
Weller Truck Parts is the largest heavy-duty truck parts remanufacturer in North America. With 46 locations, over 1,150 employee-owners, and two on-premises data centers in Grand Rapids and Indianapolis, the company runs a complex infrastructure that its people depend on every day.
In a presentation at HAProxyConf, Austin Ellsworth, Infrastructure Manager at Weller, shared how he leads the team responsible for servers, storage, firewalls, and networking. His goal was to ensure that infrastructure never gets in the way of the business.
That goal led him to a months-long project centered on the HAProxy One application delivery and security platform. By leveraging HAProxy Enterprise load balancer for high-performance application delivery and HAProxy Fusion Control Plane for centralized management and observability, Ellsworth established an active-active data center architecture capable of failing over in under a second.
Why traditional data center failover takes hours
Weller’s primary users are its own associates. Employees use virtual desktops to log into the enterprise resource planning (ERP) system, take orders, and manage production. When something goes wrong, the people on the floor feel it immediately.
Traditional data center disaster recovery treats the secondary site as a cold standby. Backup appliances are "easy to go out and buy," and storage replication is simple to set up, but spinning up a workload after a disaster could take as much as four hours. For Weller, the reality of this previous cold-site approach meant that if the primary site went down, the business could wait hours for a full recovery.
Ellsworth knew this setup would not deliver the most value. “I didn’t really feel that that was an efficient use of our resources,” he said. “I didn’t think we were netting our company the most profit or serving our users the best.”
He wanted to move every application he could to an active-active model, where both data centers ran identical workloads simultaneously. The only problem was with routing. If both sites were live, something had to decide where to send users and how to react when a site went down.
Choosing the right routing approach
When deciding on the best path forward, the team considered several options. VMware Site Recovery Manager and Zerto were on the table, but both tools worked more like recovery mechanisms than live traffic managers. Conducting a failover with those products still involves taking storage offline at one site and bringing it online at another before anything can run. That process takes time that the business did not have to spare.
DNS was briefly considered, but a colleague quickly talked Ellsworth out of it. Local DNS caches and propagation delays make it an unreliable tool for fast failovers.
The approach that made sense was Anycast BGP. Large companies use it to direct traffic at the network layer with no dependency on DNS and no manual switching. The routing table itself determines the path, and when conditions change, it updates.
That meant Weller needed a load balancer that could inject routes into the network based on the health of backend servers. HAProxy Enterprise, with its Route Health Injection (RHI) module, was the answer.
“HAProxy Enterprise was not only the fastest, but it also seemed like the easiest to configure," Ellsworth said.
Read more:
Building the active-active architecture
The implementation began by replacing a software-defined wide-area network (SD-WAN) solution and migrating all branch locations to next-generation firewalls. Every network component in both data centers runs open routing protocols, specifically open shortest path first (OSPF) and border gateway protocol (BGP), giving teams full control over traffic paths.
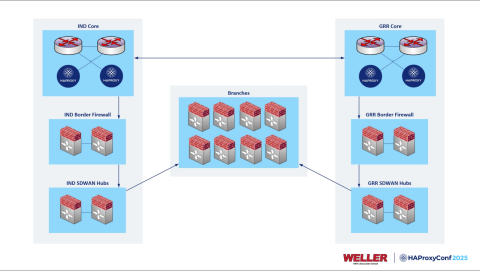
Ellsworth peered the HAProxy Enterprise nodes directly to the core routers at each data center using the HAProxy Enterprise Route Health Injection (RHI) module. OSPF handles loopback reachability between the load balancers and the cores, while the RHI module uses BGP to communicate real-time route health information.
A modernized Route Health Injection (RHI) module was introduced in HAProxy Enterprise 3.2 to calculate and sync routing states inside a single file configuration. It achieves this by seamlessly interfacing with the underlying network stack and native protocol daemons, ensuring network-layer routing is always perfectly synchronized with real-time application health.
Each HAProxy frontend runs the same IP addresses at both sites. When HAProxy Enterprise detects that servers in a backend pool are healthy, the RHI module injects those Anycast routes into the BGP peer. Both data centers advertise the same prefixes. The network chooses the closer path using BGP path selection, with the autonomous system (AS) path prepending used to create a preference for the primary site.
To speed up failure detection, the team enabled bidirectional forwarding detection (BFD). While HAProxy handles application-layer health checks, BFD covers physical network paths. Standard BGP can take up up to 180 seconds to detect a peer going down, but BFD brings that down to 100 milliseconds.
All applications, whether they had multiple backend servers or just one, were positioned behind HAProxy Enterprise. Even single-server deployments benefited from route health injection. If that server goes offline, the route disappears, and traffic automatically shifts to the other data center.
Subsecond data center failover demonstrated live
Ellsworth ran an impressive live demonstration in Weller's production environment.
His demo script sent a GET request once a second to a web application behind HAProxy Enterprise. He disabled the connection servers on VMware Horizon, the company's VDI platform, and let HAProxy Enterprise's health checks detect the service-level failure.
Within moments of the health check tripping, the RHI module stopped injecting the Grand Rapids route, signaling the network to withdraw the path. For immediate physical network or link-layer failures, the team paired this setup with BFD, which drops peer detection down to 100 milliseconds. Combined, these two layers ensured that traffic shifted to Indianapolis instantly
Not a single GET request was missed.
Employees connecting to virtual desktops were redirected to the secondary VDI pool, with all their user data intact and synchronized in real time using FSLogix Cloud Cache.
From the user's perspective, nothing happened.
The same shift in traffic can be achieved during planned maintenance. The team can now take a server offline during business hours, patch it, and bring it back up at the other site without scheduling overnight windows or asking anyone to stay late.
Managing the solution at scale with HAProxy One
To manage this infrastructure at scale, Ellsworth’s team runs HAProxy Fusion, which provides centralized management, observability, and automation for large-scale HAProxy Enterprise deployments. With HAProxy Fusion, all HAProxy Enterprise nodes across both data centers are managed from a single interface, with log data aggregated in a single location.
“It simplifies your life,” Ellsworth said.
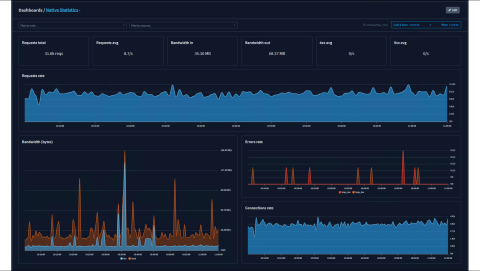
Before HAProxy Fusion, log analysis meant grepping through text files. HAProxy Fusion’s Request Explorer feature eliminated that cumbersome process, tracking transaction variables and HTTP metadata. When users of a newly migrated application started getting signed out intermittently, Ellsworth utilized the logging system and the WAF Profiles engine to immediately isolate the precise firewall blocking events and matching rules. What might have taken hours to track down took minutes.
HAProxy Enterprise and HAProxy Fusion are part of HAProxy One, the world’s fastest application delivery and security platform. For Weller, the combination means a high-performance data plane at each site and a unified control plane to manage and monitor everything across both.
Small team, big ROI
Ellsworth ran the numbers on what an equivalent cloud deployment would cost. His estimate came out at $90,000 to $100,000 a month in compute alone, which would be enough to rebuy the on-premises hardware twice a year. The ROI case, he said, was straightforward.
All this was possible with only a small team. Ellsworth and a team of four physically visited all of Weller's branch locations, swapped network hardware, migrated subnets, deployed the load balancers, and tested applications. They completed the entire rollout in under six months.
"You don't have to be a giant organization to be able to deploy something like this," Ellsworth said. "And you don't have to be massive to benefit from it either."
The result is world-class application delivery infrastructure that automatically handles failures, patches during business hours, and scales cleanly.
Want to see what subsecond data center failover looks like for your own infrastructure?
FAQs
What is a data center failover?
Data center failover is the automatic redirection of traffic from a primary data center to a secondary one when the primary becomes unavailable. Traditional approaches treat the secondary as a cold site that takes hours to spin up. Active-active failover, by contrast, runs identical workloads at both sites simultaneously and shifts traffic in seconds or, as Weller Truck Parts demonstrated, in under a second.
How is data center failover different from an outage?
An outage is the underlying failure, while a failover is the engineered response that keeps that failure from reaching the user. The distinction matters because most infrastructure investment focuses on preventing outages, when the real measure of resilience is how quickly the system absorbs one. Done well, failover means an incident at one location never becomes an incident for the business.
How do you test data center failover?
The only credible test is a live one in production. At HAProxyConf, Weller demonstrated this directly: a script sending one GET request per second against a live application while the team disabled the primary site. HAProxy Enterprise health checks caught the application failure, the Route Health Injection module withdrew the route from the BGP table, and traffic shifted to the secondary data center. Not a single request was missed. Pairing scripted synthetic monitoring with planned production failovers is how teams confirm the architecture behaves the way the diagram promises.
What's the biggest challenge with data center failover?
Routing. Storage replication and backup tooling are mature and easy to buy. The hard problem is deciding where to send users when both sites are live and reacting quickly enough when one fails. DNS is unreliable for fast failover because of caching and propagation delays. Recovery products such as VMware Site Recovery Manager and Zerto are designed for disaster recovery, but not for live traffic management. Anycast BGP solves the routing problem at the network layer, which is why Weller built its architecture around it.
Subscribe to our blog. Get the latest release updates, tutorials, and deep-dives from HAProxy experts.



