
Unlock peak load balancing performance with HAProxy! In this blog post, we'll explore how HAProxy intelligently harnesses the power of modern multi-core CPUs while navigating challenging architectural complexities like NUMA. Discover how HAProxy leverages optimized multithreading and provides automatic CPU binding to deliver both unparalleled efficiency and speed, ensuring your load balancing is faster than ever.
More cores, more problems
CPUs have changed dramatically during HAProxy's lifetime. Today's chips have many more cores and threads than those that were popular in HAProxy's early days. More cores and more threads mean my applications can run faster and process more data, right?
Not always. Let's take a moment to review some fundamentals and consider a few different processors from over the years.
From single-core to massively multi-core processors
In 2001 (the year HAProxy 1.0 was released), some of the best-selling processors for servers that year were the Intel Pentium III ("Tualatin") and the AMD Athlon MP (Multiprocessor). These chips had a single core and could handle a single thread of execution. "Threads", in computing terms, are a list of instructions for a CPU to execute. This is your program as it is executing. Each program run on the machine has its own set of instructions to execute. The operating system handles the work of coordinating the timing of each program's threads' executions on the core; the programs must take turns executing their instructions.
In 2005, the industry saw the introduction and more widespread use of dual-core processors, such as the Intel Xeon and AMD Opteron. Both of these processors, as well as others of the time, had two cores on the same chip. This meant that you could get the simultaneous processing power of a machine with two chips with only a single chip.
Multiple cores meant that you could execute multiple threads in parallel, with one caveat: the software had to be built to take advantage of the additional cores; it could not just use them automatically. Version 1.1.17 of HAProxy (2002) could take advantage of multiple processors on such a system by running multiple HAProxy processes in parallel. This was not without limitations, however, as data could not be shared across the processes, and some features could only be run in single-process mode.
Since then, the number of cores per chip has increased significantly, with even today's smartphones and workstations having six to twelve cores, often of varying computational capacity, in a single chip.
As for servers, the number is much higher today, with massively multi-core processors such as AWS Graviton, AMD EPYC, and Intel Xeon, which can have as many as 288 cores on a single system.
At this point, you must be thinking, "Surely by now, and with so many more cores, my programs must run so much faster, right?" To a large extent, yes, but variations in chipset architectures create a new set of challenges.
Multi-core NUMA CPUs: The challenges of massively multi-core systems and the importance of designing NUMA-aware software
Today's applications still face the same problems from decades ago: though today's processors offer more cores and more threads, applications must be designed to both efficiently and intelligently use the hardware in a multi-threaded way. If an application has only one thread of execution, it will run only on a single core; adding more cores produces no benefit.
However, simply making an application multi-threaded and allowing it access to all cores on a system is not sufficient, as not all CPU architectures operate the same way, and in some cases, adding more threads to operate on more cores can even cause performance degradation on some modern systems, as can often be the case on NUMA (Non-Uniform Memory Access) systems.
In these processors, cores are grouped into CCXs, or core complexes, where the cores that share L3 caches have the lowest latencies and are grouped together. Multiple CCXs may be colocated in a single CCD, or core complex die, and then one or more CCDs may make up a single NUMA node. The arrangement of cores, CCX, and nodes is referred to as CPU topology.
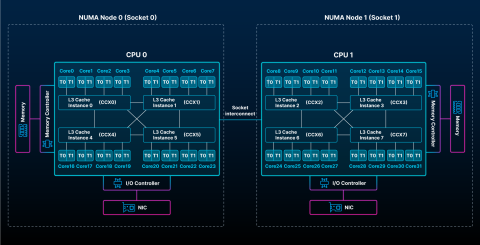
This diagram represents a NUMA system with a CPU topology consisting of 8 CCX and 32 cores, where each core has two threads.
NUMA CPUs achieve their best performance when data is shared only between closely located cores, as the data does not have to travel a long physical distance between cores. Since a CPU core can't directly modify data in memory, to process the data, it must first make a copy of it to its local cache. To do this, it must either transfer the data from memory or from another CPU core's cache, which uses up cycles it could be using to process the data, depending on how far the data must travel.
This latency for data copies is dependent on the characteristics of your CPU topology. At best, it may be under 10 nanoseconds, and at worst, it may be hundreds of nanoseconds.
But it's just nanoseconds we're talking about, right? Yes, but if your processing expectations are to successfully handle several million requests per second, every nanosecond matters.
How does HAProxy overcome the challenges of modern processors?
CPU topology dramatically affects how multithreaded applications perform. This means that to provide the best performance, HAProxy must be aware of your CPU topology. HAProxy automatically makes these considerations about your specific system:
How many cores do you have, and how are they arranged? (Operations between close cores will be the fastest.)
How many threads do you have? (How many operations can be executed in parallel?)
How can HAProxy intelligently organize its operations to make the most effective and efficient use of your hardware? (How can it minimize data transfers between distant cores and reduce the number of data copies in general?)
HAProxy uses this information to intelligently scale its operations on your hardware to provide the best performance. Its architecture embodies optimized multithreading, enabling it to provide effective automatic CPU binding.
Optimized multithreading in HAProxy
HAProxy has supported multithreading since version 1.8, and it can run on machines with any number and arrangement of cores. It achieves this by detecting the topology of your system, that is, the layout of your CPUs, CCXs, caches, and so on, and it uses this information to arrange its threads in a way that minimizes latency between threads.
In versions earlier than 3.2, HAProxy limits itself to the first NUMA node and does not automatically, that is, without additional, complex configuration, use the rest of the cores on systems that have more than one node. This is because, without additional restructuring of the core HAProxy components, benchmarking revealed that including more cores was counterproductive due to the latency associated with sharing data between distant cores.
Since version 2.4, HAProxy organizes its threads intelligently to minimize the sharing of data between cores that are very far from each other. Some data is shared between multiple threads (for example, server states, the next server to choose for round-robin, and statistics counters) and, therefore, must frequently be moved between cores. To reduce the distance this data must travel, HAProxy maintains multiple, independent copies of the data that stay local to groups of closely-located threads, which helps ensure that most data moves are fast, and keeps processing moving in parallel. Keeping data transfers local to closely located groups of cores enables HAProxy to utilize more nodes and potentially all available cores.
To make this possible, important restructuring and optimization efforts since version 2.4 include:
implementing zero-copy forwarding or "fast-forwarding" for data copies, which improves CPU cache performance
rewriting critical components so that they better scale with more threads by:
reducing latency by minimizing process-wide data sharing, limiting sharing to only groups of close threads, or "thread groups", when possible, and restructuring components to be thread-group-aware
reducing lock contention and improving atomic operations (these reduce the number of locks required)
Zero-copy forwarding
CPU caches allow CPUs to access frequently used data very fast, much faster than they can retrieve the data from memory (RAM). CPU caches can store a considerably smaller amount of data than can memory, and as such, data in the cache is constantly refreshed. This means that once new data arrives, the CPU must retrieve the old data from memory if it needs it again, which takes more time than if that data were still in the cache.
This process of replacing cache data, called cache eviction, requires that the CPUs spend time copying the data that they need, which increases the time it takes for threads to complete their execution. To minimize this execution time, minimizing cache evictions is crucial.
HAProxy accomplishes this using a mechanism called zero-copy forwarding or fast-forwarding. This concept of fast-forwarding helps prevent L3 cache evictions by avoiding additional buffering for data wherever possible. This reduces the number of times that data must be copied, and therefore, reduces the required number of CPU cycles.
HAProxy avoids excess buffering by only reading data when needed, determining how much data can be read directly from one network buffer (such as the server) to another (the client) without requiring intermediate buffering. Per connection, this significantly reduces both the memory required and the number of CPU cycles needed to copy data, as the data is read directly from one buffer to another.
The H1, H2, and QUIC muxes, which handle connection processing, fully support fast-forwarding. Applets, which are custom processing functions, and the cache also support fast-forwarding. This means these channels process connections and data with as few intermediate buffering steps as possible, which dramatically improves performance.
Better scalability with many threads
Thread groups, introduced in version 2.7, enable HAProxy to keep data local to only groups of close threads, which minimizes data transfer time between cores. In version 3.2, many critical components, including the round-robin and leastconn load balancing algorithms, received updates that make them thread-group aware, which improves scalability with more threads and overall performance.
Improvements to load-balancing algorithms
Before version 3.2, the round-robin load balancing algorithm operated by having all CPUs share the same index of available servers, which meant that the list had to be updated for every CPU with every request. Now, with support for thread groups, the round-robin load balancing algorithm is implemented such that each thread group maintains its own copy of the list. This means that other thread groups are not impacted by updating the copy of the index belonging to any one group, and can continue processing. Server properties, such as health checks and weights, are shared across all groups to maintain synchronization. Ultimately, this results in round-robin having much better scalability with more threads.
The leastconn load balancing implementation, which uses locking more frequently than the other algorithms, has had its memory model reworked with a focus on reducing contention. Leastconn, which tries to choose the least-loaded server, faces challenges because the number of connections to servers changes during the server selection process. The implication here is that the number of connections per server must be locked as each thread retrieves them, resulting in more locking contention. HAProxy manages this intelligently by arranging "bins" of servers grouped by similar numbers of active connections, from which the algorithm can randomly choose an equally eligible server. Benchmarks showed that by reducing this locking contention, the request rate doubled on a 64-core system.
For both of these load balancing algorithms, this ultimately means that HAProxy can choose the appropriate backend server for routing traffic more quickly, thereby significantly improving request processing time.
Reduced lock contention
As for locks, which are required for multithreaded applications to ensure data integrity when the same data is accessed by multiple entities (threads), the fewer locks that are required, the faster data can be processed. When a resource (some data) is locked, it can't be used by any entity other than the one that locked it. The other entities must then wait their turn, which slows processing. Many of the improvements in version 3.2 focused on reducing lock contention by restructuring components such that they are thread group-aware, which limits the number of threads that need to acquire any particular lock. Additionally, the locks in many critical components are now implemented with exponential backoff, which is a mechanism by which threads retry to obtain locks that reduces thread congestion and helps prevent system overload.
Atomic operations improve lock contention as well, as they reduce the amount of heavy locks required. Available atomic functions vary per system architecture, and the most recent HAProxy versions include updates that use the most performant atomic functions when they are available. HAProxy's lockless memory pools use atomic functions to manage memory allocation and deallocation, which further reduces the overhead for these operations.
Queues, cache, SPOE engine, and stick table improvements
As of version 3.2, queues are arranged by thread groups and favor group-local pending requests for short bursts in order to eliminate the heavy locking contention between distant CPUs. Queues were previously very CPU-intensive because of the cost of data sharing between distant CPU cores when there was only a single list for all threads. This is quite similar to what was already done for persistent connection management. Additional improvements have been made to the HTTP cache, resulting in significantly less lock contention. The SPOE engine was completely rewritten in version 3.1 to benefit from a mux-based architecture, allowing idle connection sharing between threads and per-request load balancing.
Stick tables have seen several recent improvements as well, including significantly reduced lock contention during updates from peers, and locking that scales much better with threads, as lookups are now disentangled from peer updates thanks to fixes regarding cache line sharing. Stick-tables are now sharded over multiple tree heads that each have their own locks, which also significantly reduces locking contention on systems with many threads. The need for stick-tables to efficiently broadcast every change to all connected peers in itself represents extremely difficult challenges. There have been several redesign attempts, and developers are working on further improving this; expect news on this front coming in versions 3.3 and 3.4
Automatic CPU Binding
With all these updates and multithreading optimizations, how do you configure HAProxy to fully utilize your hardware resources? In version 3.2, it's just a simple and portable configuration directive. Add the following cpu-policy to the global section of your configuration:
global
cpu-policy performanceWhen set to performance, HAProxy will enable all threads and organize them into thread groups that reflect the layout of your CPUs, and assign them to groups of appropriate CPUs. This is often referred to as CPU affinity, CPU pinning, or CPU binding. While you can still manually assign your CPU affinity, HAProxy offers several cpu policies to help you build configurations that are automatic and portable.
Here is an example of a system with a single NUMA node with 4 CCX. Each CCX has 8 cores that share a single L3 cache. In version 3.2, when no cpu-policy is set, HAProxy defaults to cpu-policy first-usable-node, wherein a single NUMA node is used with a single thread group with as many threads as there are available CPUs. This means that all CPUs can share data with each other, regardless of their locality, which may not always be the most performant configuration.
Run HAProxy with the -dc argument to see how it has arranged its threads on your CPUs. For this particular example, it produces the following:
Thread CPU Bindings:
Tgrp/Thr Tid CPU set
1/1-32 1-32 32: 0-31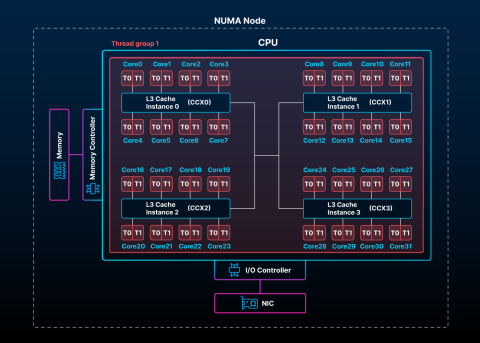
When the cpu-policy is set to performance, four thread groups are enabled, one per CCX, and each group of threads is localized to one CCX. This means that the threads of each group will work together within their own group for the vast majority of processing tasks, thus reducing the latency between threads belonging to different CCX:
Thread CPU Bindings:
Tgrp/Thr Tid CPU set
1/1-8 1-8 8: 0-7
2/1-8 9-16 8: 8-15
3/1-8 17-24 8: 16-23
4/1-8 25-32 8: 24-31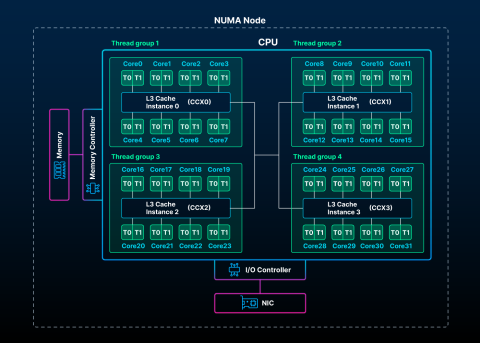
On a system with both performance and efficiency cores, HAProxy will use only the performance cores when using this cpu-policy. Likewise, if you would like to minimize HAProxy's CPU usage on such systems, you can set it to efficiency, and it will only use the cores with the least capacity, perhaps to leave the performance cores for other applications. This is an important consideration when using HAProxy as a sidecar next to your applications, as HAProxy's CPU usage will be minimal.
Be sure to test this configuration before implementing it in production to ensure that it indeed provides better performance and doesn't conflict with any other CPU affinity settings you may have for other applications. Also, you should not add this directive if you are already manually assigning CPU affinity using nbthread, thread-groups, and cpu-map, as these settings conflict with each other, though you can use the new settings to replace your existing configuration.
For more information, including important considerations and instructions for analyzing your system and configuration, see our configuration tutorial. This tutorial addresses potential performance issues you may encounter, and explains possible solutions for the versions of HAProxy that support thread groups (versions 2.7 and higher). There are also options for tuning the automatic binding in version 3.2 onwards, should you want finer-grained control of which CPUs HAProxy will use.
Real-world performance improvement
Want to see a real-world example of HAProxy's CPU affinity settings in action? Check out Criteo's talk at HAProxyConf 2025. In his talk, Basha Mougamadou walks you through how, with only a few configuration directives, they tuned HAProxy's CPU binding settings using HAProxy 3.2 for their specific use case on AMD EPYC 7502P Zen 2 processors, resulting in a 20% decrease in their CPU usage with the same level of network traffic, thanks to HAProxy's more efficient use of the CPUs in version 3.2. This leaves more CPU available for other applications, including the kernel.
Conclusion
Modern CPU architectures, optimized to maximize total per-chip throughput, present challenges for multithreaded applications. Through automatic CPU binding and intelligent thread management, HAProxy turns these challenges into strengths, while still maintaining its original principles that technically complex features must remain easy to configure.
Combined with optimizations in the most recent versions of HAProxy, including zero-copy forwarding, reduced lock contention, exponential backoff in locks, and important improvements to queues, load balancing algorithms, memory pools, and other core components, HAProxy can efficiently and effectively leverage the power of modern CPUs, no matter the scale.
For the ultimate HAProxy experience, upgrade to HAProxy One – the world's fastest application delivery and security platform, consisting of HAProxy Enterprise, HAProxy Fusion Control Plane, and HAProxy Edge. It combines the performance, reliability, and flexibility of our open source core (HAProxy) with the security, observability, and orchestration capabilities of a unified enterprise platform.





