system, where all the application teams can easily develop their application on their current infrastructure and they can expose it or onboard it into Meridian, and we can easily share it to other business units.

Another great advantage we got with the HAProxy Fusion Control Plane is we have all these logs that we can look at as a single pane of glass. Whenever we get an HTTP request in, we get to see it at different points of time. At region one, what happened to the request? What happened to the request at region two? What is the network round trip time? And what is the total time it took for HAProxy to process the request? What's the application response time? This gives us very good visibility and troubleshooting capabilities.
So all our teams are super happy. Because we often get into the situation where app teams blame our network, and the network team doesn't have any real evidence to show that it's not the network. With HAProxy Fusion, it was really amazing that we could just take the correlation ID, which is a unique ID generated by our Meridian fabric, just put it in HAProxy Fusion, you get the log, and you have the nice visibility on what happened to your traffic.

And last but not least, this is not actually part of the design, but we realized after we designed it that we had also solved this problem: efficiency. At PayPal's scale, we run about 3,500 applications. All these applications have their own way of modernizing the system. Sometimes, that's pretty challenging.
We have an application that could still be running in HTTP 1.1, and a business unit wants to consume that API or that application. The team that built that application isn't going to add cycles to upgrade their systems, or maybe they have a different priority. At the same time, that application needs to be exposed to our business unit. If we expose it traditionally, with HTTP/1, we will have a big performance hit, especially at PayPal's scale. With applications spread across different regions, it's a difficult one.
What we did with Meridian, HAProxy can translate HTTP/1 to HTTP/2, which is an added advantage we got, through which we were able to build better efficiency.

This solution helped us accelerate the overall PayPal conversion strategy. We have different brands, and we're trying to combine them to give our customers a cohesive experience. This Meridian Services Fabric idea that we built using HAProxy really accelerated our conversions across the business units.
With that, I'll hand it off to Sid for the closing thoughts. Thank you.
Siddhartha Mukkamala
Thank you, Kalai. I would like to take this opportunity to thank everybody in the HAProxy team, Jakub and everyone. Thanks for partnering with us for the solution!

Closing thoughts: as we've seen, building that private connectivity between the business units is especially hard when there is an IP address overlap. So we partnered with HAProxy, and it helped us to provide consistent connectivity across the cloud providers.
The second one is the IP range that we use. Like Kalai mentioned, we used RFC 5735. So we looked at other IP ranges. For example, we looked at the CGNAT space, 100.64.0.0/19. But many of our business units are already using that for GKE, EKS, or AKS. Basically, they are using it for the Kubernetes pod range. So we went with the 5735, which is the 198.18.0.0/15 range.
And finally, what's next? We are working on self-service. Currently, we don't have self-service. So any onboarding has to go through the manual process. We have to onboard it. So we're looking at that self-service automation and partnering with HAProxy to provide the service discovery option.
Thanks, everyone!
