
Liftoff, a mobile advertising company, processes 1.5 trillion bid requests every month. Their platform touches 275 million unique devices daily across 150 geographies. At that scale, the proxy layer is a core part of the business.
For years, Liftoff relied on a managed enterprise proxy vendor. It worked, until it didn’t. As traffic grew, so did the challenges: rising operational costs, vendor lock-in, and performance limitations threatened their ability to maintain the ultra-low latency their ad tech platform demanded.
These obstacles led Liftoff to migrate to HAProxy, reducing costs by 87.6% and improving latency by 75%. Tommy Nguyen and Ken Chin shared their journey at HAProxyConf, and we unpack their story below.
Inefficiencies, latency, and rising costs
Liftoff’s proxy was a managed service sitting outside their infrastructure. Every configuration change went through the vendor. Routine updates that should have taken a day could stretch across an entire sprint cycle.
The vendor’s platform also added extra network hops between Liftoff’s systems and their backend services. This added latency is a real problem for an ad tech company where milliseconds directly affect revenue.
Agility and performance weren’t the only challenges faced.
Costs scaled with traffic, but not in a manageable way. Their vendor's pricing model made it harder for the business to grow efficiently. And because the proxy was proprietary, Liftoff didn’t have the flexibility to change directions if their architecture needs shifted.
Liftoff decided they needed a sovereign infrastructure solution that they could own, configure, and run themselves.
Building their architecture with HAProxy
The team spent six months moving from initial testing to a production-ready HAProxy deployment. They ran performance tests, collaborated across teams, and built the automation and monitoring tooling needed before going live.
The architecture they landed on used GitHub Actions to trigger builds, HashiCorp Packer to create pre-configured machine images, and Ansible to handle consistent provisioning across servers. AWS EC2 instances ran HAProxy, with Route 53 directing inbound traffic. AWS Network Load Balancers (NLBs) sat between HAProxy and backend Kubernetes clusters spread across multiple availability zones.
The results were immediate and significant. Operational costs dropped by 87.6%. Latency improved by 75%. Configuration deployments that previously took weeks could now be completed in a single day — a 93% improvement in deployment speed.
That was phase one.
Using HAProxy to address outages and NLB blind spots
After a period of stable operation, a major traffic failure hit the Liftoff platform. The team couldn't restore normal service for several hours. The outage was painful, but what made it worse was not being able to pinpoint the cause quickly.
The NLBs sitting between HAProxy and the backend pods were a blind spot. There wasn't enough visibility into that layer to diagnose what was happening during the incident. Troubleshooting required guesswork, and that cost time.
The incident pushed the team to rethink the architecture – to lean more on the trusted and reliable HAProxy deployment. The question wasn't just how to prevent another failure; it was how to make HAProxy the single, observable control point for all traffic decisions.
Rebuilding with dynamic service discovery
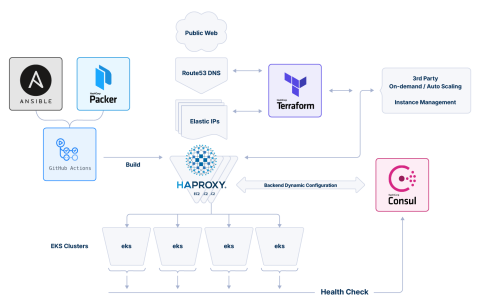
The second-generation design removed the NLBs entirely. HAProxy now connects directly to backend pods in the EKS clusters, with no intermediate routing layer between them.
To make that work at scale, the team integrated Consul service discovery with HAProxy. Backend services automatically register themselves in Consul's catalog. HAProxy reads those records in real time, so its routing table stays up to date without manual changes or configuration redeployment. When a pod turns unhealthy, Consul removes it, and HAProxy stops sending traffic there — immediately, automatically.
As a result, HAProxy now makes the routing decisions. It knows which backends are healthy, where they are, and how to reach them. There's no secondary system making routing choices that HAProxy can't see.
This flatter design brought an additional 20% reduction in operational costs, simply by eliminating the abstraction layer that was no longer needed. While that improvement was not the original intention, it reflects how much unnecessary overhead the old architecture carried.
End-to-end visibility with HAProxy
The new architecture gave Liftoff something they hadn't had before: end-to-end visibility from the moment a request hits HAProxy through to storage.
They use HAProxy's native Prometheus exporter to export metrics to Prometheus, then visualize everything using a modified version of HAProxy's Grafana template. The dashboards track connection rates, backend response times, latency, HTTP response codes, and Consul catalog counts throughout the day.
Because Liftoff's traffic follows predictable patterns, they can also run reliable week-over-week comparisons and spot anomalies early. They take their logs out of HAProxy and ingest them into their Loki, giving the team a centralized place to query and analyze log data alongside their metrics.
This kind of observability stack is what the first architecture was missing. Now, when something goes wrong, the team has the data to diagnose it quickly.
What the HAProxy roadmap looks like for Liftoff
Liftoff is planning to upgrade HAProxy to the latest version, with several specific capabilities driving the decision.
Glitch limit functionality will help the team handle protocol glitches without draining CPU resources. Enhanced logging will give them finer-grained data at the HAProxy layer, improving their ability to correlate events across the stack. Enhanced stick tables and improved traffic prioritization will let them shape traffic more precisely across different service tiers (particularly useful when some services have tighter latency requirements than others).
They're also planning to move from a third-party auto-scaling solution to a first-party one, giving them more direct control over how HAProxy instances scale against their specific traffic patterns. And they're working on grouping HAProxy instances by traffic destination, so that high-priority or latency-sensitive services get dedicated capacity rather than competing for shared resources.
Further out, the team is watching HAProxy's AI gateway capabilities. As LLM-based API traffic becomes more common in their stack, routing it through HAProxy (with the same performance, configurability, and observability they already rely on) is a natural extension of what they've built.
While Liftoff achieved these results with the open source version of HAProxy, organizations that need enterprise-grade service discovery, automated configuration management, direct-to-pod routing, centralized observability, and high-throughput performance at scale can get these capabilities out of the box with HAProxy One, the world's fastest application delivery and security platform.
Subscribe to our blog. Get the latest release updates, tutorials, and deep-dives from HAProxy experts.



