
Ensuring high uptime and seamless failover for critical applications is a top priority for businesses. What happens when your primary users are internal stakeholders, and a moment's downtime can impact productivity and revenue? For companies with on-premises data centers, achieving subsecond data center failover is a challenge that requires innovative solutions.
In this presentation, we'll see how Weller Truck Parts overcame this challenge using HAProxy Enterprise to implement a world-class architecture for availability and failover. We'll dive into the business-related decisions behind this project, the technical implementation, and the benefits of using the HAProxy Fusion Control Plane. You'll learn how to configure HAProxy Enterprise for subsecond data center failover, maximize IT budget efficacy, and improve infrastructure reliability.
Whether you're a seasoned IT professional or looking to optimize your data center infrastructure, this article will provide valuable insights into implementing a robust and scalable solution for high availability and disaster recovery.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.






























My name's Austin Ellsworth from Weller Truck Parts. I run the infrastructure team there, where we manage everything related to servers, storage, firewalls, and networking, so you can see how HAProxy fits in there. I'm excited to talk about our most recent project, which I'm very passionate about: subsecond data center failover. It's how we are revolutionizing our team's uptime using HAProxy.

The plan for this talk: I'm going to go into some of the business-related decisions behind this project, and I'm also going to show you how we implemented it. We'll do a technical overview and dive into some of the configuration. If this seems like a deployment that might fit your company's architecture and model well, I will show you how to do that in about 12 slides. We also have a couple of really cool demos that I'm excited to show today. One of them will be a live demo in our production environment.

A little bit about Weller Truck Parts.

We are the largest heavy-duty truck parts remanufacturer in all of North America. We provide some of the largest freight companies with differentials, transmissions, steering gears, driveshafts, and we're different from just having rebuilt components. We have teams of highly skilled tradesmen; instead of just replacing worn items within these components, they get taken down all the way to their cores. We have transmissions that OEMs (Original Equipment Manufacturers) like Allison will make updates to over several decades of tuning that platform. We'll throw the old cores into our CNC (Computer Numerical Control) machines, make those updates ourselves, and provide our customers with a product that beats OEM specifications.
We have around 46 locations, including storefronts, distribution centers, and manufacturing facilities. We also have a little over 1,150 employees and all are associate owners at Weller Truck Parts. Fun fact: we're the 27th largest ESOP (Employee Stock Ownership Plan) in the US. So what that means is that when anybody in the company can find ways to reduce downtime, improve efficiencies, or save money, all of us benefit from it.
Regarding the infrastructure perspective, we are heavily on-prem with about 99%-98% of our workload existing on-prem in two data centers. We have around 1,200 cores and 16 terabytes of memory, so we're not very large compared to many other companies that have shared some interesting stuff in the past few days.
Our primary users of our data centers are our coworkers. We have a couple of public-facing applications, like an API that we use to pull data into our website, check availability, and take orders. But for the most part, they serve each other, the associates at Weller Truck Parts.

The problem that we're running into is one that many companies with an architecture like ours run into, where your primary users are everybody inside the company. You have on-prem data centers. Getting comfortable with your secondary data center is easy, and many people leave it as a cold site. I think it's easy to go out and buy: there are many options for top-of-the-line backup appliances, and you can do storage replication and slap a plan together for doing restorations, maybe test it and find that it takes 30 minutes, an hour, or four hours to do a recovery in an emergency.
But I didn't really feel that that was an efficient use of our resources, and I didn't think that we were netting our company the most profit or serving our users the best. So I wanted to move to an active-active workload for every application we could.
Still, I was running into the question: if we run an identical workload at both data centers, how do we efficiently monitor them, and how do we direct users to the correct data center?

Naturally, we use the load balancer.

Some of the decisions and questions we discussed before settling on the load balancers are: what other companies were doing, and checking options that make this pretty easy, like VMware Site Recovery Manager or Zerto.
The big issue with those traditional products is that they are like a recovery mechanism, so you're still going from data center A, maybe marking your storage offline at data center A, marking it active at data center B. Then you can boot up and write to those volumes and use that workload. So the failover process is far from instantaneous with those solutions.
A bad idea I had when we were brainstorming this about a year ago was to solve this problem with DNS, and a very bright colleague of mine stopped me. Not that anyone ever has issues with DNS, but it didn't seem like the cleanest way to handle it.
We asked ourselves: what are other large companies doing to handle this problem? Now, I know, for example, Netflix places all its nodes at the edge of the Internet, and they peer directly through Internet exchanges and use Layer 3. That was one of the most efficient ways to do this. Strongly looking at Anycast DNS, and that's what we ended up settling on.
We had to ask ourselves: what happens if the data center goes offline? Are we going to be depending on resources at any specific data center? What's the behavior if those are down? We wanted to ensure that whatever solution we chose could scale easily and minimize the opportunity for more human failure.

I didn't know this was a meme local to West Michigan. We had some protesters downtown one day, and this just kind of turned into a meme template.

Our goal: we wanted to implement a world-class architecture for availability and failover, but I wanted to ensure that over the next 10 years, we didn't have to redesign this and re-architect this over and over.
We had some flexibility to put any workload we wanted behind the solution. The big ones are VDI (Virtual Desktop Infrastructure) and REST APIs. However, having the flexibility to take any Layer 4 application and put it behind the solution was important to me.
I also didn't want a human sitting in the driver's seat to conduct a failover, so that we could leverage things like health checks and make those decisions automatically, and spend our time investigating the root cause and alerts instead of ensuring the traffic moved over.
Lastly, I wanted to maximize the efficacy of our IT budget. We looked at quite a variety of load balancing solutions, and I was really shocked at some of the pricing. When we were able to land with HAProxy and get HAProxy Enterprise with HAProxy Fusion, we had ample funds left in the budget to focus on other critical components like routers and firewalls.

Let's get into the implementation and see the solution we came up with.

We began with an SD-WAN (Software-Defined Wide Area Network) solution that gave us some problems, so we had a prerequisite to eliminate that, and we migrated all of our locations to next-gen firewalls. We ensured that all the network components we were introducing into our data centers would use open routing protocols, so we would get the most control and flexibility possible using things like OSPF (Open Shortest Path First) and BGP (Border Gateway Protocol).
We peered our HAProxy Enterprise nodes directly to our core routers at both data centers, then used the RHI (Route Health Injection) Module to inject Anycast BGP into the network. We're having frontends for identical workloads at both data centers, and they're the same IP addresses that can be reached with multiple paths.
Next, we managed the solution with the HAProxy Fusion Control Plane. It simplified much of the configuration and monitoring, and things like HAProxy Fusion Request Explorer have been amazing.
Then we wanted to add all the workload to the solution, whether or not we were actually load balancing the backend and placing multiple servers in the backend for scaling. If it were a single server, we would still put it behind HAProxy Enterprise to get that route health injection.
Lastly, we didn't want to reinvent the wheel. Anywhere possible in the backend, we leveraged native clustering technologies like DFSR (Distributed File System Replication), Windows failover clustering, and SQL clustering. That has simplified the actual failovers between the two data centers.

The benefits of the solution we came up with are that we can respond more rapidly to data center issues at the network level. We don't have to sit and manually click buttons and monitor, ensuring workloads move between the two sites.
It also significantly eases patching. We can take a server down in the backend during the middle of the day, patch it, bring it back online at the opposite data center, monitor it, and then move on to the next one. No one has to stay up until midnight anymore to update those.
Putting the servers behind HAProxy Enterprise also gave us the benefits of HAProxy Fusion and improved monitoring.
If you've used things like Nginx, Apache, or IIS (Internet Information Services), I think most people can probably agree that all those native logging mechanisms are atrocious. It's a pain to grep through text log files. When you're able to visualize them, it just makes it a lot easier to understand what's going on.
The last benefit of the solution, which has been huge for us, and I've heard quite a few other customers mention it today, is that the support team with HAProxy Technologies is just amazing.
I think many people in this room are familiar with the same old song and dance, where you go out and buy some fancy new product, and it may cost hundreds of thousands or even millions of dollars, depending on scale, and you run into your first issue. You open a ticket with the vendor, and it just takes weeks to escalate the ticket to someone who knows what they're doing. And it's probably the worst part of my job when that happens. But every time I've opened a ticket with HAProxy, I've been met with some of the smartest, most intelligent people I've interacted with. They've got great knowledge of how the product works and all the underlying systems in Linux and IP tables. We've been able to resolve issues very rapidly, and they've been patient enough to help me even with stupid questions sometimes.
This is a brief overview of how we use HAProxy Fusion here.
If you're not using it already and you're using HAProxy Enterprise without the HAProxy Fusion Control Plane, I highly recommend upgrading and using it.
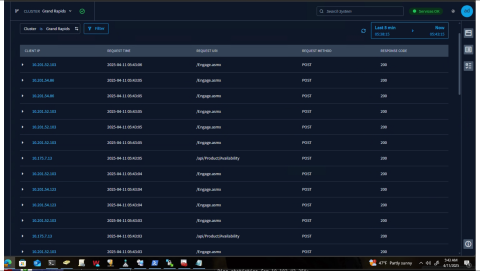
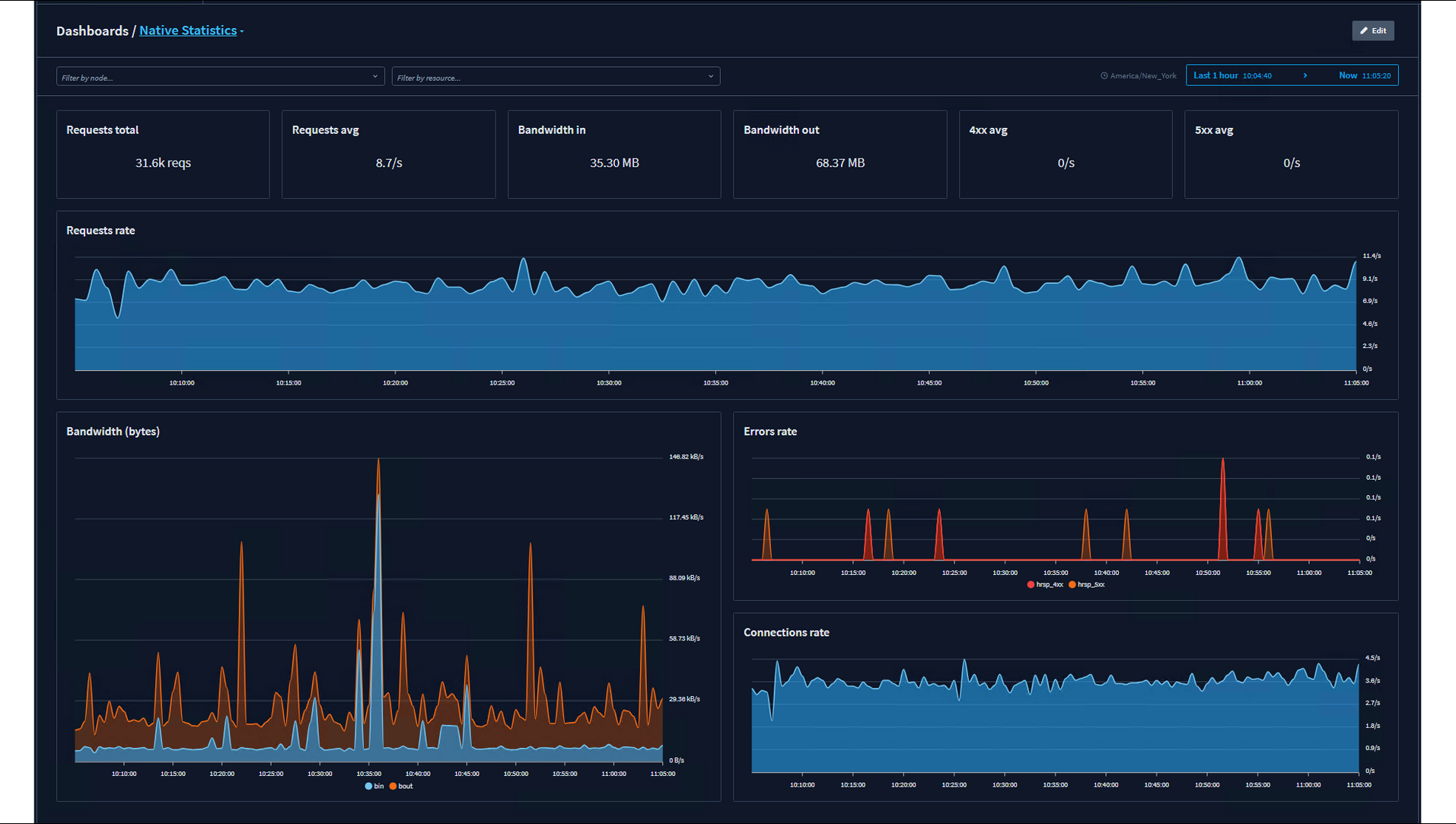
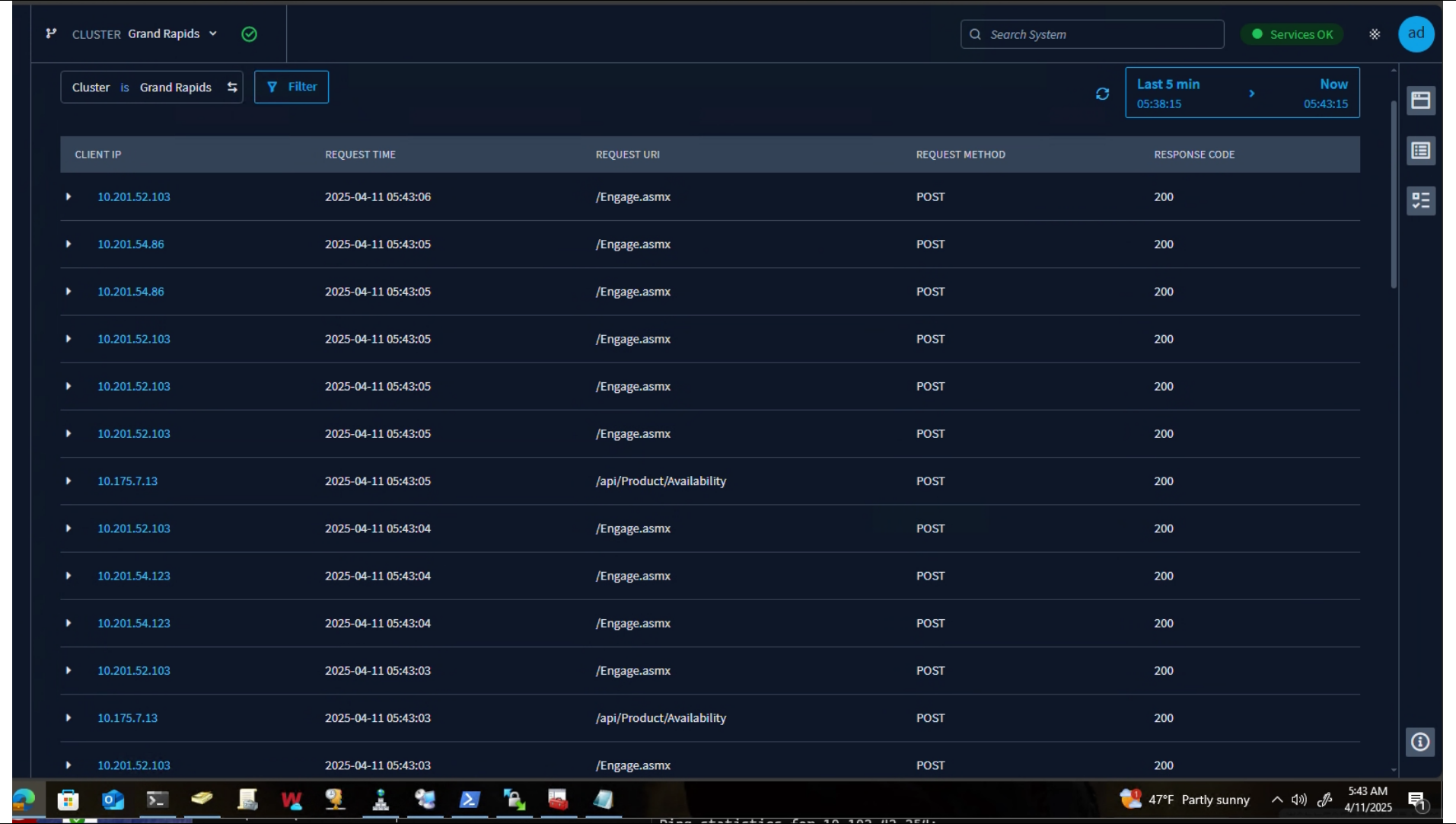
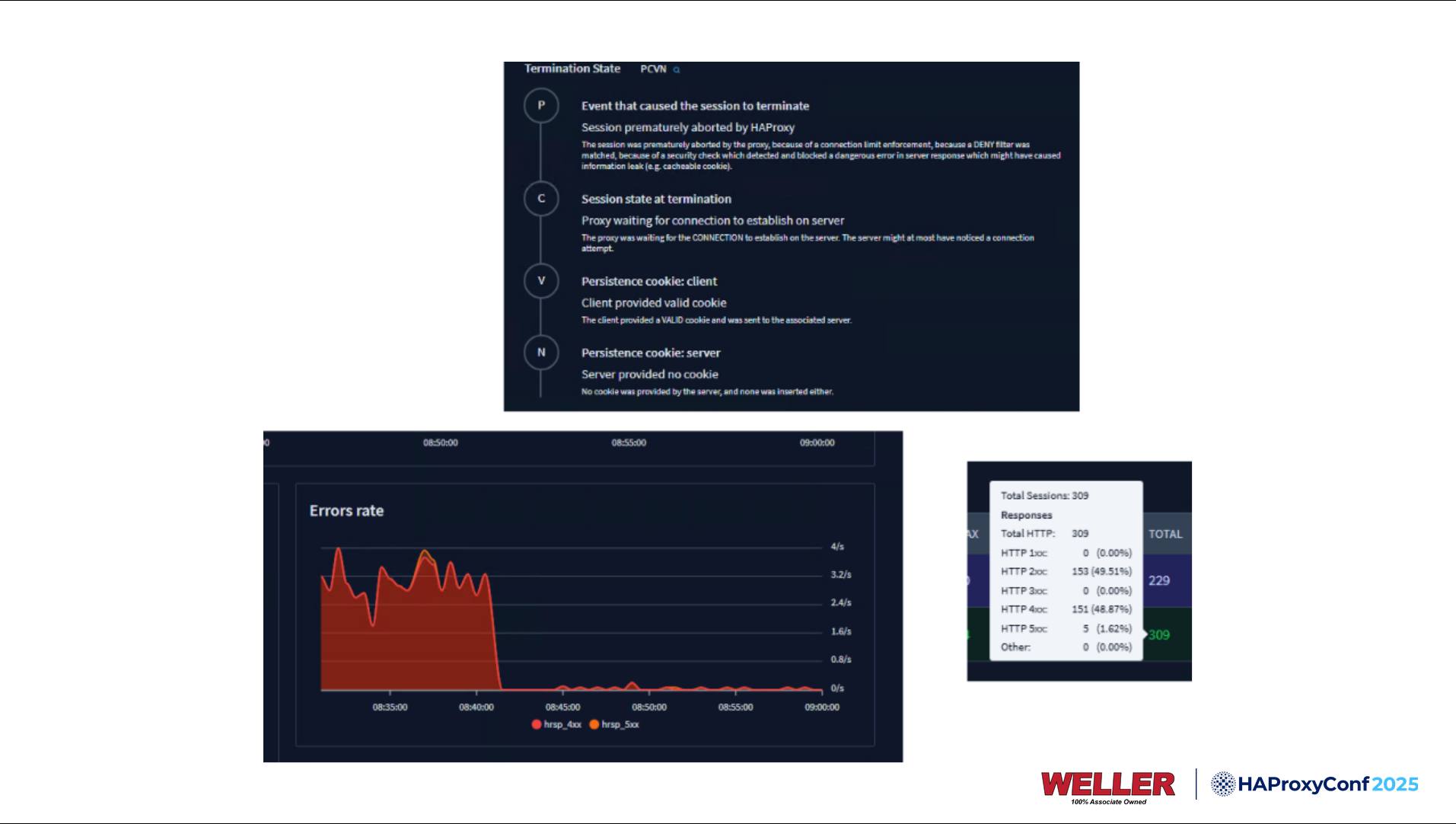
I will show you what we typically see in our Request Explorer, which is something like this: on the right-hand side, you'll note that everything's hunky-dory. We got response codes 200 on all of our API calls. But one morning, I migrated another one of our web applications. It runs on iPads. I migrated it behind the load balancers, and users were getting intermittently signed out. We had the web application firewalls turned on because they come with HAProxy Enterprise, so why not?
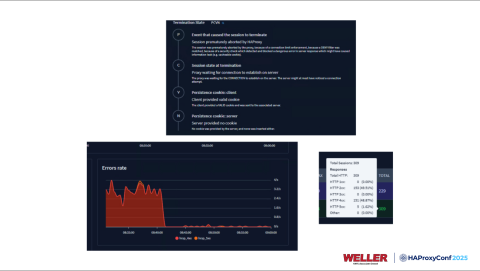
I noticed that when this issue occurred, we were really quickly able to see what the cause of the problem was. We were hitting a deny filter on a web application firewall. So, trying to understand what's actually going on inside your applications takes a lot less time when you have resources, graphs, and beautiful layouts that show your termination states like this.

Now, if you're anything like me, you would much rather discuss technical matters than business-related decisions.

I want to go into the configuration here. I will show you in very few slides that you don't have to be a mega-billion-dollar company or a FAANG company to have world-class availability within your applications and network. A team of four and I were able to physically go to all of our branch locations, swap network hardware, migrate subnets over, deploy the load balancers, and test applications in under six months. So they make it pretty easy to use the HAProxy products.

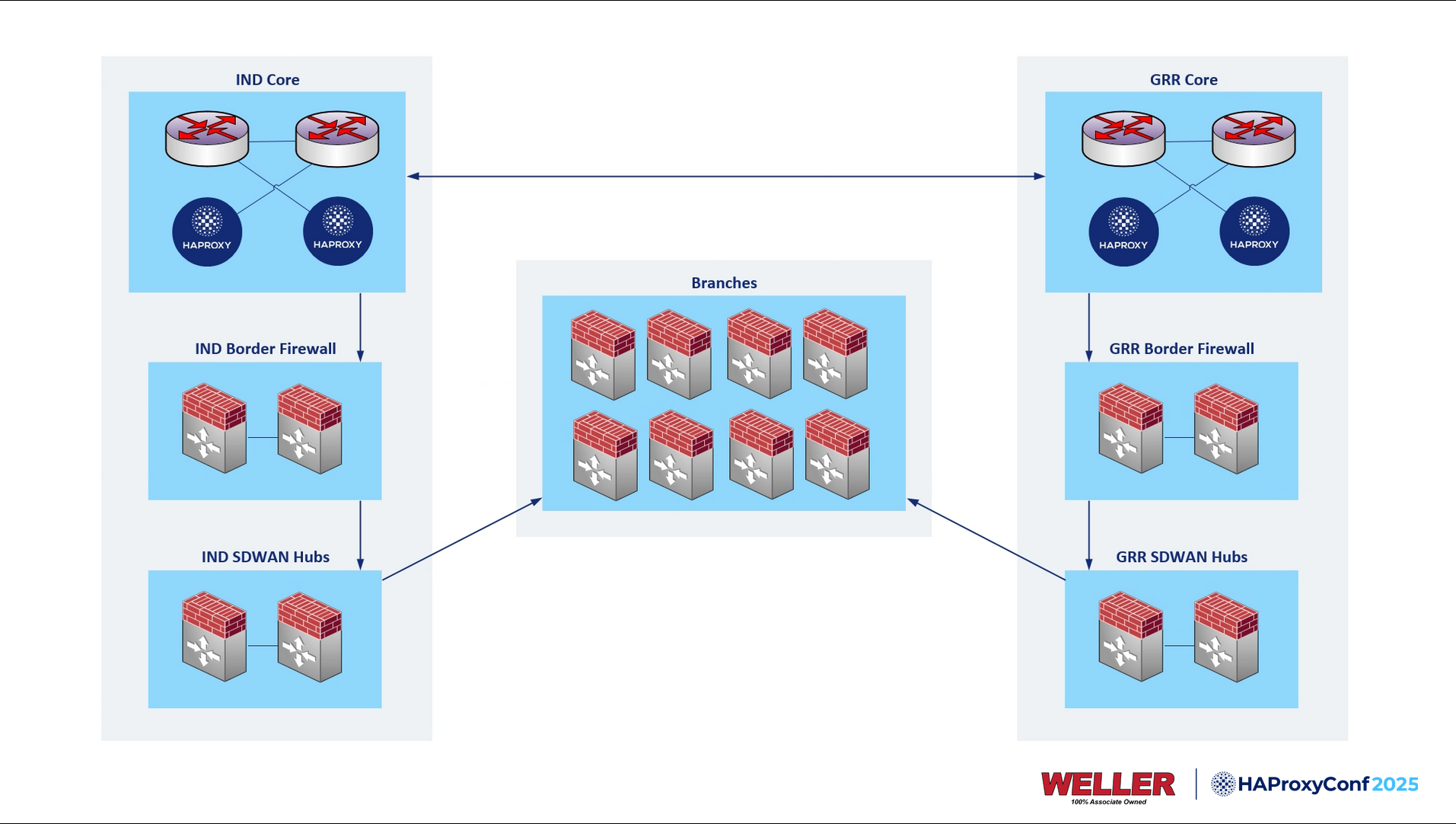
As I mentioned, we're using Anycast BGP within our configuration. We have two identical environments at both data centers, and they're receiving routes or applications through the HAProxy Enterprise nodes. We added an MPLS interconnect between our data centers to sync backend data.
Every router and firewall within our network runs BGP now; they're all in their autonomous system numbers. It lets us distribute those Anycast routes from the load balancers to all locations around the US.
While there, we also opted to route all traffic from the branches into the data centers for things like SSL decryption, central inspection, and security policies.
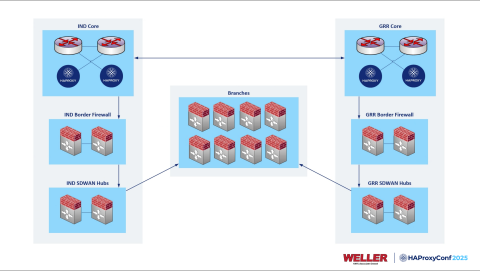
This is a visualization of what our BGP network looks like, but you'll note here that we have a prefix reserved, 10.200.20.0/23, and then inside there we have CIDR 32s for all of our frontends. Those come down from our cores at both data centers to border firewalls, another set of firewalls acting as SD-WAN hubs, and then to our branch firewalls.
We end up with a nice solution for scaling out and adding additional data centers for a deployment like this. On the left and the right of the diagram, we end up with a clean stack from top to bottom.
We plan to open a data center out towards the western region to service our associates in the western US with lower latency as well. All we need to do is get another pair of load balancers, cores, and firewalls, and we're done. We can start injecting those routes from Denver or Las Vegas anytime.

To peer our load balancers with the cores, we used BIRD, which in HAProxy Enterprise is called HAProxy Enterprise Extras RHI, but it's essentially BIRD. We peered using OSPF to get loopback reachability with our cores. Over the loopback addresses, we used BGP to inject the route health information.
Another thing to note is that we also enabled BFD (Bidirectional Forwarding Detection). If there's anyone unfamiliar with BGP, there's a condition where if your peer goes down, the default behavior could take up to 30 seconds for your peer down to be detected. This isn't things like route updates, but if maybe you lose power to a load balancer, the underlying host running it, or a severe critical networking issue, bi-directional forwarding detection allows you to bring that detection time down from like the 30-second area to 100 milliseconds. You can go lower with more configuration, but we're doing 100.

This is what our BIRD configuration looks like. We have a couple of BGP processes used to peer the load balancers directly with the cores.
You'll notice at the bottom of those sections, you see export where proto = "vol1". This is the volatile table in which the Route Health Injection Module will store the routes when applications are up or meet the conditions we set.
Then, at the bottom left corner, to turn on BFD, all you have to do is create an empty little bracket there, and that enables it. And then you can start it with the overlying process. So by adding BFD or BFD gracefully into your BGP configuration, you enable that signaling for BGP.
The OSPF stuff is pretty simple: we're just advertising the loopback address into the core, and we have the area attached to the physical interface and the loopback interface.

Now, here are some notes on enabling these features on Ubuntu. I just found out yesterday that this will get much simpler with their new appliance release, so this point may be moot. Still, the HAProxy documentation does cover all this excellently if this is something that you want to try to reproduce or do in your environment.
You need to add some static routes on the loopback interface. You must also add another socket, which you could put right in your global config of HAProxy Fusion for the RHI Module to access your Runtime API. Then you have to make some rules to intercept that traffic because the operating system doesn't have an IP address on any of those interfaces when you have transparent IP addresses on your frontends.

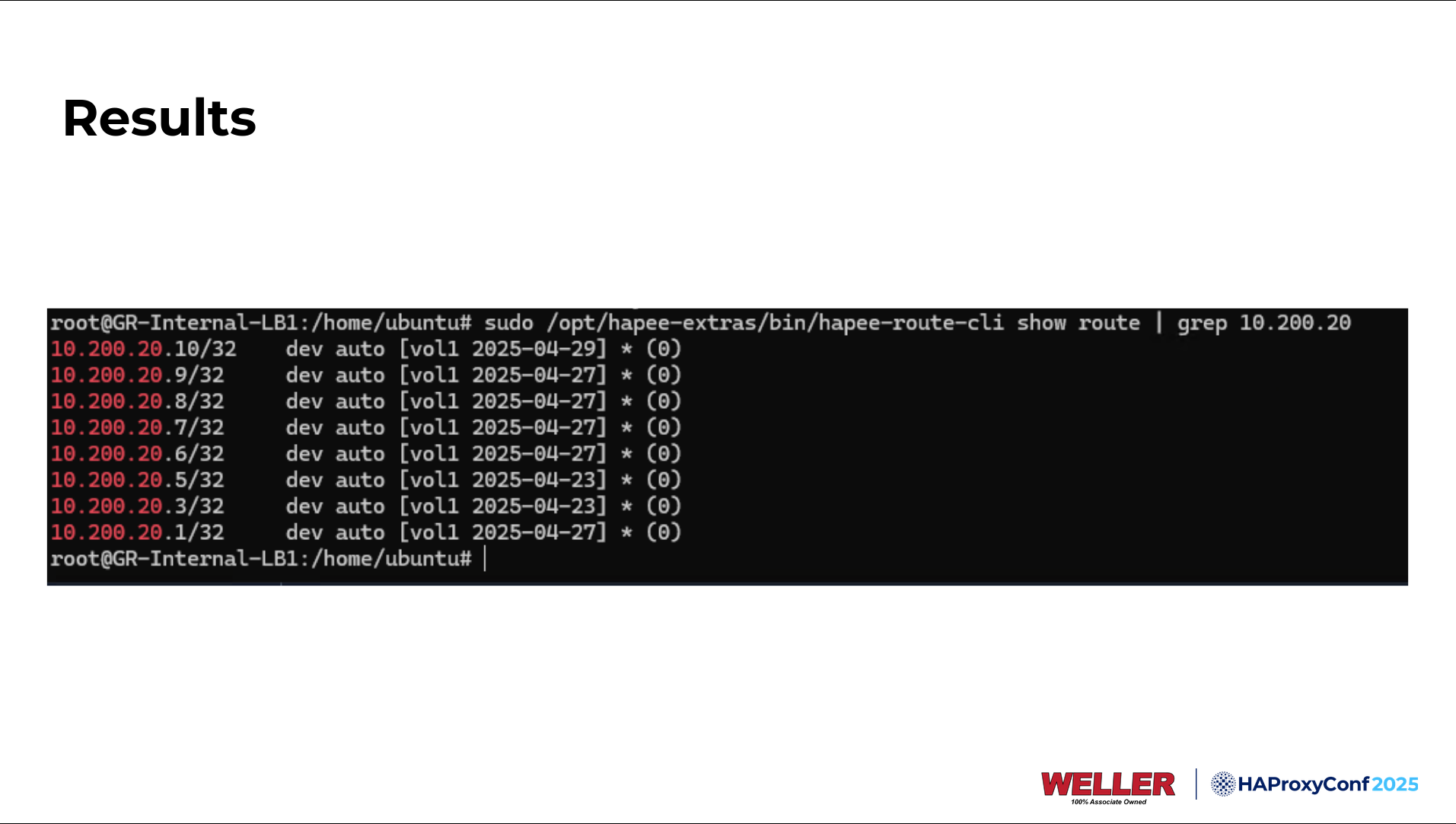
This is what the RHI configuration looks like. The first demo I'll show you here in a bit is this top one, but you're just meeting a condition here. We're saying to inject 10.200.20.1 into the BGP peer if any server in the backend called WebFarm is online.
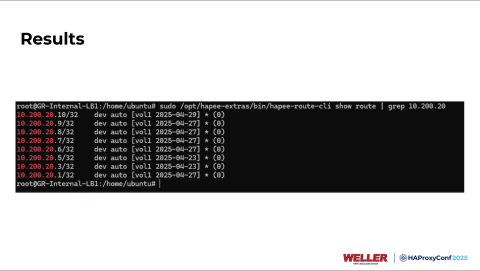
If everything's configured correctly and you set up your frontends and backends, you'll see something like this when you do a show route on the HAProxy Enterprise route CLI. We can see that these routes are already in our volatile table. If your router that it's paired with is properly configured, it'd be sitting in your routing table as well.

When I distribute these routes, I use prefix lists with a default deny rule at the bottom to get really good control over what routes we're sending to what routers within our network. You have to enable BFD on your peer end as well.
So on the right-hand side here, our neighbors 10.200.100.5 and x.100.6 are our load balancers, and you can see we have a fallover BFD there. Then we also have some route maps attached to that. We're using two different route maps to bring the routes into the cores because we originally deployed this without using equal-cost multipathing. When we got our stick tables behaving the way we wanted, we could eliminate that.

For the magic sauce now: if you do this at both data centers, how do the clients or the other routers know which data center to reach your applications at? There are a few different influences on path selections within BGP, but two of the most dependable are local preference and path length. We're going to our Indianapolis data center, and we're artificially making the AS path longer by prepending it three additional times with the AS number of those core routers.
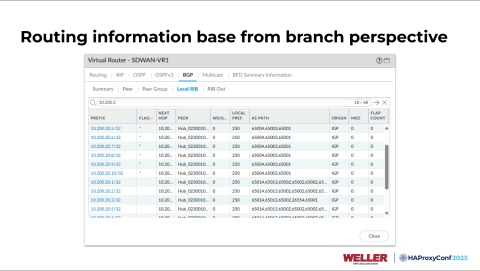
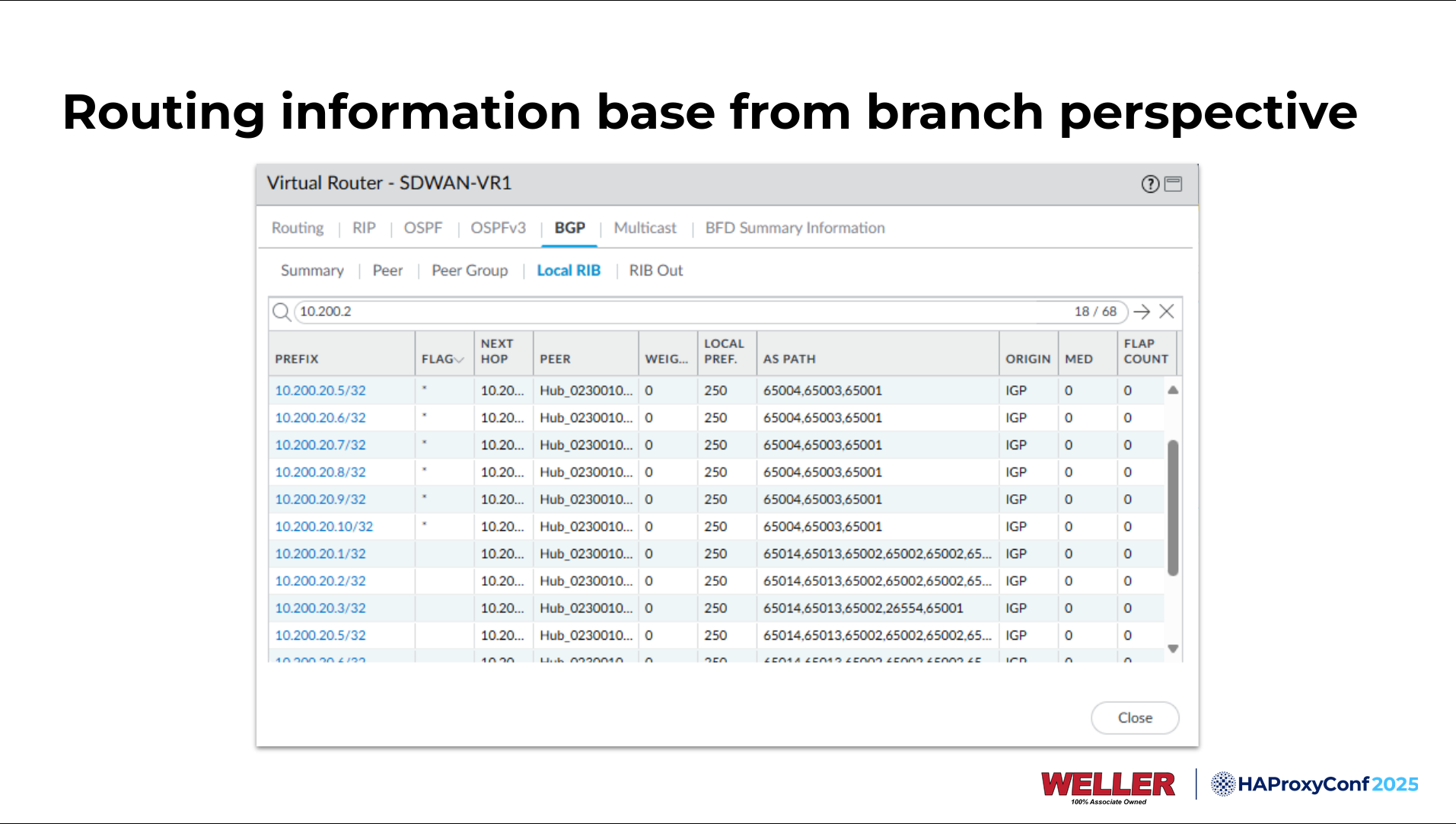
From the branch location perspective, we have identical routes at both sites. We're at a branch firewall right here looking at the routes, and you see the top ones here all end in x.65001, going to our Grand Rapids data center.

But then you also see some on the bottom that are a little longer, and they have x.65002 prepended on the end there.

Now for some fun. I have a prerecorded demo that I will use as an opportunity to pause a few times and walk everyone through what's occurring during one of these failovers. I also have a demo we will do in our production environment.

What we have right here is just an IIS server, and you will see "Welcome to Indiana" within that image, which lets you know that the IIS server is being served from Indianapolis. And if we look at our firewall here, we see the asterisk flag next to that route that ends in x.65002, indicating that the application's being served out of Indianapolis.
We will then go to the HAProxy Fusion Control Plane and mark the application as ready in the Grand Rapids data center. And this occurs very rapidly. So, if you know, we have a timer running in the corner here, too. So we mark data as online, return to our web browser, hit refresh, and now we're connected to Grand Rapids.
This is the simplest of demos because it's just static content. Depending on what type of applications you put behind this, you will need to think about stuff like authentication and cookies, and how you synchronize those within your backends.
A couple of simple scripts are running here that will get paused quickly. The one on the left runs a trace route every second, and the one on the right runs a GET request every second. In the middle of the screen on the left, if we look at hops number 3 and 4, we watch those change at the 1 minute 55 second mark to 1 minute 56. The hop beginning with 10.194 is in Indiana, and after we failed over within HAProxy Fusion, you could see that change to 10.190, indicating Grand Rapids. But then on the right-hand side, we make a GET request every second, and we didn't miss a single response.
We'll look at what this looks like again from the branch perspective. We'll refresh our routing information base here. Now you can see that the route ends in (or that the AS path ends in) x.65001, indicating Grand Rapids. So, all this can occur and propagate within your network extremely rapidly. Depending on how you architect your applications, these failovers cannot be noticeable to your end users.
All right. Now, what we're going to do is illustrate another test of this using our VDI environment, which is probably, I would say, maybe our most critical application that we use at Weller Truck Parts because associates have to be able to log into their desktops to run our ERP, take orders, know what to build. In this example, we're going to do the health checks that are configured in HAProxy Enterprise. We will disable our connection servers on VMware Horizon and let HAProxy Enterprise detect this. Another thing to keep in mind when you're doing a deployment like this is that your health checks play a big role in how long it takes to detect a failover and how quickly that takes place.
A little background here. I will show you what this will normally look like if we run out of the Grand Rapids data center. I can open the Horizon client here, connect to our VDI environment, and I'm presented with an option of desktop pools. Most users will typically only be assigned to one at a time. What happens if the Grand Rapids VDI environment goes down? Well, we can do that real quick.
So, we're going to disable our internal connection servers, and now we'll check out HAProxy Fusion; see if I can find it here! Go to our Grand Rapids cluster. And we're going to wait for the health checks to fail. The servers that say Gambit and Sabertooth will turn red. After that happens, we will see exactly what occurred with the IIS server example. The health checks will fail. The Route Health Injection Module will stop injecting the route to Horizon at Grand Rapids within the network.
Then, we'll reconnect to our Horizon environment. We'll see completely different options for our pools, and we can actually log in there, and all of our user data will still be there because it's synchronized at the backend with something called FSLogix Cloud Cache.
Let's check on these. It looks like one of them's down. We'll find out if they're ready to go already. There we go. We're at our DR VDI pool so I can connect to this. Their user will log in normally and probably won't notice any difference because all their user data will still be there. It's there.
Now, how do we monitor the solution? Monitoring the environment is important because it's gotten complex, and we need to know what's going on at all times.

What we ended up doing for alerting is that all of our HAProxy Enterprise nodes are sending log data directly to HAProxy Fusion. Still, we also send that to a Graylog server, where a few queries run every five minutes. We're sending email alerts and opening internal help desk tickets if a BGP change is detected or an application server goes down.
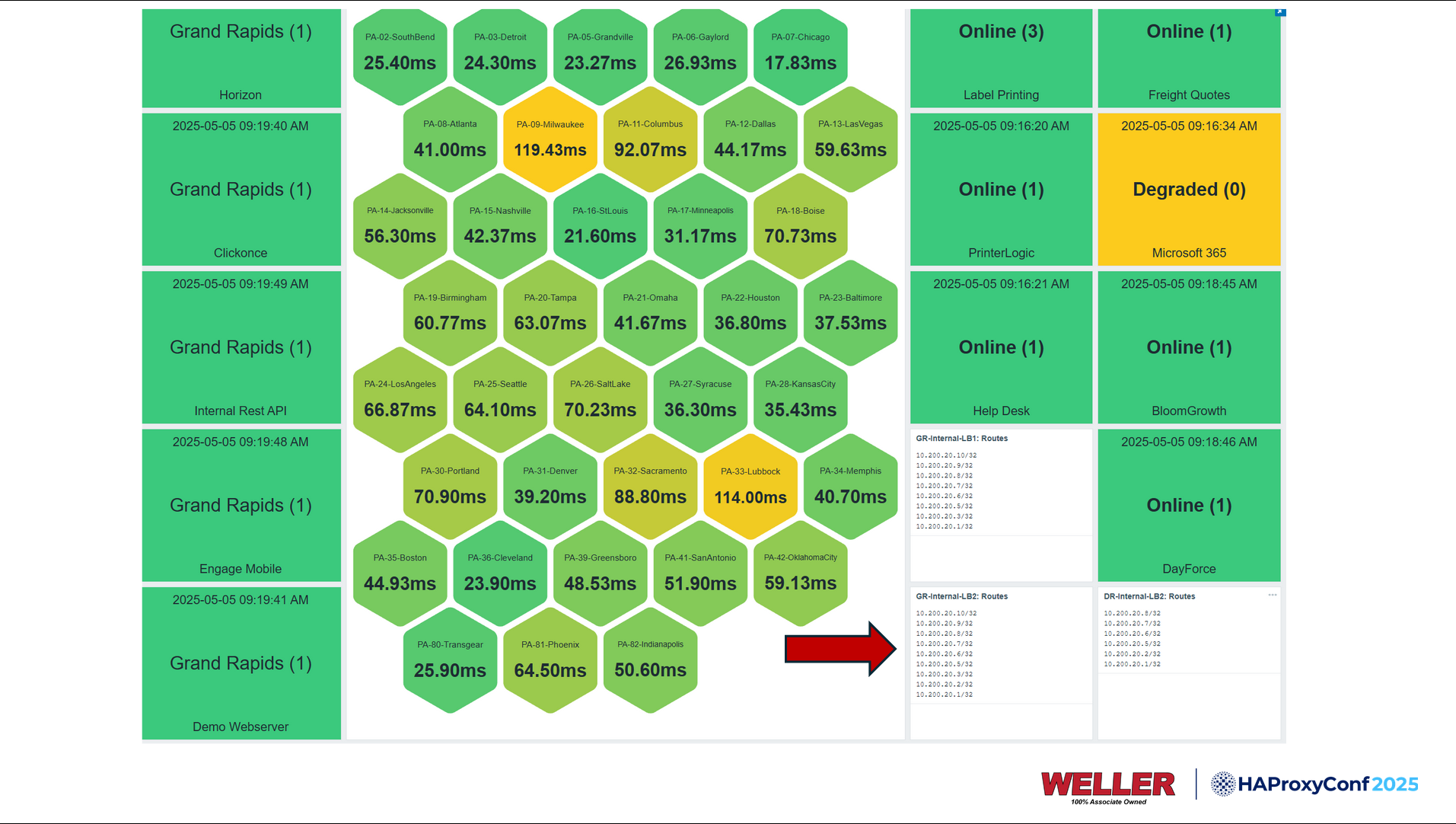
Another thing that I wanted to do was show all the routes in the volatile table without having to SSH to one of our HAProxy Enterprise nodes every time, and run the command myself. We already had a pre-existing Zabbix environment, and I wanted to leverage that since it's already sitting there. We put the Zabbix agent on our load balancers. There's a parameter in the configuration called UserPreference, which allows you to create a new variable name and then have a command that the Zabbix agent runs. We just made the Zabbix agent run the show route for us…

…which lets us get little lists. They're real-time, so we can go to one of our dashboards here, see what applications are getting injected by the network, and then infer what data center is running that from there.

Some of the caveats we encountered included turning off automatic updates because we had a couple of extra packages added to the virtual machines, and there were a couple of instances where the automatic updates rebooted or restarted the HAProxy process. Still, the Route Health Injection Module got stuck and needed to be restarted as well. I came into work one morning at 6 a.m., trying to figure out why every application was running out at Indianapolis. It was because of automatic updates.
The next thing was logging within HAProxy Fusion. We ended up using HTTP CLF logging instead of TCP logging. You have one option to use for the Request Explorer, so the support team was amazing. They helped us apply some custom formatting to our front end on our HAProxy Fusion configurations so that when we go into Request Explorer, we can see the combined logs for both types of applications, HTTP or TCP.
Another issue we ran into was that some MPLS providers won't advertise multiple paths for the same route. This is default BGP behavior; some vendors won't turn on add-path for you. So that's something to think about if you leverage MPLS in any of your backends. Some workarounds like multi-hop BGP exist, but we're just living with it for now.
And then another issue, if you use Palo Alto Networks for any SD-WAN solution within your environment. We use Palo Alto Panorama with the SD-WAN plugin module, which generates tunnel configuration for all your devices and your configuration. But what they do is they generate unique community strings that get appended to your BGP routes. That took a minute to figure out, but you have to add those community strings to all these routes you want to distribute throughout your environment if you want those to go to your branch locations.


Some of the lessons learned are in terms of improving infrastructure reliability. Anycast is an extremely efficient way of directing users to specific data centers and for scaling out your environment.
Hot sites are the best way to optimize your disaster recovery resources.
If your application is failing, you already know that there's probably a problem, so having HAProxy handle it frees up more time to investigate the root cause of issues.
Next, managing all these configurations in a single control plane massively simplifies things. Some of the homebrew stuff I was thinking about cooking up would require constantly comparing configuration files in four locations, which was not a good idea. So, when you can log into HAProxy Fusion, manage all your clusters from a single location, and have all your log data aggregated, it simplifies your life.
Another big lesson learned was that using your network layer for data center failover is a lot faster than DNS. A lot of people use DNS for stuff like this, but you're dealing with things like local caches, clearing those, and propagation time between DNS servers within your environment.
The last thing for infrastructure reliability is implementing native health checks within all your applications. This means that once the solution is deployed and tested, it's fully automated.

Like I said, we looked at a couple of different vendors for load balancers before choosing HAProxy Technologies. HAProxy Enterprise was not only the fastest, but it also seemed like the easiest to configure. Every time we can simplify our lives, we're more efficient and can spend time on other projects.
Another thing with HAProxy Technologies is that they made it easy to deploy their product quickly. Like I mentioned, I have a relatively small team. You don't have to be a giant organization to be able to deploy something like this, and you don't have to be massive to benefit from it either.

And that's all I got.
Dylan Murphy
Awesome. Thank you, Austin. So we do have time for a couple of questions. Again, if you'd like to ask one in the room, raise your hand nice and high and wave so I can see you. We did have a couple that came in the stream. So the first one is: what advantages does Weller get from managing multiple data centers and interconnect versus putting it all in the cloud?
Austin Ellsworth
Good question. So, as I mentioned, we have around 1,200 cores. If you look at the cost, I figured it would be around $90,000 to $100,000 a month minimum in compute. There are massive cost efficiencies if you run your own hardware and data centers and have the team to support it. With the cost of running something like this in the cloud, we could rebuy the hardware twice a year.
Dylan Murphy
Another one from the chat. So this may be related to what you just said, but what was your cost savings compared to your previous disaster recovery solution?
Austin Ellsworth
I wouldn't say there were any cost savings because we weren't doing it before. We had a way to restore backups and a well-thought-out plan, but if disaster struck, we'd be waiting four hours or so while that workload was spun up. Maybe you got blessed with some Microsoft updates or something. So, yeah, we weren't doing the same thing before.
Dylan Murphy
Awesome. Well, thank you so much, Austin. We appreciate it. Give it up for Austin.
