
What happens when your enterprise proxy solution becomes your biggest bottleneck? For Liftoff, a mobile advertising company processing 1.5 trillion bid requests monthly across 275 million daily unique devices and 150 geographies, this question became a critical business challenge. Tommy Nguyen, Technical Manager at Liftoff, and Ken Chin, Senior Software Engineer, faced escalating operational costs, vendor lock-in, and performance limitations that threatened their ability to maintain the ultra-low latency their ad tech platform demanded.
In this HAProxyConf presentation, the team shares their strategic migration journey to HAProxy with remarkable results: an 87.6% cost reduction, 75% latency improvement, and 93% faster configuration deployment cycles. However, their story goes beyond initial success metrics—a critical production incident became a turning point that taught them invaluable lessons about observability and monitoring, ultimately reshaping their entire architecture approach.
The speakers walk through their complete evolution from initial HAProxy implementation to their current sophisticated setup featuring dynamic service discovery with HashiCorp Consul, comprehensive monitoring with Grafana and Prometheus, and a cloud-agnostic architecture that eliminates vendor lock-in. They also share their future roadmap, including plans for HAProxy 3.x migration and exciting possibilities in AI gateway integration. This candid presentation offers both technical insights and practical lessons learned from running HAProxy at scale in a demanding ad tech environment.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.


















Tommy Nguyen
My name is Tommy Nguyen. I'm a technical manager at Liftoff, and joining me today is my co-worker, Ken Chin, Senior Software Engineer. We’re excited to share our journey at Liftoff and discuss how we leverage HAProxy to simplify, scale, and secure our modern applications.
Together, we will walk you through the challenges we face, the solutions we implement, and the lessons we’ve learned along the way as we evolved our infrastructure with HAProxy.
Whether you are just starting out with HAProxy or looking to optimize your existing application, we hope our story provides valuable insights and practical takeaways you can apply to your own environment.
First, I’ll tell you a bit about my company, Liftoff, and how we started with HAProxy. Then we’ll describe a specific event that happened and the changes that we implemented as a result. Finally, we’ll discuss our plans for the future with HAProxy.
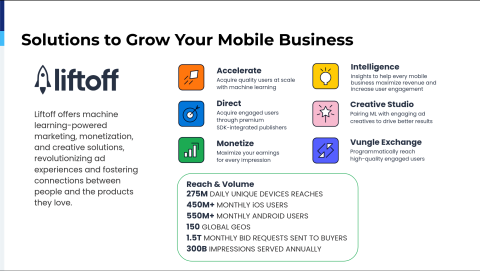
Liftoff mobile advertising services
Liftoff is a mobile advertising service company, founded back in 2012, based in Redwood City, California.
At Liftoff, our mission is straightforward. We connect people with the mobile products and services they love to use.
Everything we build, from our machine learning algorithms to our creative tools, is designed to make that connection as seamless and relevant as possible.
We support over 275 million daily unique devices.
Touching nearly a billion mobile devices and mobile users every month across 150 geographies.
Our platform processes 1.5 trillion bid requests from buyers each month, serving 300 billion impressions annually.
This massive footprint ensures customer apps can achieve both depth in key markets and breadth around the globe.

HAProxy is recognized as the world's fastest and most widely used software load balancer. Its performance and reliability have made it a cornerstone for countless organizations across the globe, including Liftoff. At Liftoff, we leverage HAProxy to simplify our infrastructure, scale our services efficiently, and ensure our applications remain secure and resilient.
In today's presentation, we'll walk you through our migration story, share how we integrated HAProxy with Kubernetes, and discuss what the future holds for us as we continue to innovate with HAProxy at the core of our platform.
Let's take a look at how we first introduced HAProxy at Liftoff. We'll walk through the early days of our adoption, the initial motivations behind choosing HAProxy, and key factors that shaped our decision making process.
As an ad tech company, Liftoff handles a massive volume of inbound requests, and we operate under strict low-latency requirements.
Our previous proxy vendor offered a solid enterprise solution, but we began to encounter several challenges that prompted us to rethink our approach.
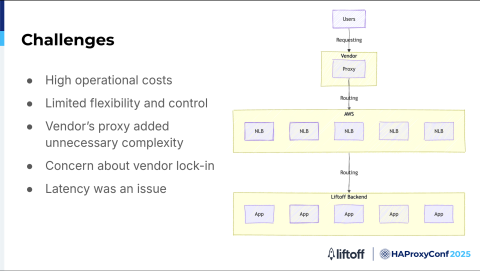
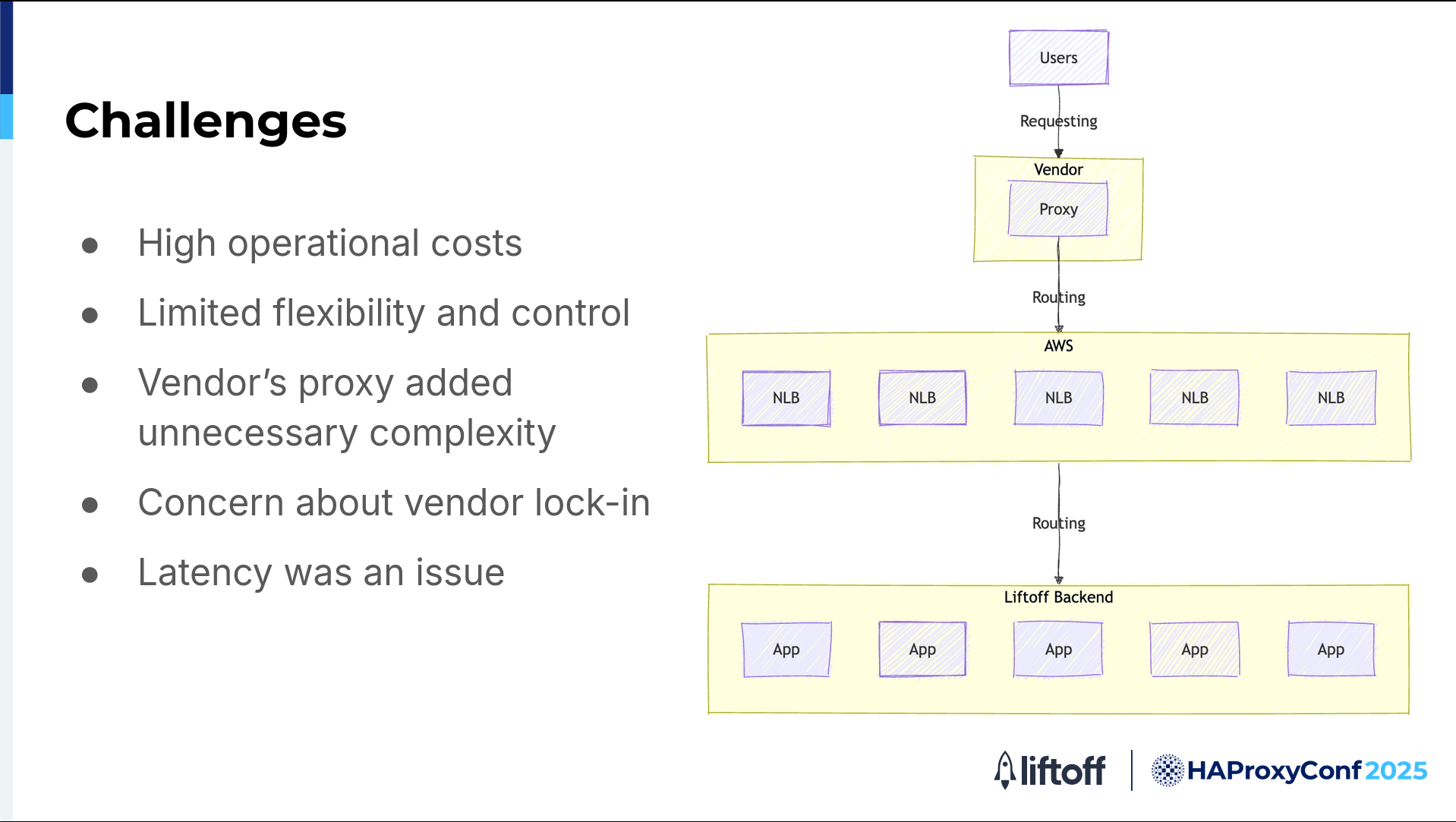
Infrastructure before HAProxy
Challenges we encountered before designing a new infrastructure:
The operational costs were high. As our traffic increased, so did our expenses, making it harder to scale efficiently.
We lacked flexibility and control because our proxy was a managed service. We couldn't easily adjust configurations or security policies to fit our needs, slowing our ability to innovate and respond quickly to incidents.
Integrating the vendor's proxy with our cloud-native environment added unnecessary complexity. Even routine changes required coordination with the vendor, which led to longer deployment cycles and more work for our teams.
We were concerned about vendor lock-in. Relying on a proprietary platform made it difficult to adopt new technologies or change our architecture as our business evolved.
Performance was an issue. Since the proxy operated outside of our infrastructure, it introduced extra network hops and latency, something we couldn't afford with our strict latency requirements.
All of these challenges motivated us to look for a solution that was more flexible, cost-effective, and high-performing.
That's what led us to HAProxy.
After running into these challenges with the vendor, we realized it was time to step back and think carefully about the next step. Our infrastructure had reached a turning point, and we needed to look at all the options out there to make sure we could meet our goals for performance, scalability, and operation.

As we looked at our options, HAProxy quickly stood out. We wanted something flexible, cost-effective, and fast.
It took us about six months to go from testing to having a solution ready for production users. During this time, we ran a lot of tests, checked HAProxy’s performance, and made sure it met all our needs. We didn't rush. We took the time to plan the migration carefully, fix any risks, and make sure everything would work smoothly in production.
This meant working closely with different teams, improving our settings, and building the tools we needed for automation and monitoring. By the end, we had moved from just testing HAProxy to running it as a reliable, well-documented, and scalable part of our infrastructure, ready to support our key services.
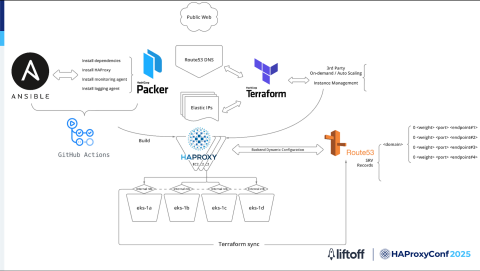
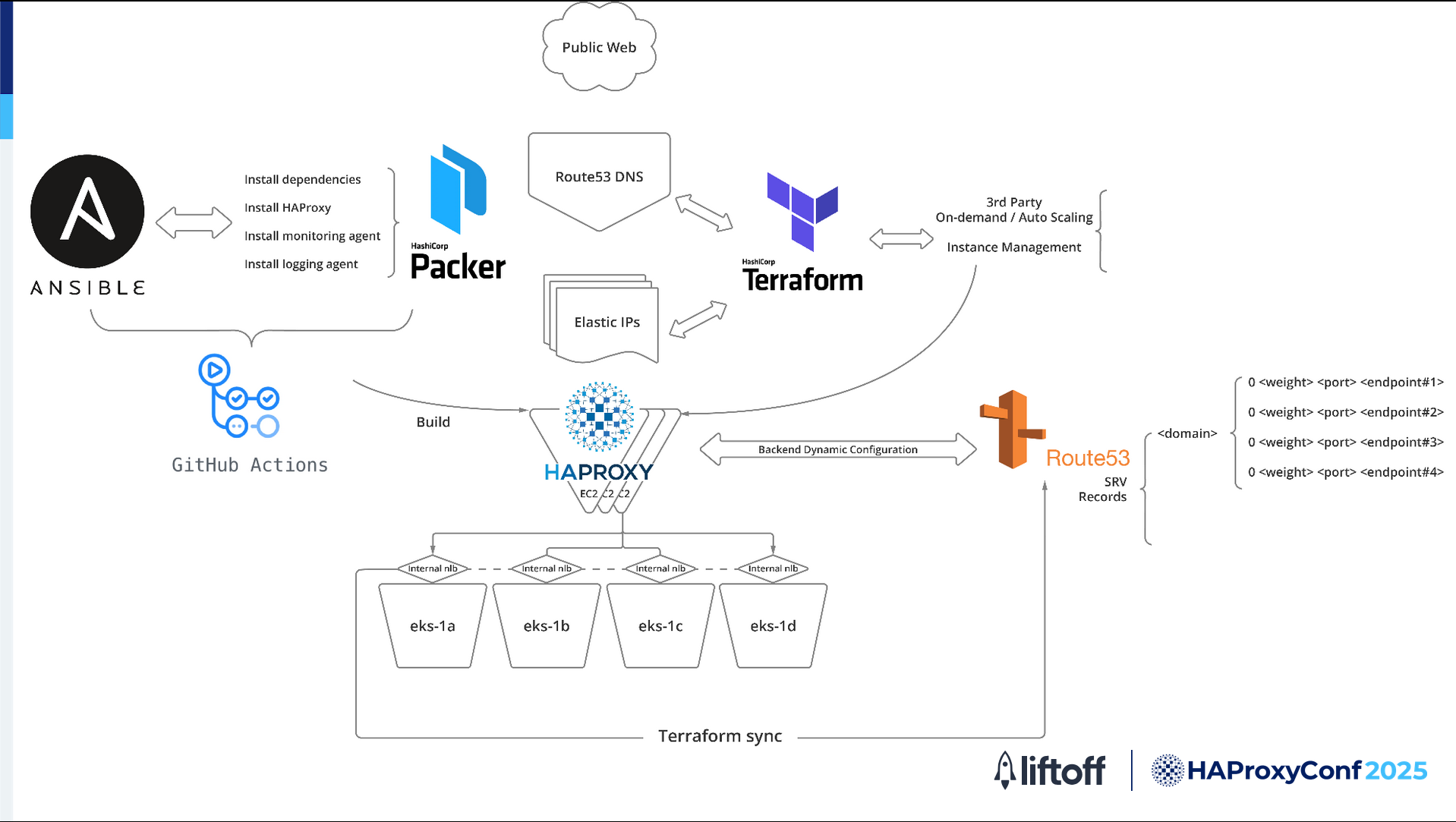
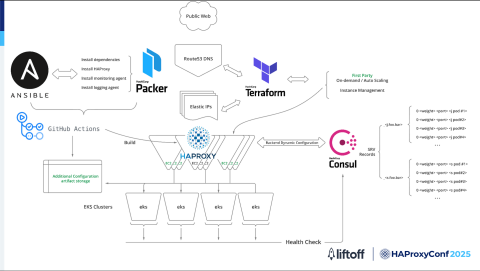
First HAProxy design
The original implementation had this infrastructure:
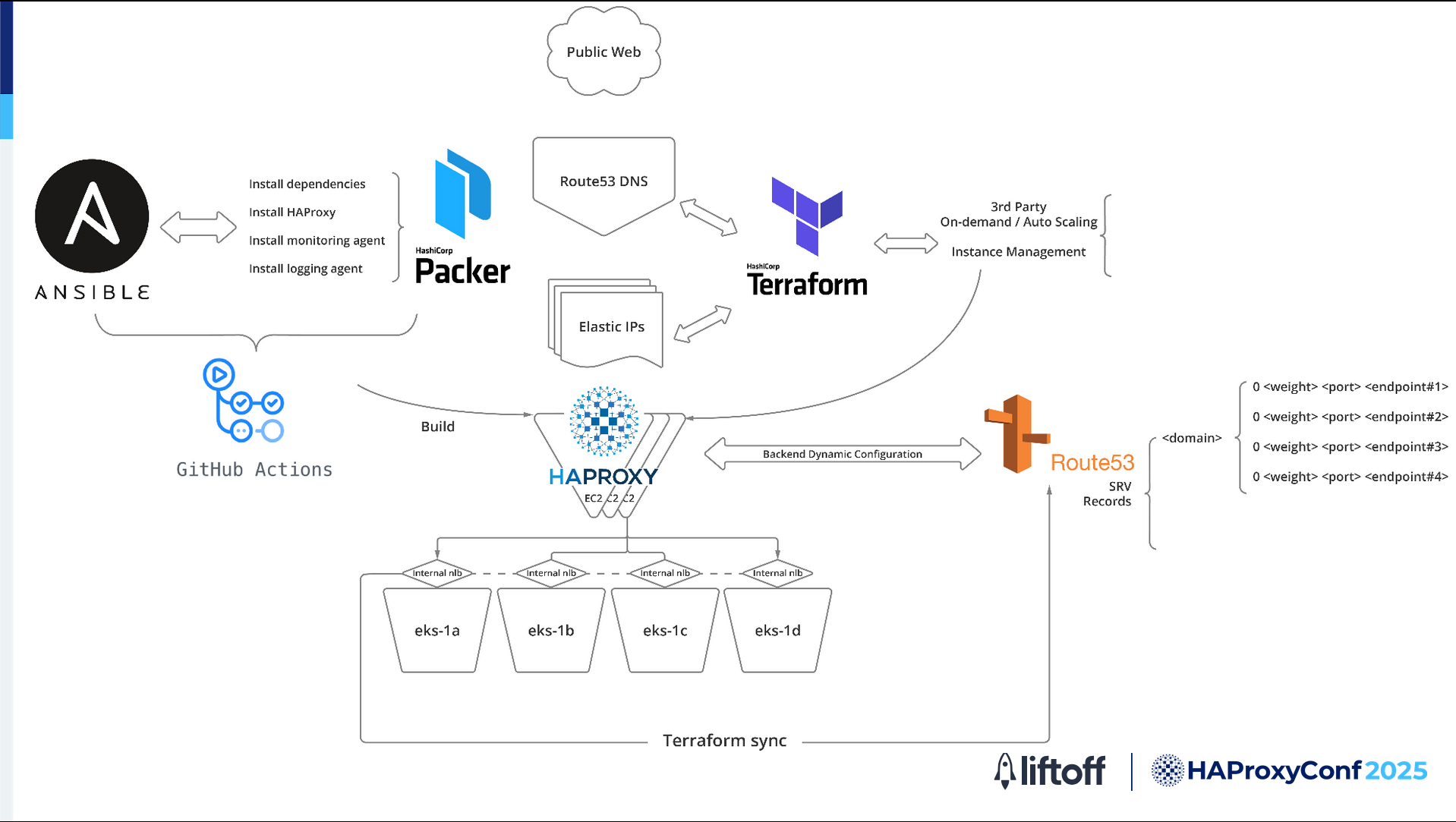
Building and setting up:
We use GitHub Actions to start the build process.
With HashiCorp Packer, we create machine images that already have everything we need, like HAProxy, monitoring tools, and logging tools.
Ansible helps us to install and configure everything the same way on every server.
Creating and managing servers:
After the image is ready, we use infrastructure-as-code to create and manage servers and network settings, such as AWS EC2 instances, IP addresses, and DNS records. This setup makes it easy to add or remove servers as needed.
Backend services:
We use AWS Network Load Balances (NLBs) and target groups. Each backend service is registered with an NLB, which manages and distributes traffic to the available servers. HAProxy forwards requests to this NLB, and the NLBs handle routing to the backend servers automatically. This setup allows backend changes to be managed efficiently without manual updates.
The traffic flows through this infrastructure as follows:
When users send requests, the Amazon Route 53 DNS service directs them to HAProxy servers on EC2. These servers are always up-to-date because of the automated setup that we have.
HAProxy then forwards the request to the appropriate backend through the NLBs, which are connected to Kubernetes clusters spread across multiple AWS availability zones for high availability.
Automation and scaling:
We use a vendor solution that is tightly integrated with AWS. This solution allows the infrastructure to automatically scale up and down based on demand.
GitHub Actions and Terraform handle the setup and configuration of new servers while Route 53, HAProxy, and AWS manage the backend chain efficiently.
In short, this setup gives us a reliable, automated, and scalable HAProxy system. It ensures fast and dependable traffic management for workloads while also giving us the flexibility to adapt as our infrastructure grows and changes.
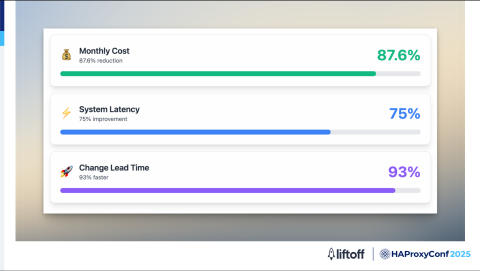
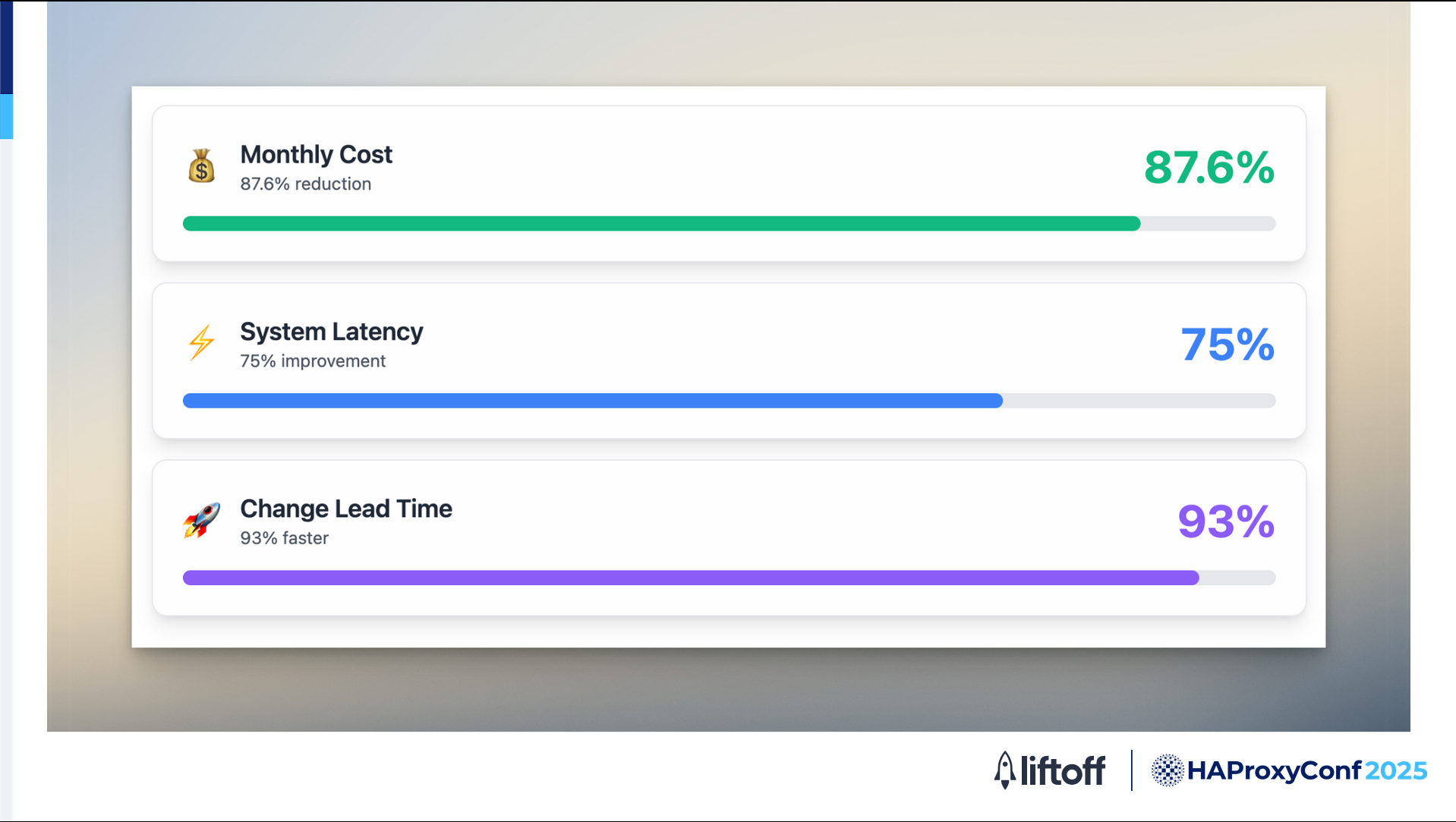
Here's some results we achieved from the migration.
We reduced our cost dramatically by 87.6%.
Latency improved by 75%, which was transformative for our ad tech workloads, where both cost efficiency and low latency are critical.
Additionally, moving to an in-house setup empowers our team to be far more agile. Previously, making configuration changes could take an entire Spring season. Now, with our own HAProxy infrastructure, we can implement and deploy changes in just one day, leading to 93% faster turnaround and significantly boosting our productivity.
That essentially wraps up phase one of our HAProxy journey, where we successfully migrated from our previous vendor to a fully managed HAProxy setup.
For a while, everything ran smoothly and met our expectations for performance and reliability.
Ken Chin
Then after significant growth in business, we encountered a major incident that became a turning point for our team. One day, the traffic flow experienced a critical failure, and we were unable to restore it to a functional state after several hours. This outage was significant, especially given the scale and latency requirements for our ad tech platform.
The root of the problem was a lack of visibility into one of the key components in our stack. When traffic flow was having an ongoing issue, we didn't have the necessary monitoring or observability in place to quickly identify the exact cause.
This blind spot made troubleshooting extremely difficult and prolonged the downtime. The incident highlighted the importance of deep observability and robust monitoring in our infrastructure. It was a wake-up call that pushed us to move on to the next chapter of our HAProxy journey.

Previously, AWS NLBs sat between HAProxy and our backend services. This design added extra layers of complexity and potential points of failure as well as additional latency in our traffic flow.
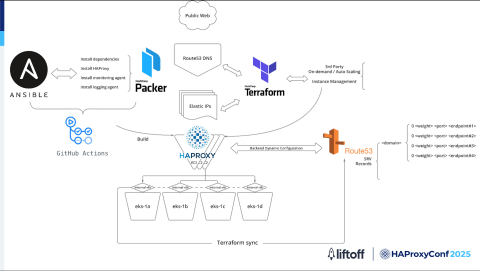
First HAProxy design
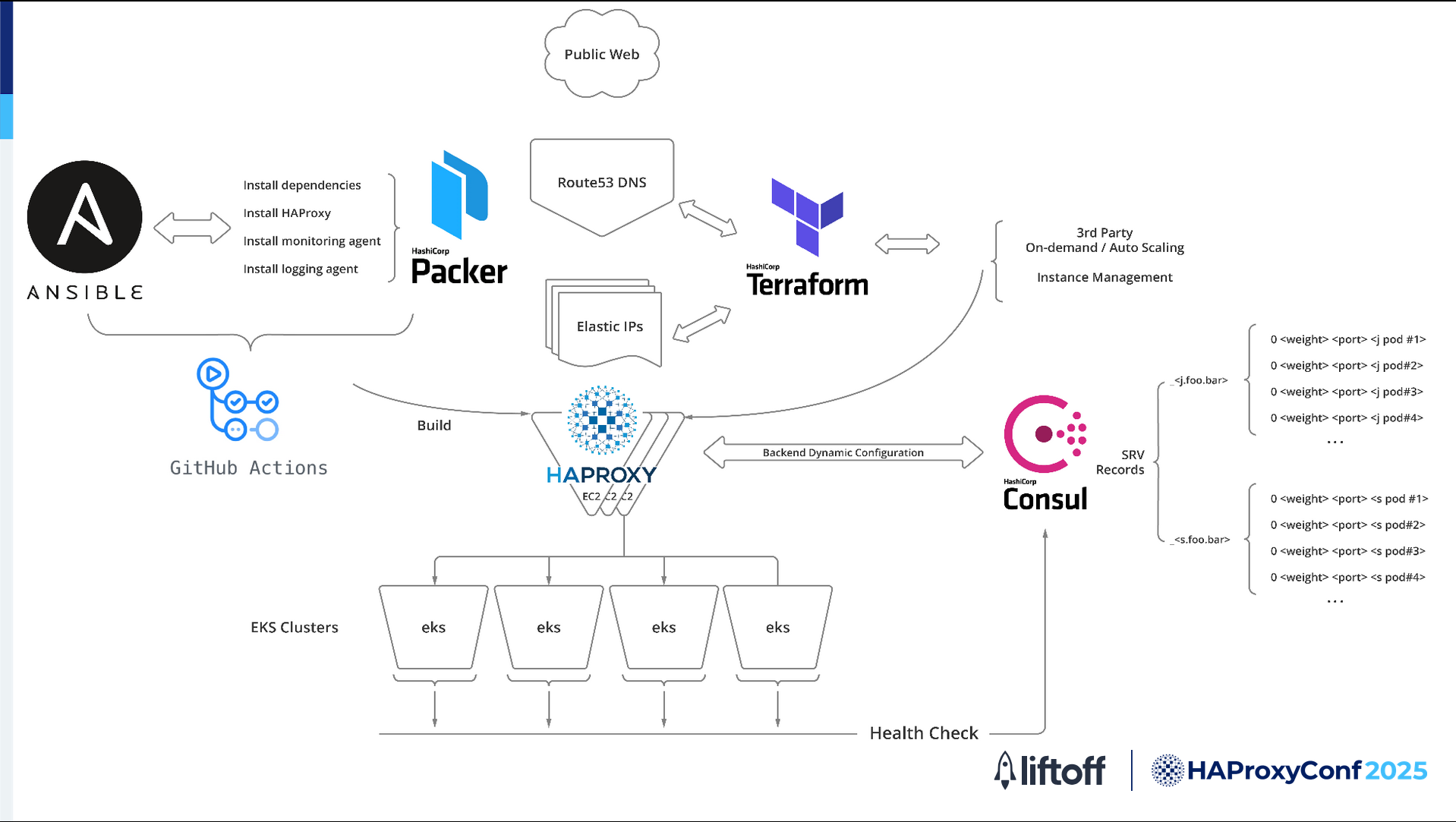
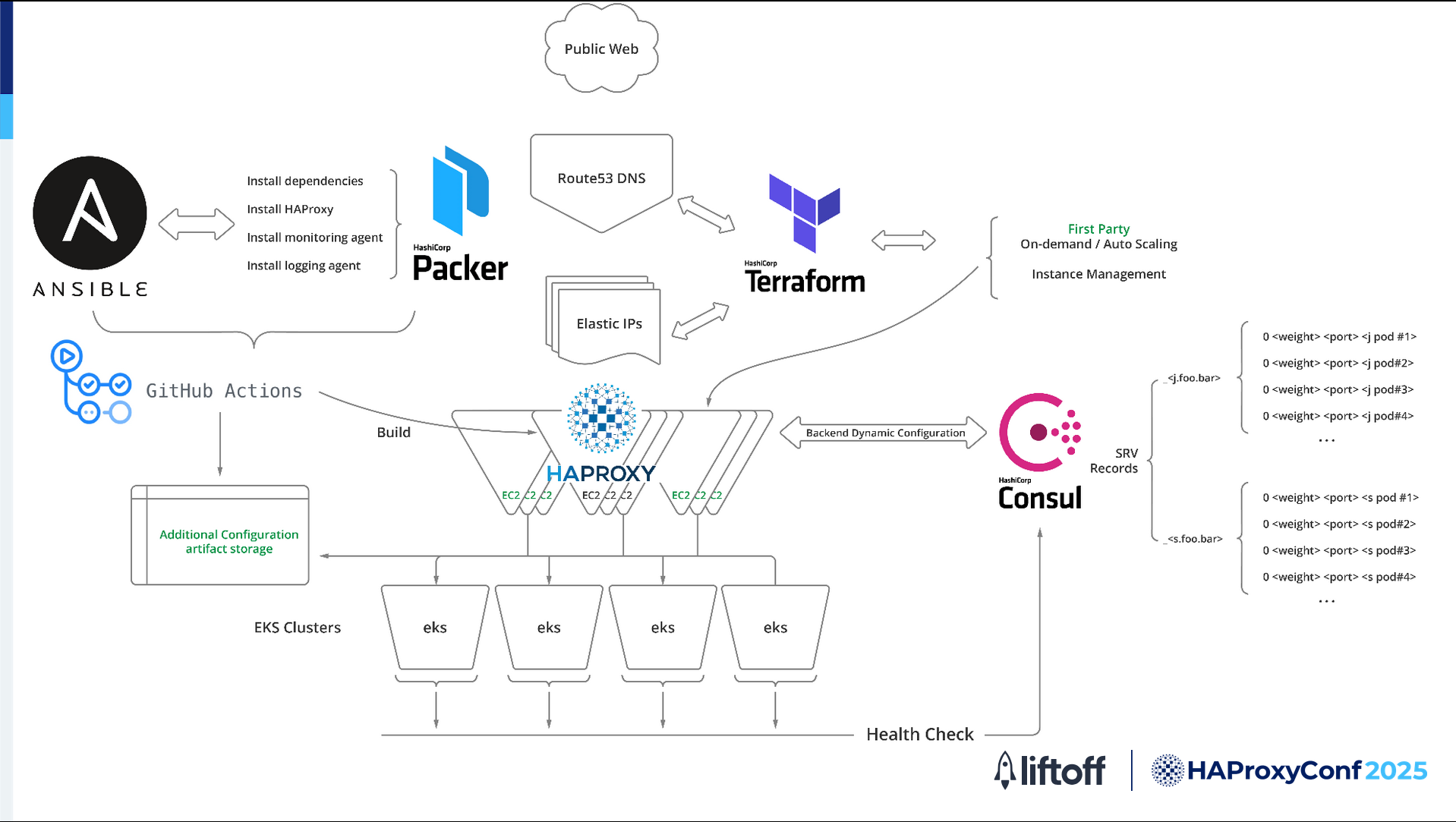
So we adopted a new approach that gave us a flatter network architecture. We integrated dynamic service discovery allowing HAProxy to automatically detect and route traffic to healthy backend Kubernetes pods in real-time.
The result is a simpler, more robust, and highly responsive system that adapts quickly to changes in our backend environment, delivering lower latency and greater reliability for our ad tech workloads.
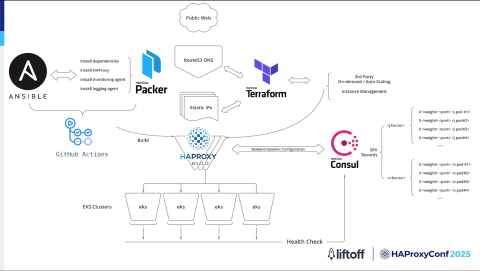
Second HAProxy design
In the new design, Ansible, Packer, and GitHub Actions still serve the build function. It’s in the service discovery implementation where things get interesting.
In the new design, we use HashiCorp Consul for service discovery. Every backend service running in our EKS clusters automatically registers itself into Consul’s catalog so Consul can track all the healthy pods and update its SRV records in real-time.
HAProxy talks directly to Consul, so it always knows exactly where to send traffic. We no longer have to worry about manual updates or stale configurations.
When a request comes in from the Internet, Route 53 sends it to one of our HAProxy EC2 instances. From there, HAProxy connects straight to the backend pods in our EKS clusters using the information retrieved from Consul.
This flatter network design means there are no extra hops or layers in the way, which really helps keep our latency low and our troubleshooting simple.
Consul is also constantly checking the health of our backend pods. If something goes wrong, it automatically pulls unhealthy endpoints out of rotation, so HAProxy only sends traffic to pods that are up and running.
Now let's talk about how this compares to what we had before.
In our legacy design, we had AWS NLBs sitting between HAProxy and our backends. This configuration added extra layers, more complexity, and more places where things could go wrong.
Service discovery was mostly static and relied on manual updates from the vendor, so if something changed in our backend, we had to wait for the vendor to make the changes.
Traffic also had to pass through the NLBs before reaching our backend pods, which not only added latency but also made troubleshooting a lot harder.
With our new design, it's a whole different story:
We have a flatter network.
HAProxy talks directly to the backend pods.
Service discovery is fully dynamic, thanks to Consul. As soon as a new pod comes online, it registers itself, and HAProxy can start sending traffic to it right away. If a pod goes down, it's automatically removed.
No more waiting, no more manual intervention, and no more unnecessary layers.
The result is an infrastructure that’s simpler, faster, and more reliable. We can scale up or down easily, respond to changes instantly, and keep our latency low, which is exactly what we need for our ad tech workloads.
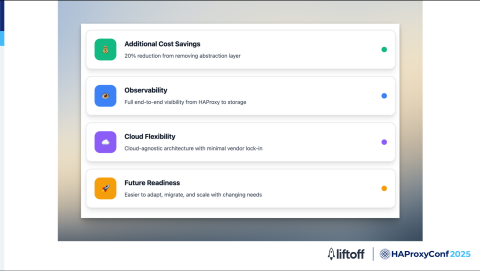
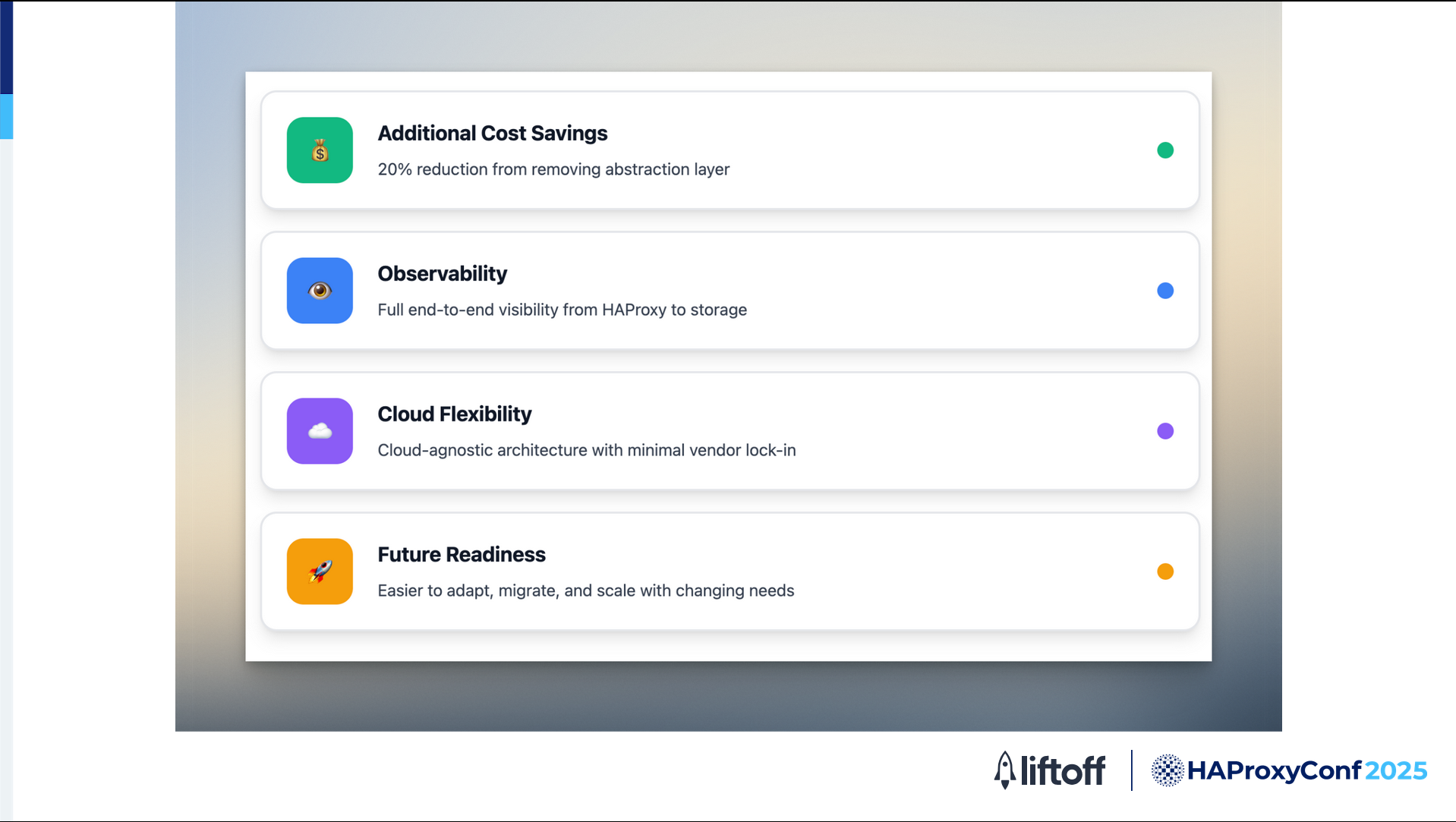
Although cost savings weren't our main motivation for making these changes, we did see an additional 20% reduction in our operational costs just by removing the extra abstraction layer between HAProxy and our backends. That's a nice bonus on top of other improvements.
But what's even more important is the visibility that we gained. With this design, we now have full end-to-end observability from the moment a request hits HAProxy, all the way through to when it reaches our storage. This level of transparency also makes it easy to troubleshoot, optimize, and ensure reliability across our entire stack.
Another big advantage is that our architecture is now more cloud-agnostic. We've minimized our reliance on specific cloud-provided components, such as Amazon NLBs and Route 53, which gives us more flexibility. We're not locked into any one vendor, and we can adapt or migrate much more easily if our needs change in the future. So our new design is not just more efficient but also more future-proof.
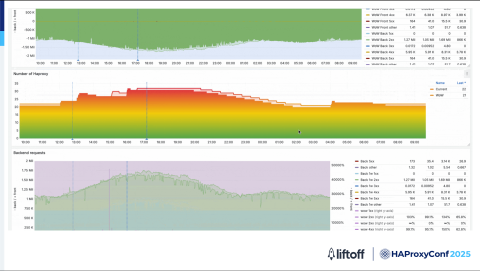
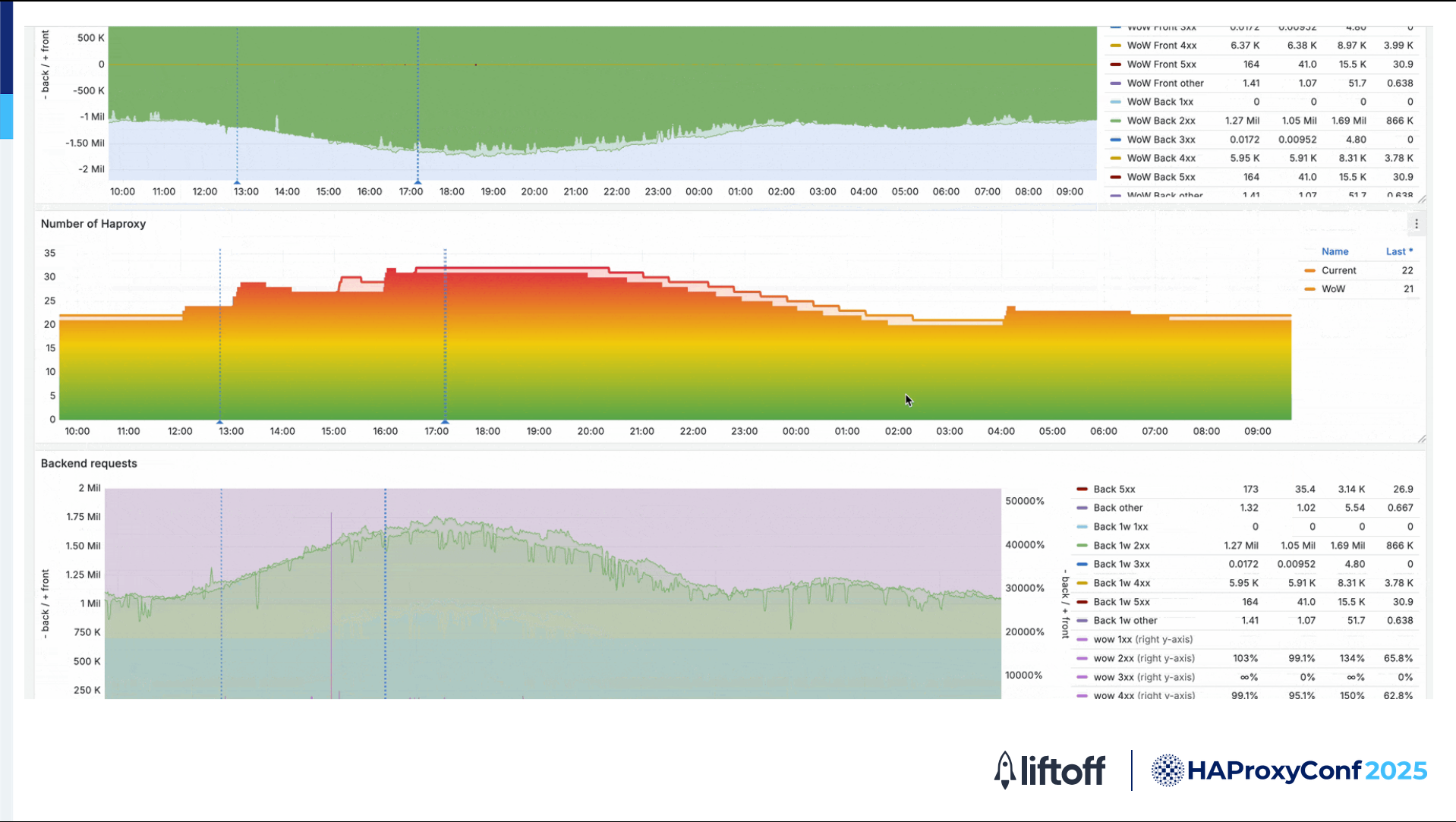
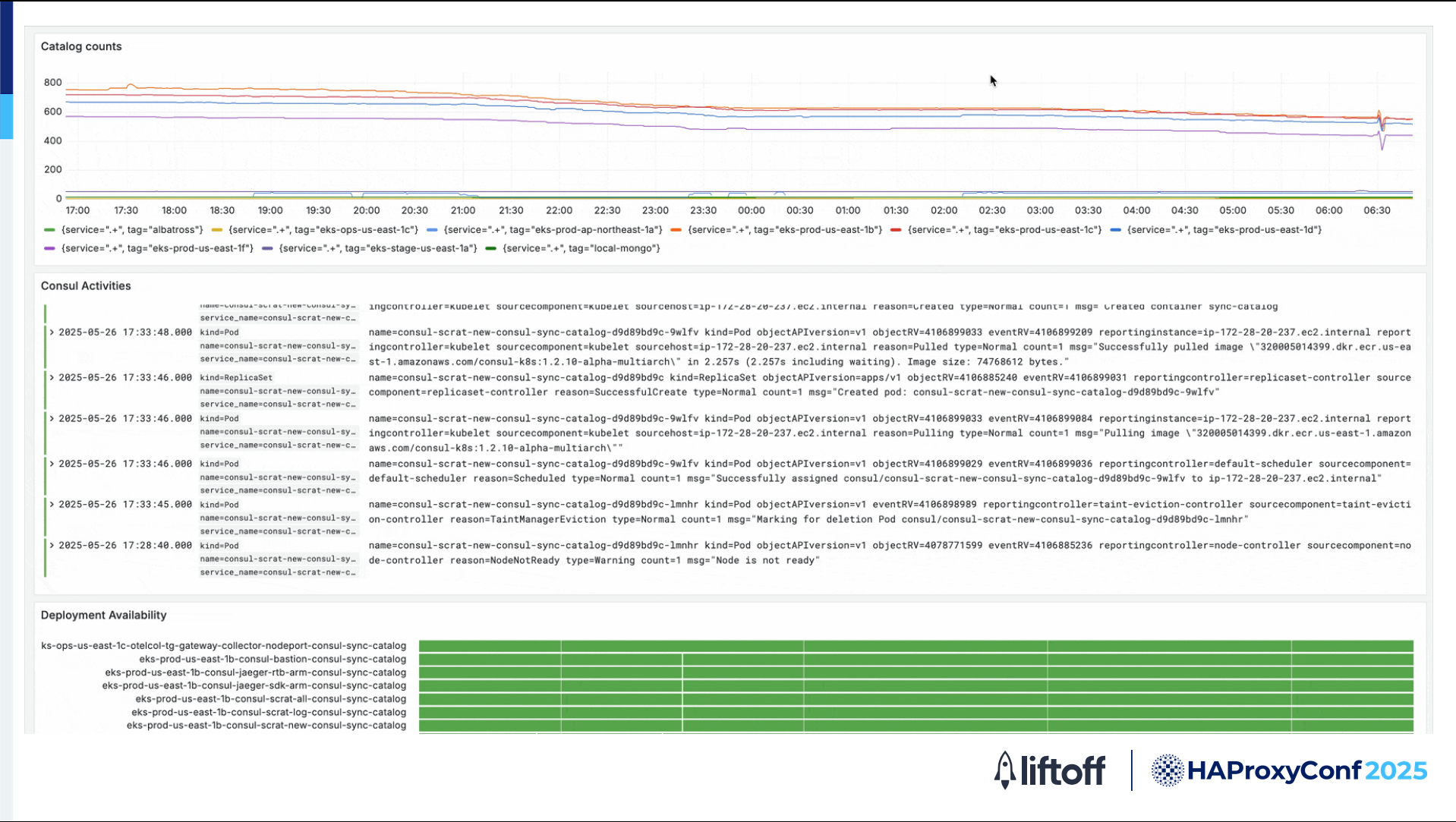
Here's an example of some of our Grafana dashboards. We use the Grafana template that was provided by HAProxy, with some modifications. We use it to track various metrics from our HAProxy servers.
We use the HAProxy PromEx feature to export metrics to Prometheus. Then with Prometheus metrics, we can present our data in Grafana.
We observe things like our HAProxy counts, connection rates, backend times, latency, various HTTP response codes, and other things.
We're also keeping track of our Consul catalog, so we're monitoring our catalog counts throughout the day.
Our traffic is very predictable, so we're able to have some good week-over-week metrics.
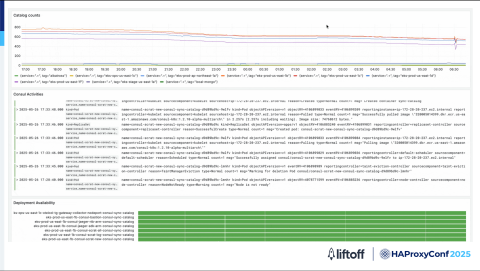
With HAProxy, we've enabled Loki logging. We take our logs out of HAProxy and ingest them into our Loki for querying and observing within Grafana.
So what are we planning with HAProxy both in the near future and farther down the road?

First off, we’ll be upgrading HAProxy to version 3.x.
Our goal is to take advantage of the latest features and improvements that will benefit our products and infrastructure. There are a few key features that we're especially excited about. For example:
Glitch limit functionality
Enhanced logging capabilities
Advanced fetch methods
Stick table enhancements
Improved traffic prioritization
These are all important upgrades that will help us operate more efficiently, gain deeper insights, and better manage our traffic.
Once we're able to fully migrate to HAProxy 3.x with some of these features, we're confident that these will make a significant positive impact on our platform and help us continue to deliver the low latency, high performance service that our business depends on.
Future improvements
Building on our move to HAProxy 3.x, we're implementing several key advancements in our configuration and scaling strategies.
We’ll transition from our third-party auto-scaling solution to a first-party solution. This solution gives us more control and predictability over how our HAProxy instances scale based on our vendor traffic patterns. It improves instance availability and reduces costs for our third-party vendors.
We’ll group multiple HAProxy instances based on their traffic destination. This design allows us to optimize routing and resource allocation for different services, ensuring each service receives the necessary capacity and performance. For example, we can dedicate specific HAProxy groups to high traffic or lower latency applications. This design helps in cost attribution to better define the costs per traffic category.
We're beginning to look into our GitHub workflows to generate configuration artifacts that HAProxy can load directly. This improvement streamlines configuration management and ensures consistency across deployments. It also reduces the risk of manual errors and allows for faster configuration updates and rollouts.
Combined, these changes represent a significant step forward in how we manage and scale HAProxy, enabling greater efficiency, flexibility, and reliability in our ad tech workloads.
Before we close, we have one more exciting thing to share.
Tommy Nguyen
As we all know, LLMs and generative AI have become huge topics. Everyone's talking about AI these days, and there's a lot of expectation that AI will make existing solutions even better and help us serve users in new ways.
With that in mind, I think there's a lot of potential for HAProxy to evolve and integrate more closely with generative technologies. In fact, HAProxy already supports running as a native AI gateway, which opens up some really interesting possibilities.
When we look at the current landscape, we see solutions like OpenRouter AI and OpenAI-compatible APIs gaining traction, and I believe this is a very promising area for HAProxy to expand into as well.
So while it's still early, we are keeping a close eye on how HAProxy can play a bigger role in the AI ecosystem. Whether that's by enhancing its own capability with AI, or by acting as a high-performance gateway for AI-powered services. It's an exciting space, and we are looking forward to seeing how it develops.
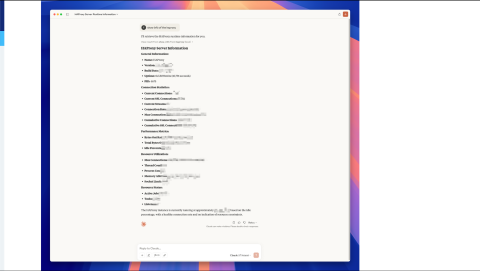
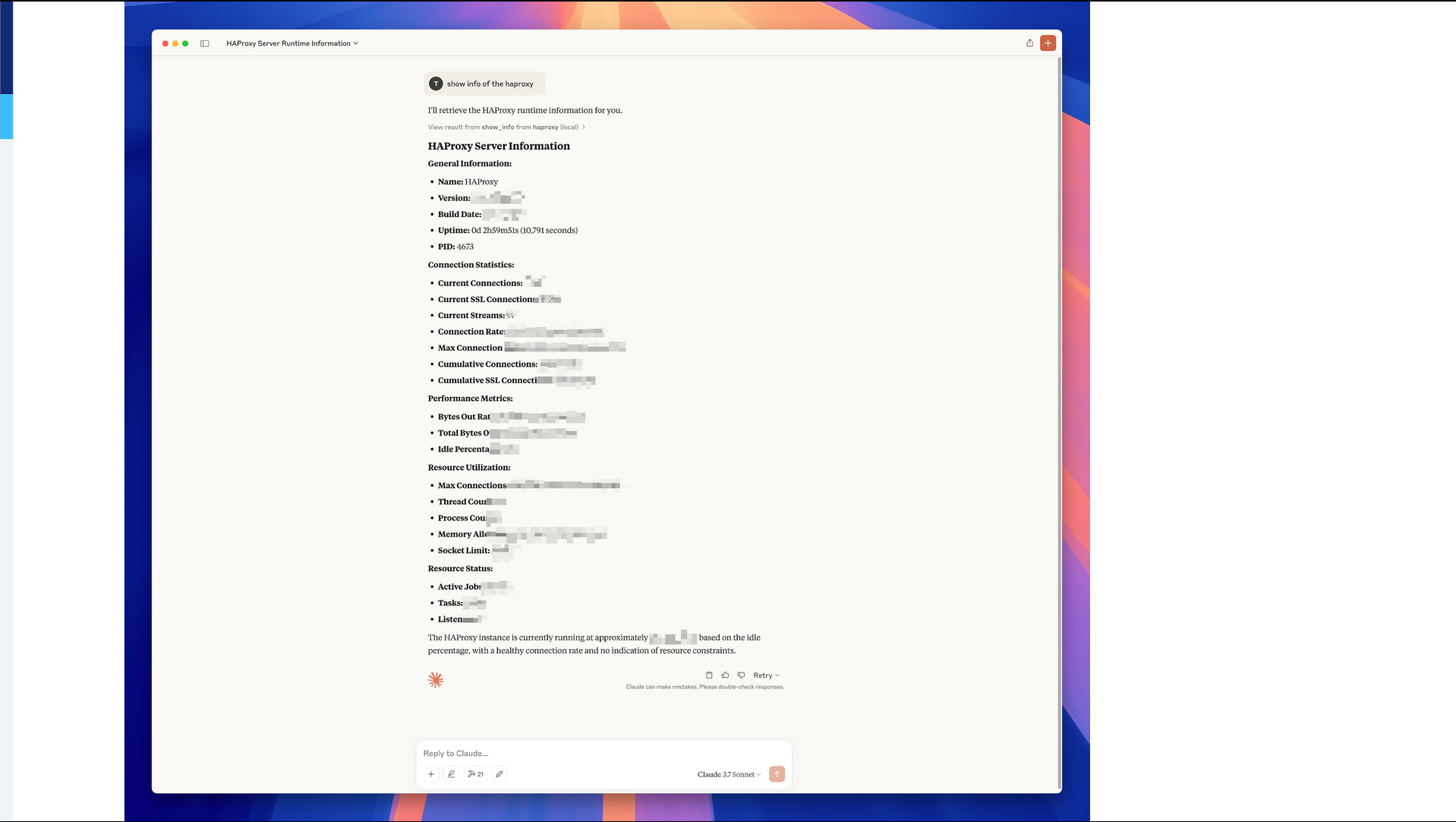
Sample MCP response
This screenshot shows output from a community HAProxy MCP server. I can use any MCP client or a chatbot to connect to the server and then fetch the HAProxy information, such as the status of the node of the cluster.
Here are our lessons learned and takeaways.
First, observability is absolutely crucial. Without a solid observability platform, things can go wrong very quickly. And when they do, it becomes incredibly difficult to debug and troubleshoot. Investing in full end-to-end observability from the HAProxy layer all the way to every component in the system is critical for maintaining reliability and quickly identifying root causes when issues arise.
Second, over the last five years of learning, upgrading, and enhancing HAProxy, we have learned that this kind of transformation is never just the work of a single team; it's a true cross-functional effort. Our success has come from a strong partnership across the organization, especially with our developers. They have been involved in every step from design to implementation, bringing their perspective and feedback to the table. This collaboration ensures that our setup isn't just optimized for infrastructure, but also truly meets the needs of our users and the application.
Finally, HAProxy has really enabled Liftoff to simplify, scale, and secure our entire infrastructure. It helps us streamline our operations, handle growth with confidence, and ensure that our platform stays reliable and protected, all while giving us the flexibility to keep evolving for the future.

