When you send an HTTP request, do you ever stop to consider the intricate journey it undertakes before your backend even begins processing it? While we often focus on the application logic, the true "anatomy of a request" goes far beyond, involving a complex interplay of protocols and kernel operations. In this insightful session, speaker Hussain Nasser pulls back the curtain on this hidden world, revealing the nuanced steps and often-overlooked overheads that occur from the moment a request is initiated by a client to its ultimate reception and readiness for processing on the server.
This deep dive illuminates how foundational elements like TCP and TLS handshakes establish reliable, secure communication channels, the critical distinction between user-space and kernel-space, and the CPU-intensive dance of data copies for cryptographic operations, compression, and parsing. Hussain also touches upon the role of various protocols (including HTTP, SSH, and DNS) in defining and interpreting requests. He explores additional considerations for performance tuning via kernel settings and other important points to keep in mind when developing high performance applications.
By understanding these fundamental mechanisms, you will gain a profound appreciation for the underlying complexities of network communication and backend operations that are so often shrouded by libraries and abstracted away from the application logic. This session offers valuable insights into performance bottlenecks, especially concerning CPU utilization from memory copies and cryptographic operations, and provides practical considerations for optimizing system configurations, drawing on real-world examples and the efficiency philosophies behind technologies like HAProxy.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.










Thank you so much for joining us today. Today's talk: Anatomy of a Request, Beyond Backend Processing.
I was having a chat with Kelsey Hightower last night, and he asked me what the talk is going to be about, and I told him it's going to be about the journey of the request. He said this is funny, because at Google, when someone joins, the first thing we used to give them was "the journey as a packet" as a presentation, which is very similar to what we're going to discuss today.
When we look at the idea of a request, the first thing that comes to mind is the processing of the request. That is, I'm making a request. Then I'm making an API call, an HTTP request, that either goes to disk, reads some HTML file, or JSON, retrieves that, and sends back the response. Either that, or you go back to the database, do some queries, parse that result, make it either a JSON response or a protocol buffer, and return it to the user.
We always think of the processing aspect. Some API calls are more expensive—like I am actually doing a CPU-intensive operation—let's say calculating the prime numbers, for example, so that's also a request.
But a request is actually way more than that, and that's today's topic. What is going on from the moment I write the request as a client until it's received on the back end? There are the hops in between. There are load balancers, and there are API gateways.
What really is a request? That is the question that I am fascinated about: what a request really is.

The way I look at a request is this: it's a message that has a start and an end, and that start and that end are defined by a specific protocol. When I receive an HTTP request, the reason I know it's a request is because it's bound by the HTTP protocol. The HTTP protocol spec defines where the request starts: this is the HTTP verb and this is the length of that request. You need to start somewhere, and you need to end somewhere. Why? Because without this boundary, you have no idea what these packets are.
Today, the only mediums to send stuff on are TCP and UDP. TCP is just a streaming protocol. I struggled with this concept before—what is a streaming protocol? A streaming protocol is just a bunch of bytes, and the only one guarantee is that those bytes are in order. There is no end, and there is no beginning. There is no end to this stream. Well, technically, there is a connection, of course, and there's the boundary of the connection, but it's just a bunch of bytes. So the job of the higher-level protocols, like HTTP, is to define the chunks of these bytes.
OK, I'm receiving this bunch of bytes and I just saw a GET request. Let me start reading. Then until I reach the end of that request, I have one message. That is expensive. That takes time. I want to focus on that aspect of things in this particular case.
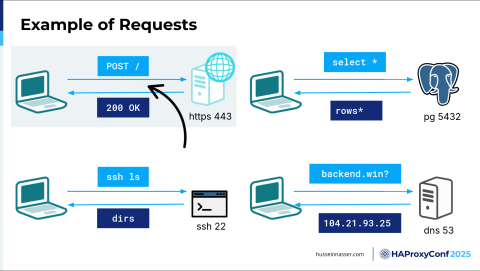
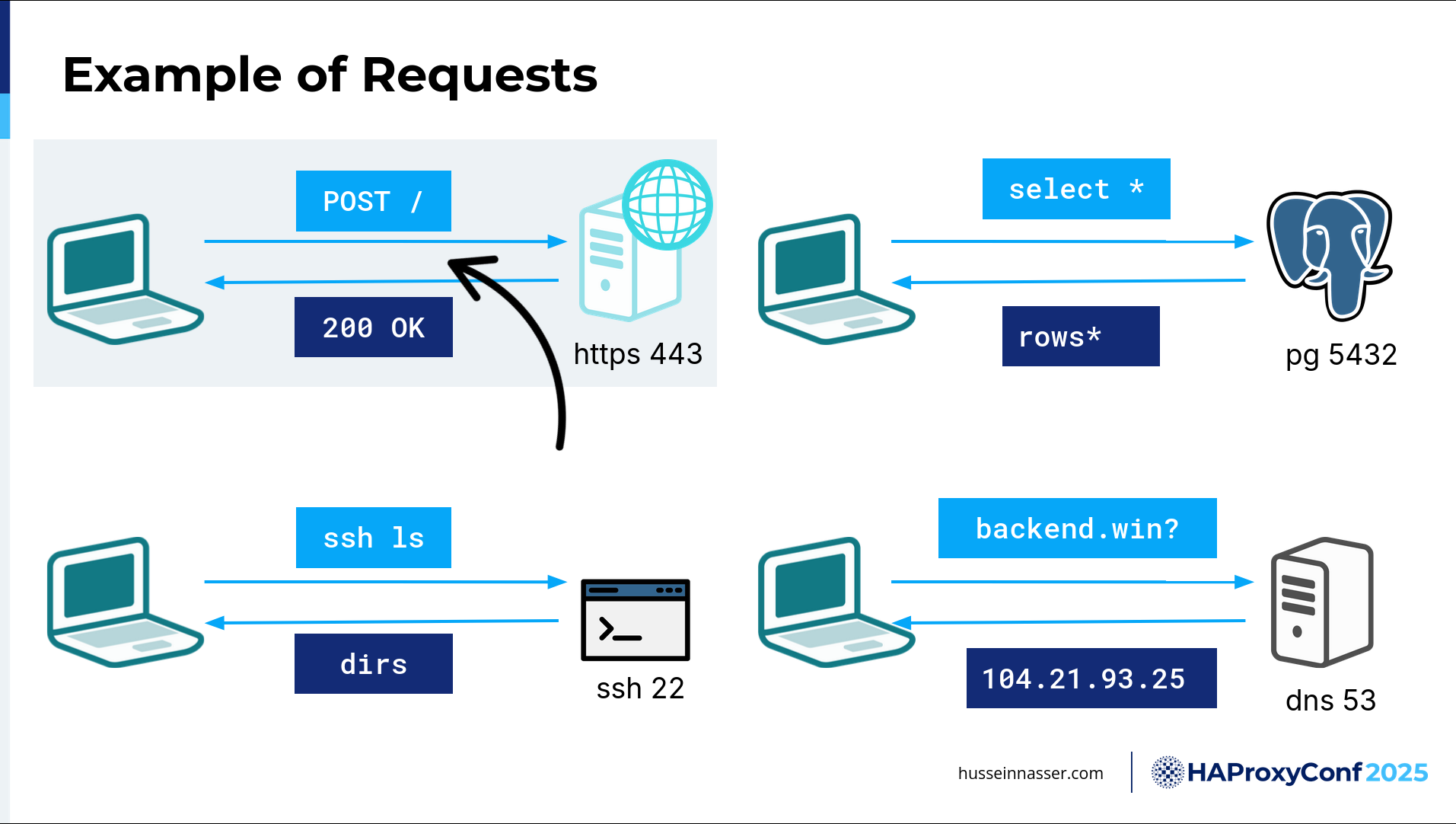
Here are a few examples of requests. To the top left, we have a classic HTTP request, well, HTTPS because we have encryption on port 443, but we're sending a POST request. The client, in this particular case, understands how to write HTTP requests. Why? Because there is an HTTP library that has been baked into the client.
Unfortunately, these days, everything is invisible to us. It seems like we're building on top of so many libraries. Things became so easy and simple on the outside, but we've hidden so much. With this talk, I'm trying to pull back the curtain and see what's behind it. That's my job. I love this stuff.
So, there is a client. There is an HTTP client protocol. You've probably used the Fitch library or Axios. The client eventually calls that library, that's what writes the request. The backend will have a corresponding HTTP server library that knows how to listen for requests, parse requests, and then also write responses back.
For the second type of example here, we have a Postgres server, and then we have a client that has a Postgres—you guessed it—protocol library. Without this protocol, we cannot do anything, right? It's like a language. If I'm speaking a language, for example, if I'm speaking Arabic, most of you won't understand me, right? But because I'm speaking English, you have this knowledge, this common protocol that we are speaking, and we can understand, right? So, Postgres in this particular case is listening on port 5432, and it understands the Postgres binary protocol. As long as the client has the corresponding Postgres client request, it will send a select statement, select *, in that particular format. The Postgres server will understand how to read and parse this and will return the response.
It's the same thing with SSH. SSH is built on TCP, just like Postgres, just like HTTPS. Well, you can also build HTTPS on top of QUIC, but that's another topic. Most of this stuff is built on TCP. SSH, in the bottom left, is listening on port 22. If I'm connecting, it's also on port 22. SSH is a protocol, so you need an SSH client library, and there is an SSH backend which understands how to parse an SSH command. Well, we call it a "command", but technically, if you think about it, it's also a request. It has a start, and it has an end, and you get back a response. Technically, the response also has a start and an end, and a way to parse it. But our focus here is on the backend and request, and backends accept requests, right?
The final example here I have is DNS. DNS is also a request. The only difference here is that DNS is over UDP. We have a DNS resolver listening on port 53, and you send a DNS transaction request on top of UDP—same thing. It has to have a specific boundary. The interesting thing about this request that you send is that it can, no matter what the transport layer is, fit in one network packet or it can be across 10 packets. It doesn't matter. That is the single most important thing to understand. That is, it's not one-to-one, it's one-to-many. Because of that, the backend must continue to read until it discovers the end of the request. Every read has a cost. If you don't read fast enough, that has a cost as well. I'm going to talk about that as well.
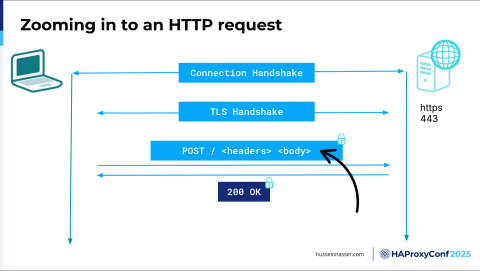
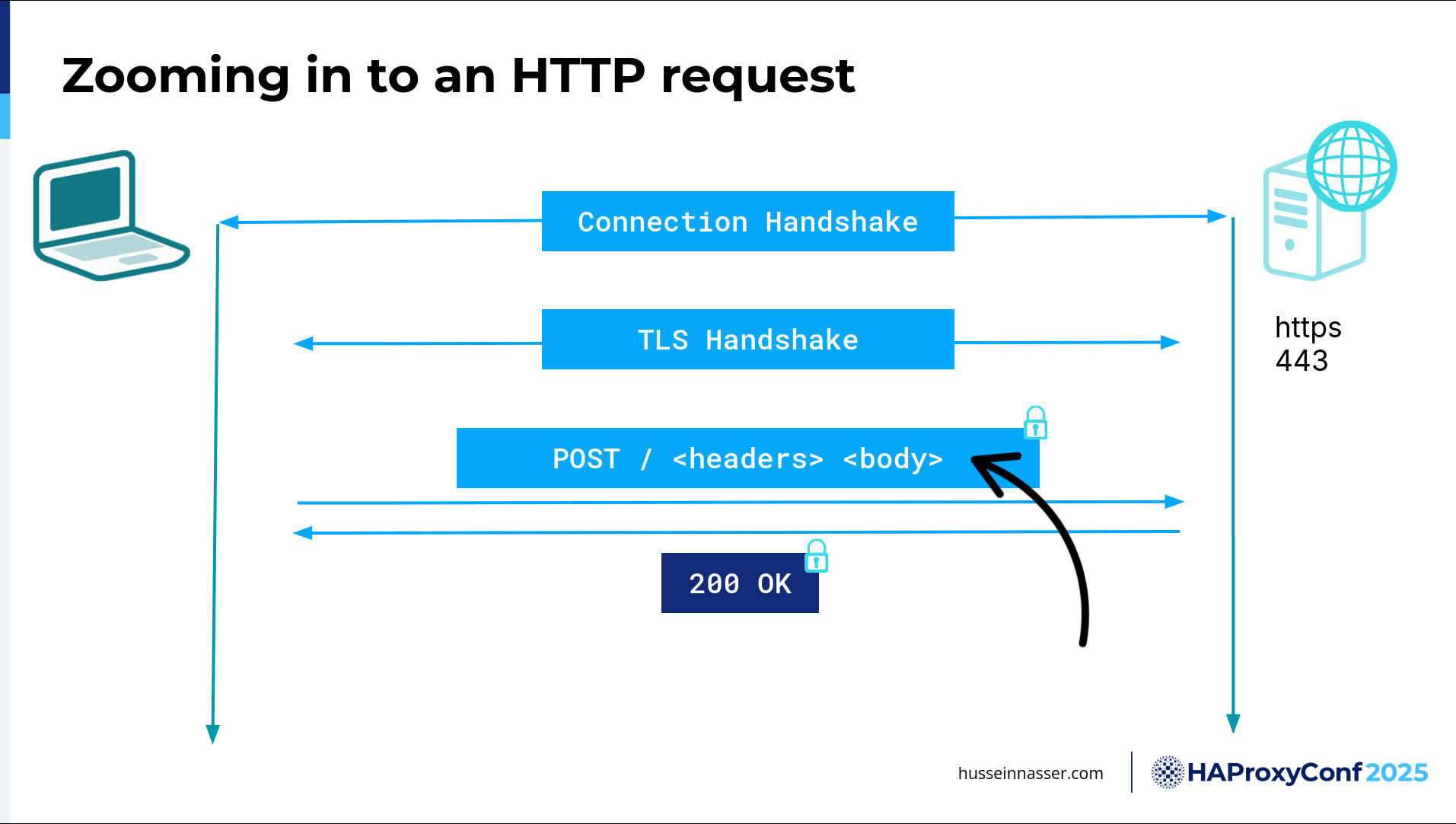
Let's zoom in into just the HTTP example here. I have an HTTP client and I have an HTTP server. The first thing we do, and I'm going to assume TCP for simplicity here, is to create a connection. We establish a medium that is trusted by both the client and the server, and we will send stuff over that medium. Because we're using TCP, which is a streaming protocol, it's nothing but a bunch of bytes. Now, these bytes will be eventually encrypted. They might have HTTP. They might have any number of other things. It doesn't matter. It's a fact that they are just bytes. The job of this connection handshake, or the protocol, is to make sure the bytes are received in the order they are sent. That's both a good thing and a bad thing, because we're now forced into a specific order. Sending multiple requests becomes interesting. Let's just focus on the idea that we are initiating a connection.
On top of that, and once we have the connection, we usually have a SYN, and a SYN-ACK, and an ACK, and this is where the server and the client exchange the window sizes and sequences so that they can label the segment. Every segment is labeled so that we can ensure the order of the packets. To label something, you need a starting segment, a sequence number, so these guys exchange those starting sequence numbers. Now we have a connection.
On top of that, these days, we cannot do anything without encryption because we live in a zero-trust environment most of the time. So, we need TLS, transport layer security. That's this stage. The goal of this is to exchange symmetric keys—well, exchange secrets in order to create symmetric keys. These symmetric keys should only be available to the client and the server, and then they will be used to encrypt anything that we send over this connection. In this particular case, we're talking about requests, so we're encrypting requests, and we're adding additional overhead. We had a fantastic talk yesterday—William actually gave that talk—about TLS. Because it's expensive to do the connection handshake and the TLS handshake, we try as much as possible to resume an existing TLS handshake so we don't take the hit every time, because there is a fixed cost to do that. If we can eliminate it, that would be great.
The third box is the actual request. We have a request, and we're sending a POST request: "/", headers, body, and then the whole thing is encrypted using the agreed-upon symmetric key. Then we send it over, and then we receive the response. What I want to do here is zoom in a little bit further.
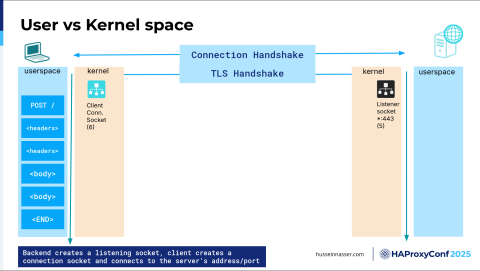
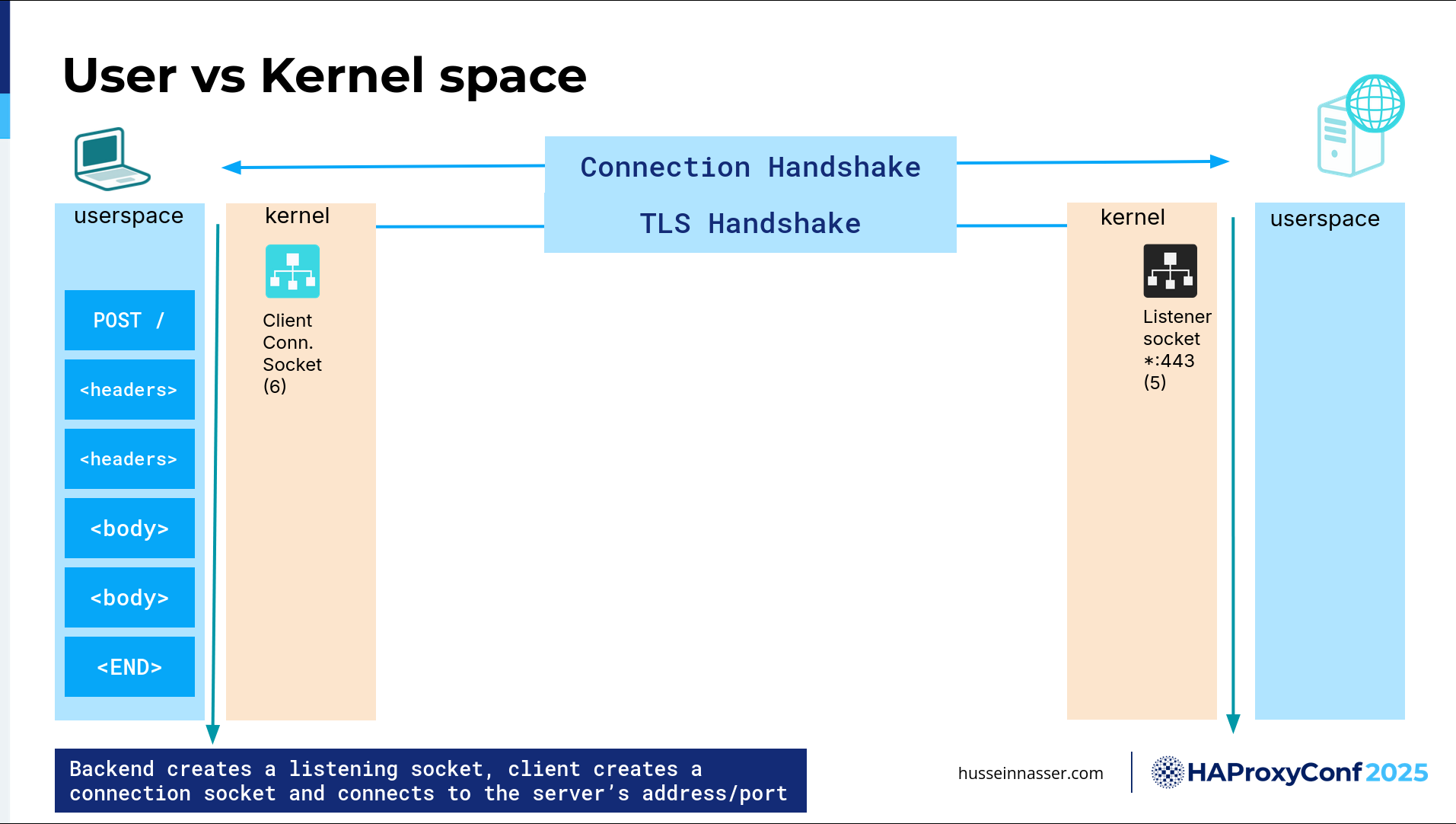
Let's talk about user space and kernel space. TCP, as a protocol, which is where the connection handshake is going on, lives in the kernel. The kernel is basically where the OS is, right? It has an intimate connection with the hardware. It's closely related to the hardware.
Here on the left side, we have the client. On the right side, we have the server. On the left side, we have this yellow box, which is the kernel of the client, and then we have the user space, which is the application. Guess what? This application, the HTTP, is an application. Your SSH library is an application. Your browser is an application. Even the TLS library is in user space most of the time. Understanding where code runs is so critical because there will be chatter going on.
What kind of chatter is going on here? The backend, the first thing here on the left side, when we create a connection, we get this client connection socket, and we get a number assigned to it, a file descriptor. Let's say it's "6". On the right-hand side, we have the server side, and we listen on a specific port and IP address. In this particular case, I'm listening on all addresses (*). It is usually a bad idea to do that. Essentially, when you listen on a specific port, you also get a file descriptor— that's a socket.
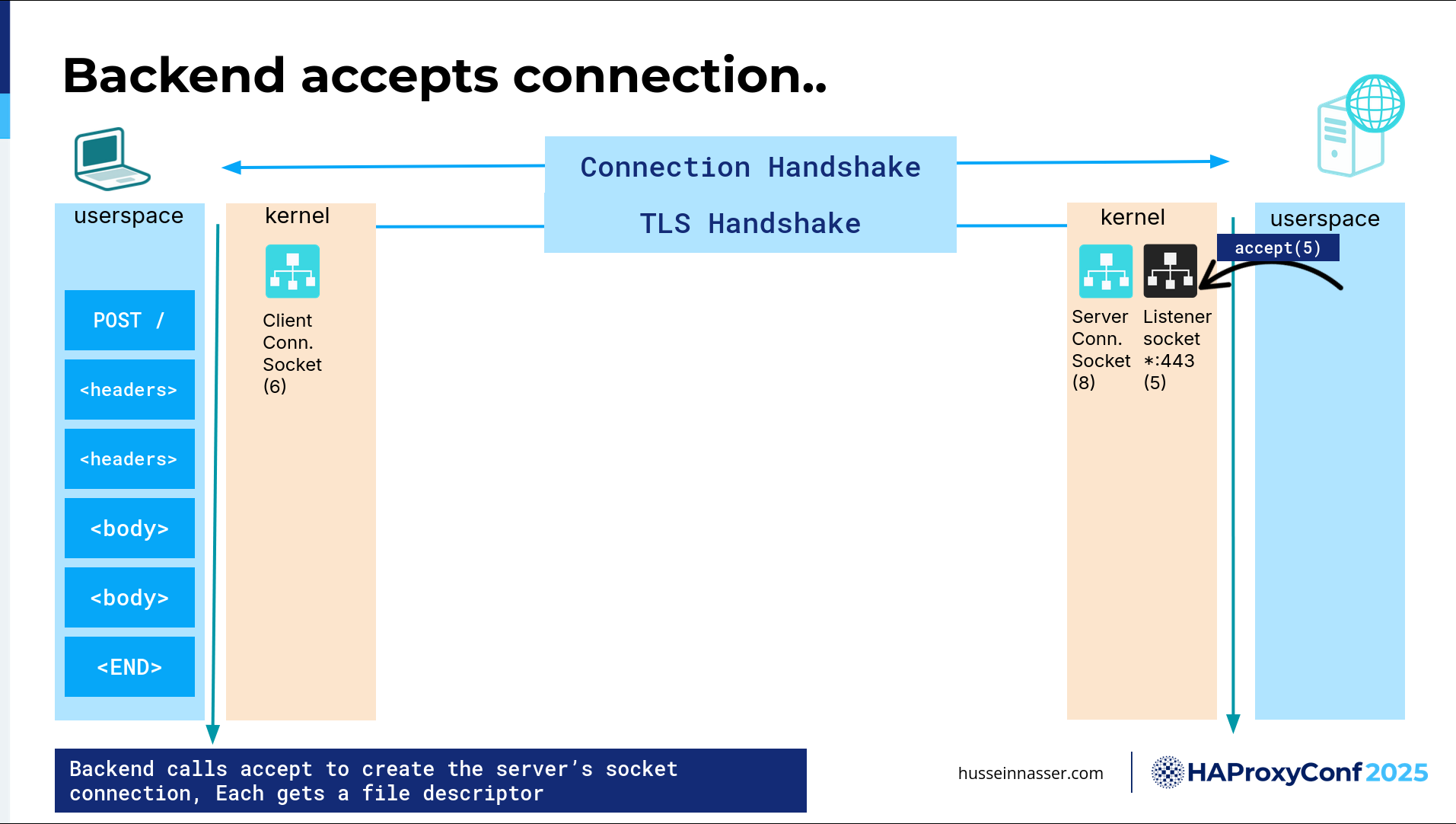
We still don't have a connection yet. On the backend, after that connection has been created or the handshake has been done, what happens next is the kernel leaves that connection in what we call the Accept queue. It lives in the kernel, and the connection is not yet created. To create the user space, the app, our backend, must call a function call or a system call called Accept() and give it the listener socket in order to create a connection.
There is also some work here to even create the connection. Now, I want you to scale this into millions and millions of clients connecting. You have a bottleneck here. If you have a single socket, everyone is competing to Accept connections. You have mutexes (mutual exclusions). You have all sorts of delays. We can talk about that later— how to solve that.
HAProxy already solves most of these problems.
Once you hit Accept, now you have an actual file descriptor corresponding to the connection, which in this case is 8, that corresponds to the client.
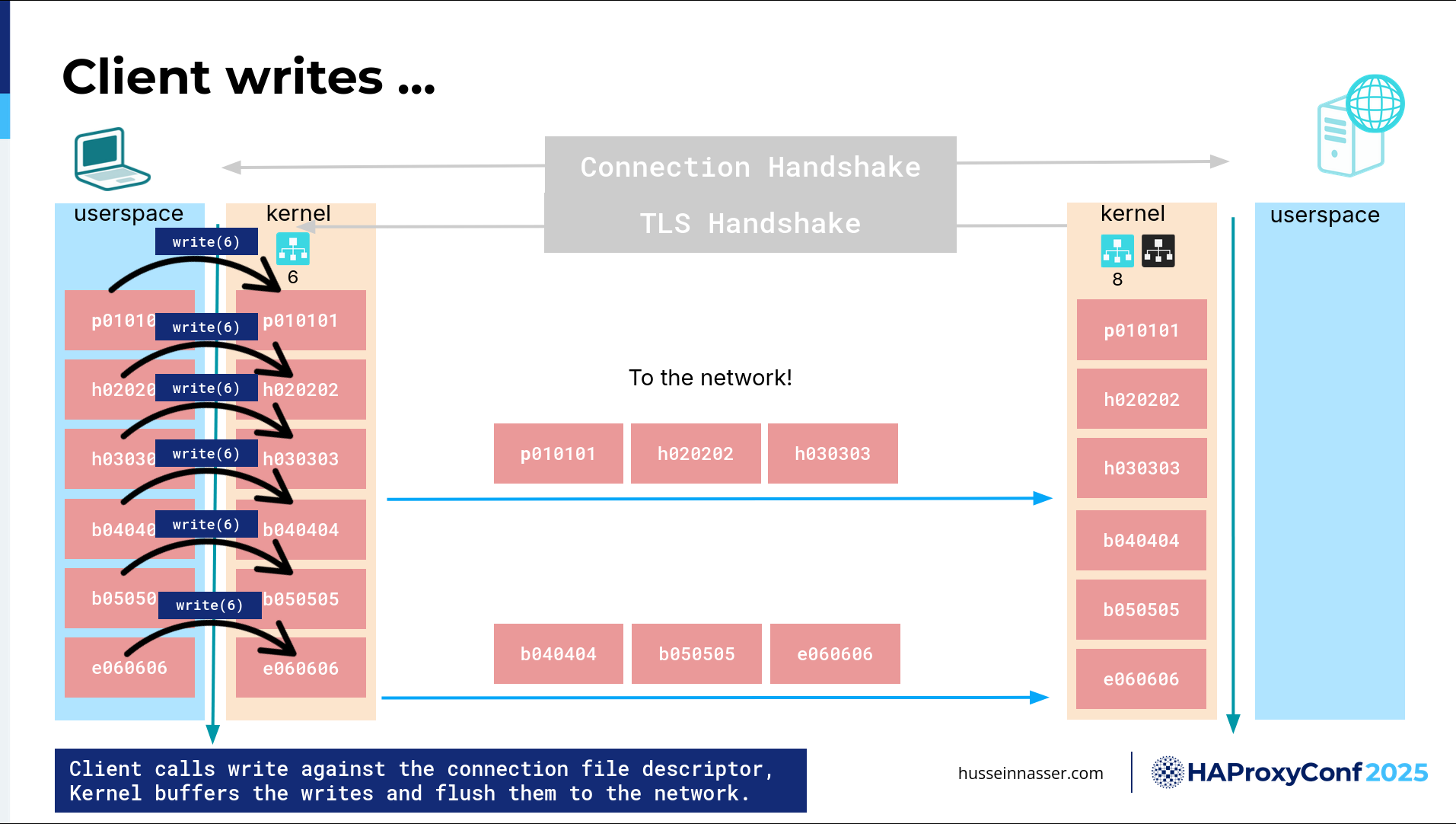
Now we can start reading and writing. Reading and writing what? Bytes. There are no requests at this level. There is no encryption. There is nothing. It's just bytes. So keep that in mind. The first thing is on the client side: we want to write the request. We have this request—It's called POST, it has a bunch of headers, it has a body, and it has an end, and we want to write it. But before we write it, we have to encrypt it because we are in an encryption session. And we have this key that I have already negotiated.

Now we're going to encrypt that. If you think about how to encrypt things, I have this chunk of data, it's usually a fixed-size block, and we technically need to copy it in order to encrypt it. You cannot encrypt in place, right? Because in case of corruption, you cannot go back. So, copying also has a cost, and we'll talk about this in a minute, but almost every copy, or memory copy, goes through the CPU. That's how it works—if you want to copy a certain chunk of memory from this location to this location, you need to read it all the way to the CPU. You need to write it through the L3 and L2 and L1 cache and through the registers, and then when it gets to the register, there's an instruction called store, because you loaded it, and now you store it. Where do you want to store it? In this location. So you've got to write it back. Every copy (well, most copies, because DMA is an exception) go through the CPU, and that's why memory copies cost CPU, which is kind of a little bit odd to think about, but they do. So here, we have consumed some CPU for the encryption itself, of course, because TLS’s algorithm is all encryption, right? And it's CPU-intensive.
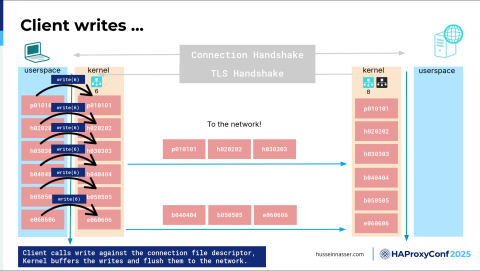
The next step is one of the most interesting things. Now, where does this data live? It lives in the user space, right? It lives in the app. It's in the virtual memory space of the process. We can write to the connection in order to send data to the network, and now we're ready to send it because it's encrypted. But to write it, we have to write it to the kernel. When we write, we specify the file descriptor of the connection, which in this case is 6—that's my connection—I want to write this to the connection. Because the kernel batches, it's expensive to trust the client. If for anything the client sends, if I immediately send it to the network, I'll end up sending one byte to the network, which is a lot of overhead. There is a whole algorithm that controls this called Nagle's algorithm, because how long should I wait? It's a very interesting question. That's why I love this stuff, because you can dive deep into any of this stuff and write papers about it.
If you write here—notice I wrote something, so that's a copy, so I'm using CPU, but it's copying from user space to kernel space, but I didn't send it to the network yet. The third one, I decided, well, we have enough data, let's ship this to the network. Usually, you try as much as possible to fill one MTU, maximum transmission unit, just as much as possible. This is the segment of the TCP. I want to send these as much as possible. So we send it over, and it goes from the kernel all the way to the network. This is where the whole IP takes over: data link, and then goes to the physical network, which in the case of fiber, it's light, in the case of Wi-Fi, it's radio, or in the case of Ethernet, it's electric. Then regardless, it will be transformed back all the way to the second server. Now we have the encrypted byte where it's in the kernel of the server or the backend, not with the user. The user has no idea about it. OK, and then we've written the whole thing. This is just an example of writing the rest of the packets, and we received all of them at the backend. Now they are encrypted chunks in the kernel. They are useless at this point.
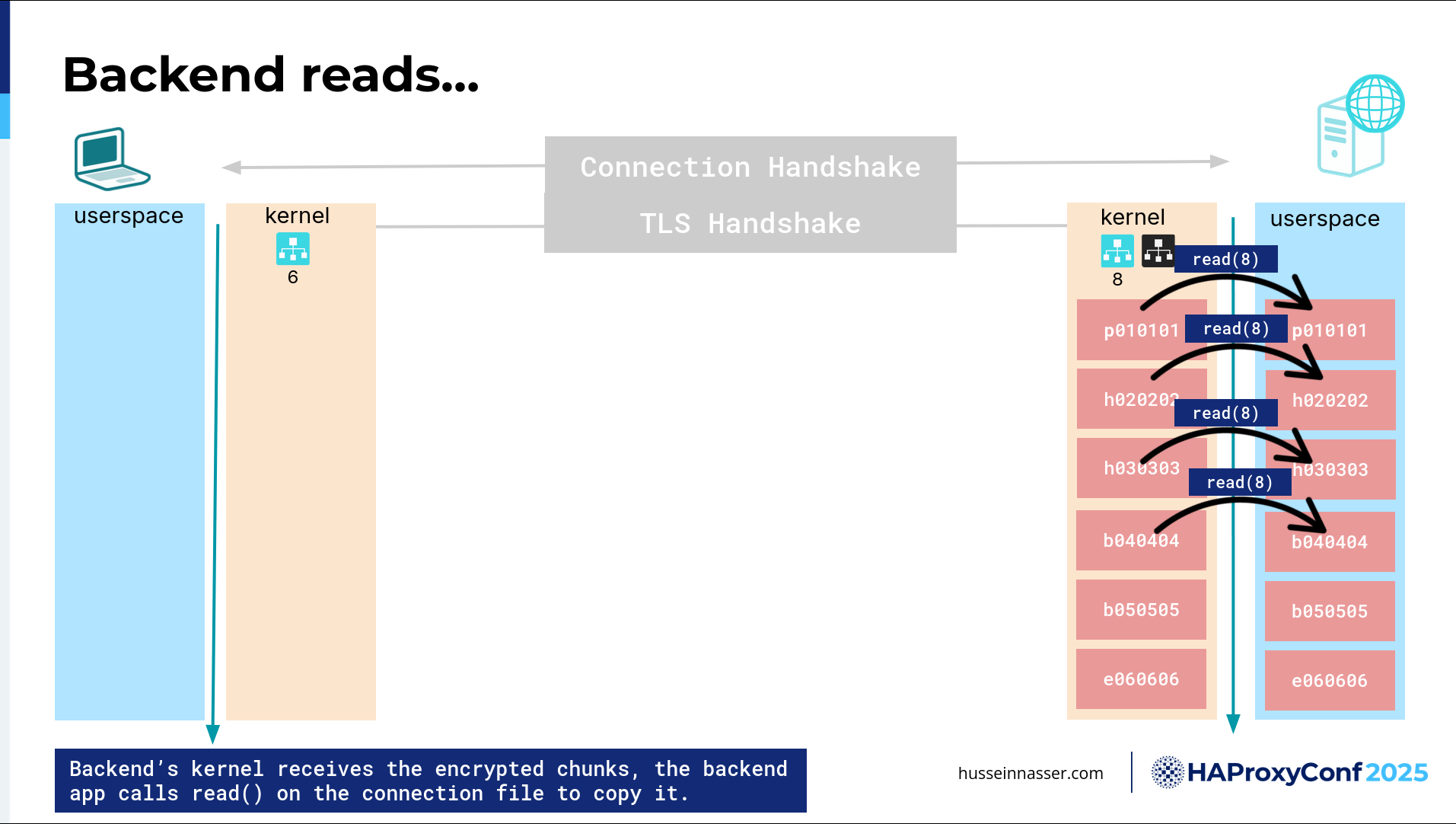
Now the backend's responsibility is to call read(). You might say, I never call this read(). What is this read()? Again, it goes back to the libraries. Every library you use eventually must call this system call, because otherwise you'll never get your data. To be more specific here, that data lives in what we call the receive buffer of the kernel, of that TCP connection. Every connection you create will have two things: a send buffer and a receive buffer. In this particular case, all this data lives in the receive buffer. The kernel will keep it there until the client, in this case the client is the backend, will call read() and will purge it from the receive buffer and then copy it to the application. So now we're calling read() again on read(8), on the connection that we created on the server side. Then we copy it— that's more CPU. We keep copying until we have all of the encrypted chunks in the user space. Sweet!
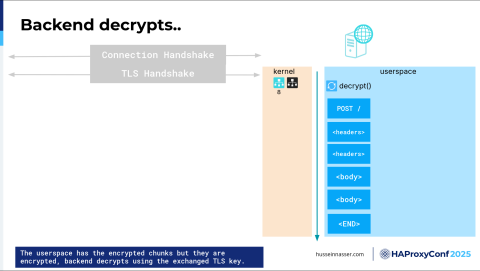
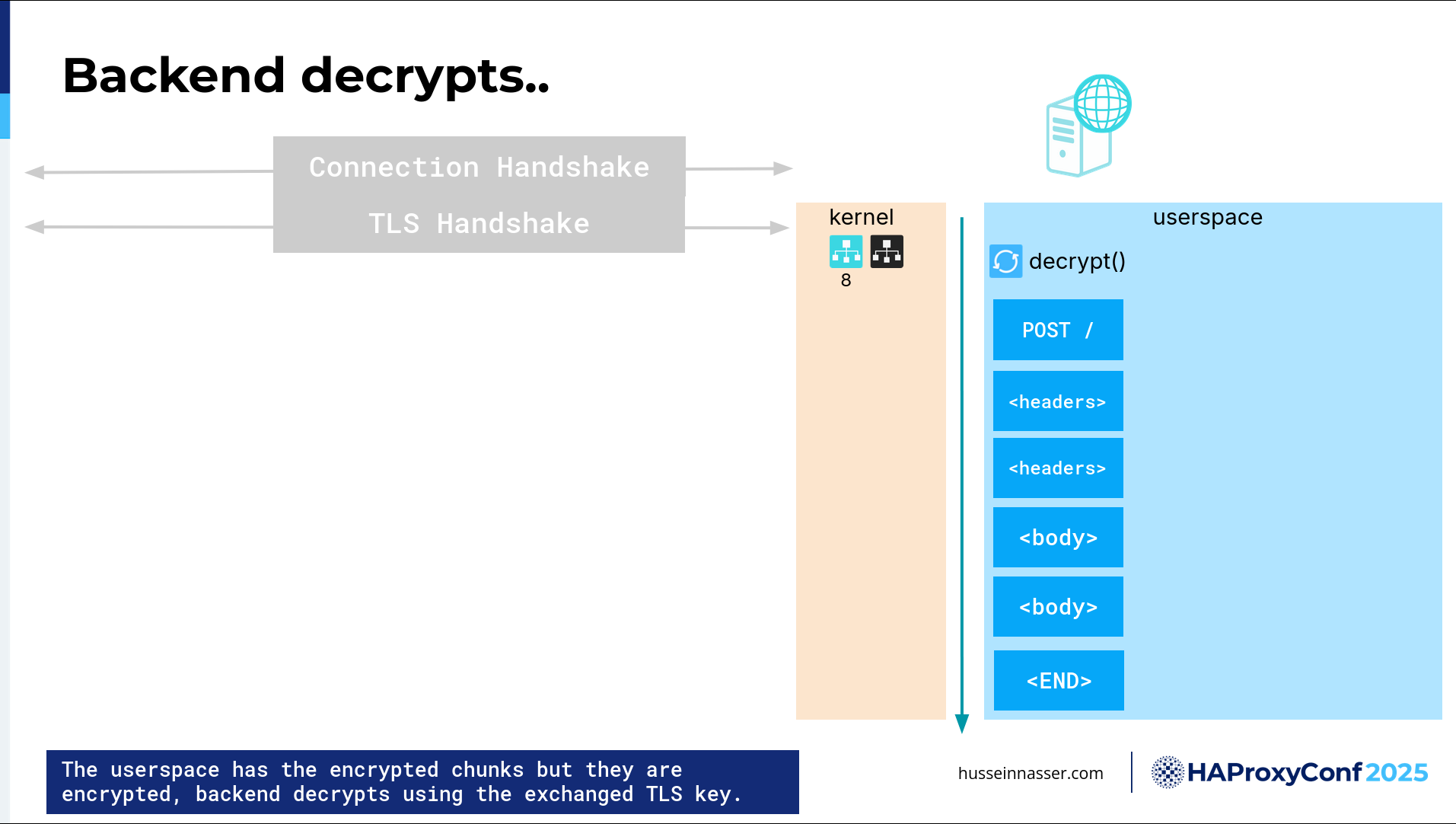
That's not enough, though. These are just bytes that are encrypted. At this point, I cannot tell what this is. So I need to execute an OpenSSL or WolfSSL library which lives in the user space, which is another set of instructions that will take these encrypted bytes and decrypt them, through which I may do a couple of copies in the process and use more CPU, and you can see how much the CPU is taxed.
And we didn't even get to the request processing yet. Forget about that. We didn't even reach that. We're still trying to look at the request.
So now, we have a bunch of decrypted chunks. What is the request? We still don't know. Where is the beginning of the request? Where is the end? We have no idea. We have to do the next thing, which is parsing for that request.
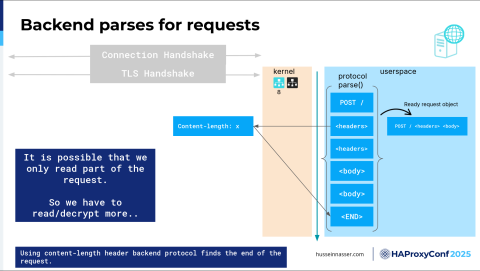
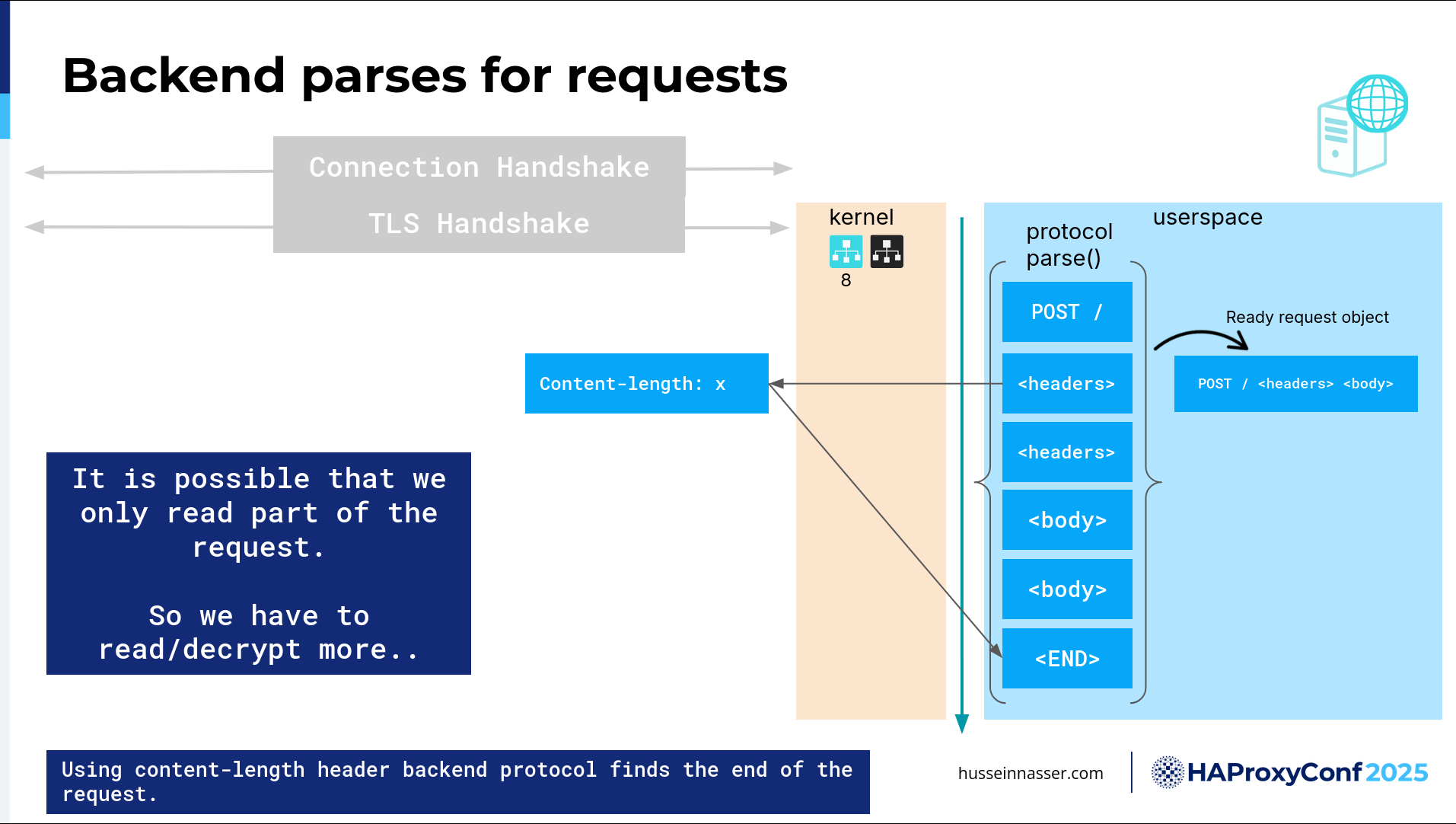
So now, the backend protocol—back to the protocol library—kicks in here and starts parsing. It says: what do I have here? Oh, I have a POST. OK, POST is good. That's the start of the HTTP request; I know that. I have an HTTP library here, so I know how to parse this stuff. If it's HTTP2, I need to use an HTTP2 parser, and so on.
So now I parsed all of this stuff, and now I have a full request object. When you ever reach that stage, that is when, for example, in Node.js specifically, there is an "on request" event. That is when that event will fire, at that point. Now we have a false object, and in this particular case, to learn how to parse this, we looked at the header and determined there's a content length, and the length is X, so we have to move X number of bytes until we read the entire thing, right? That's one way to read HTTP requests. First define the boundary of HTTP requests.
Here's another thing: we might have not read enough bytes to get a full request’s worth. Because we're reading bytes. We have no idea. We're reading encrypted bytes of all things, so we have to encrypt, we have to read and decrypt, and read and decrypt. Maybe we got half, but maybe we're only halfway through the headers. So we determine that's not a full request, we should read more, and that cycle keeps repeating until we have a full request object. Then that request object then gets sent to some handler and then we'll go from there.
We're not ready to execute yet, by the way. Not yet. So now, there's another step.

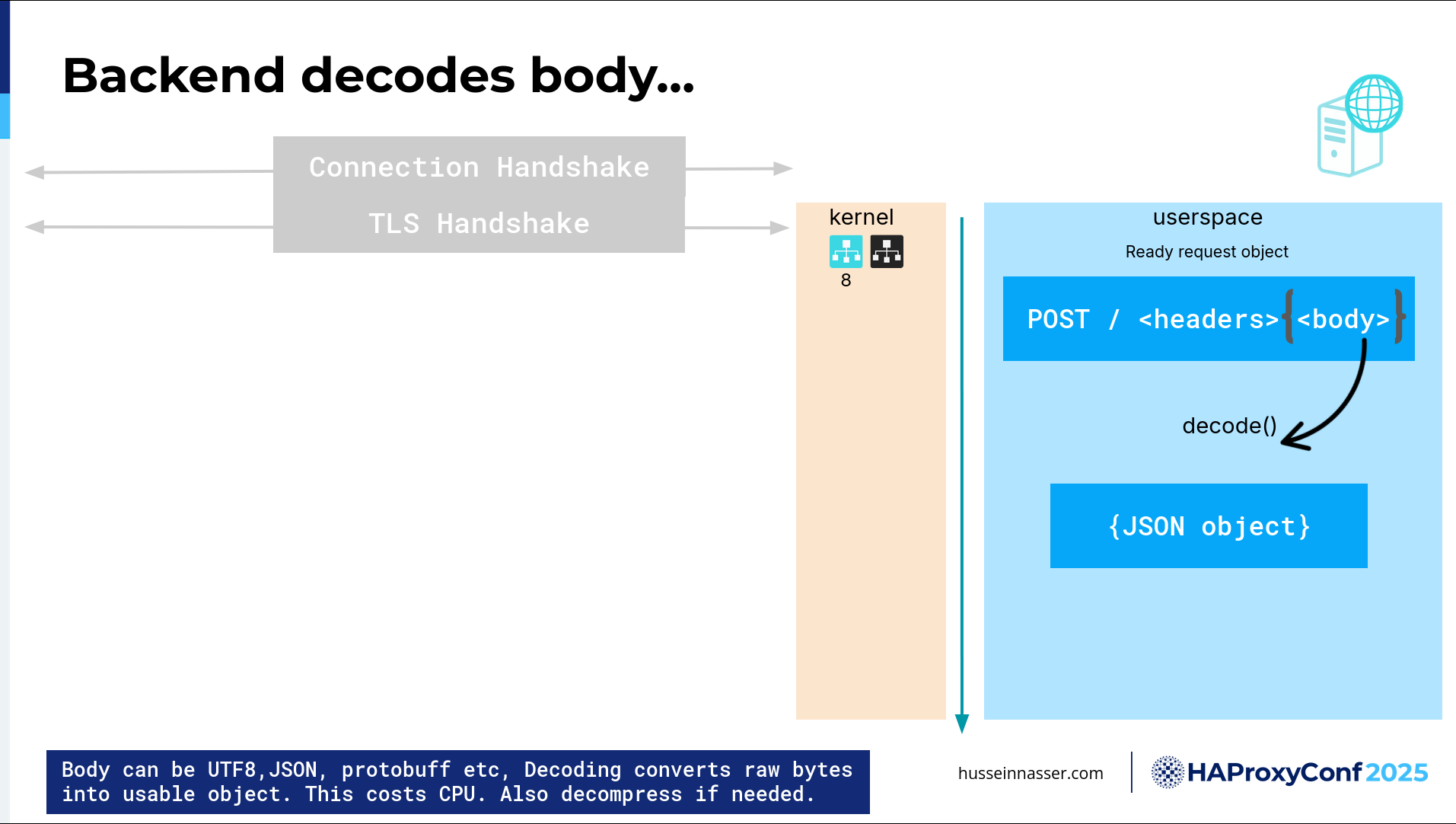
This is optional, but I thought I'd add it: decoding. Most requests use this idea of HTTP compression.
We don't have header compression anymore, request header compression—because we removed that due to an attack called CRIME. I forgot what it stands for. C-R-I-M-E. But essentially, it's that someone can sniff and detect what is inside a packet based on how big the compression is. So, they will send something and then see how far the compression went. We stopped compressing headers for that reason. Most of the time, right? I have to mention that this is HTTP/1.1. In HTTP/2, we have another completely different algorithm for compression, which is HPACK, which uses a map table, not really actual compression.
For compression, the body can be compressed, and the body can be specifically encoded, for example, in JSON or Protocol Buffers. If you think about it, these are also protocols by themselves, right? You need to understand how to parse them. For JSON, you need to understand how to parse JSON, and you might be familiar with some libraries. I had a case where there was a C++ library that was really bad at parsing JSON. By switching it to another library, I got like a 90% performance gain, and that's this—decoding the body, right? If you have a large body, more work needs to be done to decode. We get a JSON object, so this is another step that we might go through.
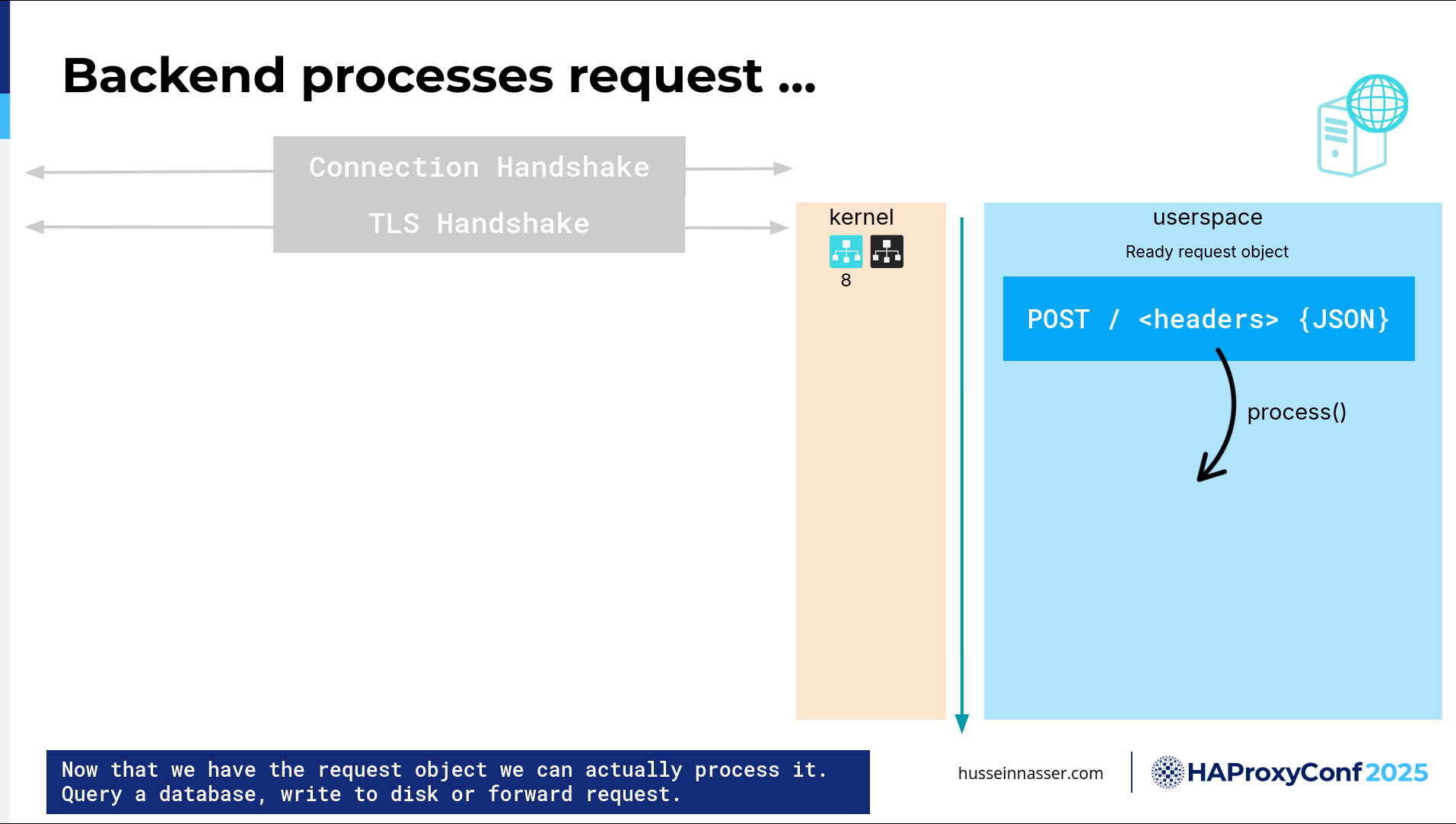
Finally, we have a ready object request with an actual JSON object that we can read, parse, and understand. Then we can process this. The world is your oyster.
What do you want to do here? You want to use the same process to execute this? You want to spin up another thread to delegate this request to? You can do that. You can have an existing thread pool and just throw this request on it. You can do anything.
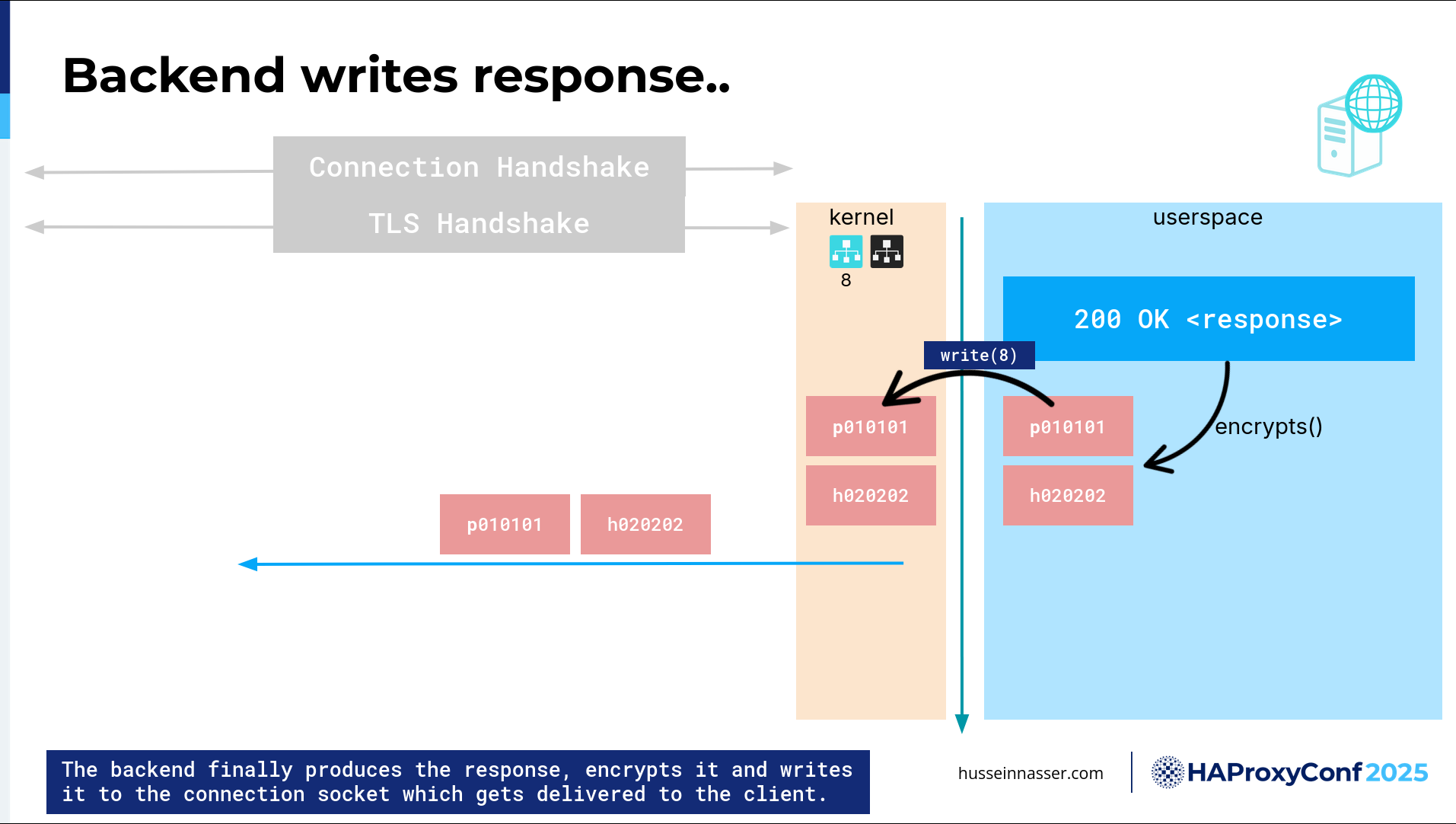
Then, once you have the response back, you can compile it, and then you write it back. Of course, you cannot send it plain text. Remember, this is an encrypted channel, so you have to encrypt it, do a copy, and then write it back to the kernel.
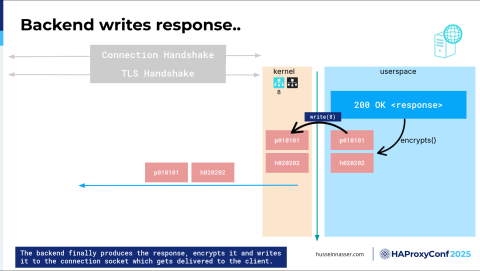
You never write to the network as a user. You write to the kernel, and the kernel will decide when it feels like it to send it to the actual network. I think there is a command to flush, to force. It's like, you know, I know what I'm doing, kernel— go and send it. But I don't know if that is even trusted.
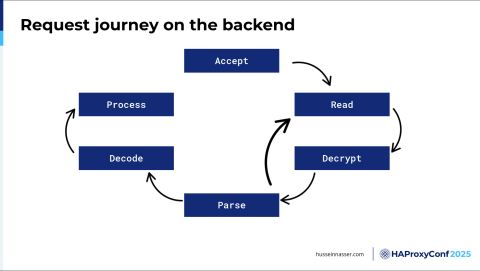
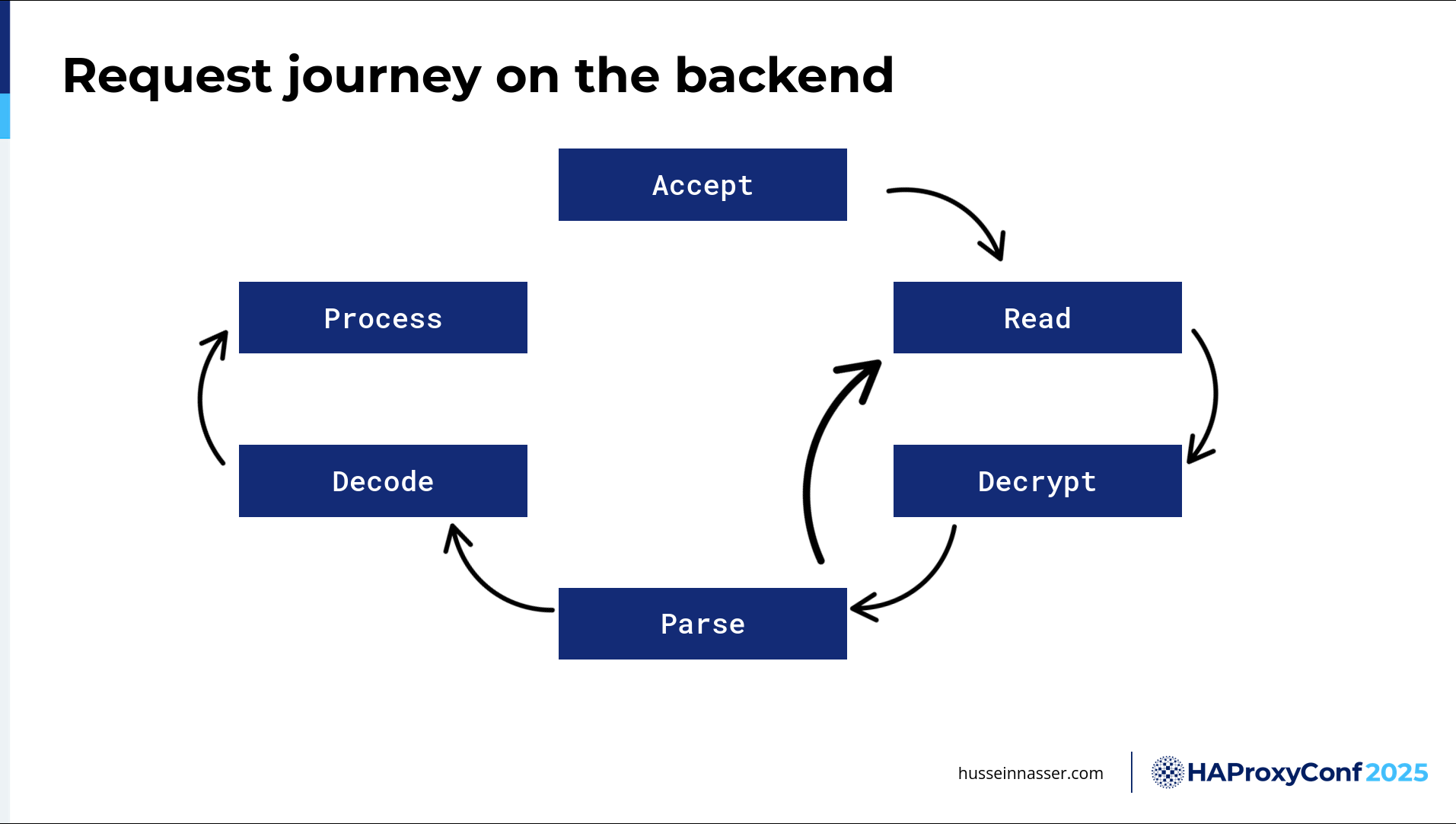
That's the journey of the request here. The Accept part and the encryption part happen once. At least the connection establishment—that Accept. You only accept the connection once. At least you hope so, right? You don't want to create a connection for every request where you send and then close it. We used to do that in HTTP/1.0. We stopped doing that—we want to keep the connection alive and then send as many requests as possible. Then you read and you decrypt and then you parse. And then you repeat. And you then optionally decode. You process and then you're done.
That's the journey of the request.

I'm going to talk about some considerations here. This is my idea of going a little bit more in depth.
For the first step, Accept, how fast can the backend accept connections? I want you to think about that. As you're receiving tons of these SYNs and SYN-ACKs and ACKs, those connections will be established by the kernel. You don't have to do anything. The kernel will add the connection parameters, the source IP, and the source port, in what they call the “accept queue”. Another connection will come, and will be added there, but it's not a connection yet, it's just ready to be accepted by the backend. You can control how large the accept queue is by specifying the listen parameter. And when you call listen(), you're specifying how large the backend is here, the backlog, but then, of course, you can't control that size— but you can. You can have something called socket sharding with the socket option reuse port (SO_REUSEPORT), where you can have multiple processes listening on the same port, where each one will get its own accept queue, and each one will call accept() on their own queue, and the kernel will distribute the connections on these queues, as opposed to having many processes fighting for connections on one listener socket, trying to accept from the same queue. If you have a shared resource, you always have to have mutexes to protect it, right? See the docs for the kernel setting optimization for HAProxy Enterprise.
How fast can the backend read data? That's also interesting, right? If you don't read fast enough, because let's say you use the same process to execute, then you don't have enough stamina, if you will, to actually read, because your process is busy doing something else. Then, if you don't read, the receive queue will pile up. If you pile up, the client will say, "wait a minute, this process is not reading stuff, so I better tell the client to slow down," so the window, the flow control window, will shrink, and the client will slow down. That will all happen naturally, without you even knowing, just because you didn't read fast enough. For TLS, we have HAProxy evaluating a bunch of SSL libraries because each one has a cost as we've just seen with the basics of SSL. You need to do this right to make it as fast as possible, so there's a lot of room for improvement here when building your applications.

We talked about parsing a little bit. H1 consumes less CPU than H2 and H3 because it has a different binary protocol. We also talked about decoding the body, decompressing, and processing. You can delegate to a thread.

This is one of the best blogs I ever read back in 2021 from Willy. This inspired me to start this journey about the backend and all this stuff. It's how HAProxy forwards over 2 million HTTP requests per second. And I thought, how is that even possible? 2 million is a large number per second. I wanted to dive deep into that. It's a fantastic read. I think there is a new version they're working on.
There is, of course, this very recent blog post about The State of SSL Stacks. We talked about how, with SSL, there is encryption, and you decrypt, and there is the handshake, and you need to do session resumption. They did a comparison of all the SSL stacks, and it's a fantastic read.
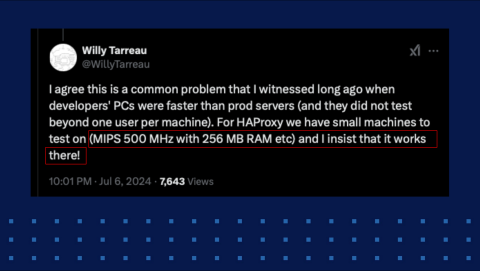
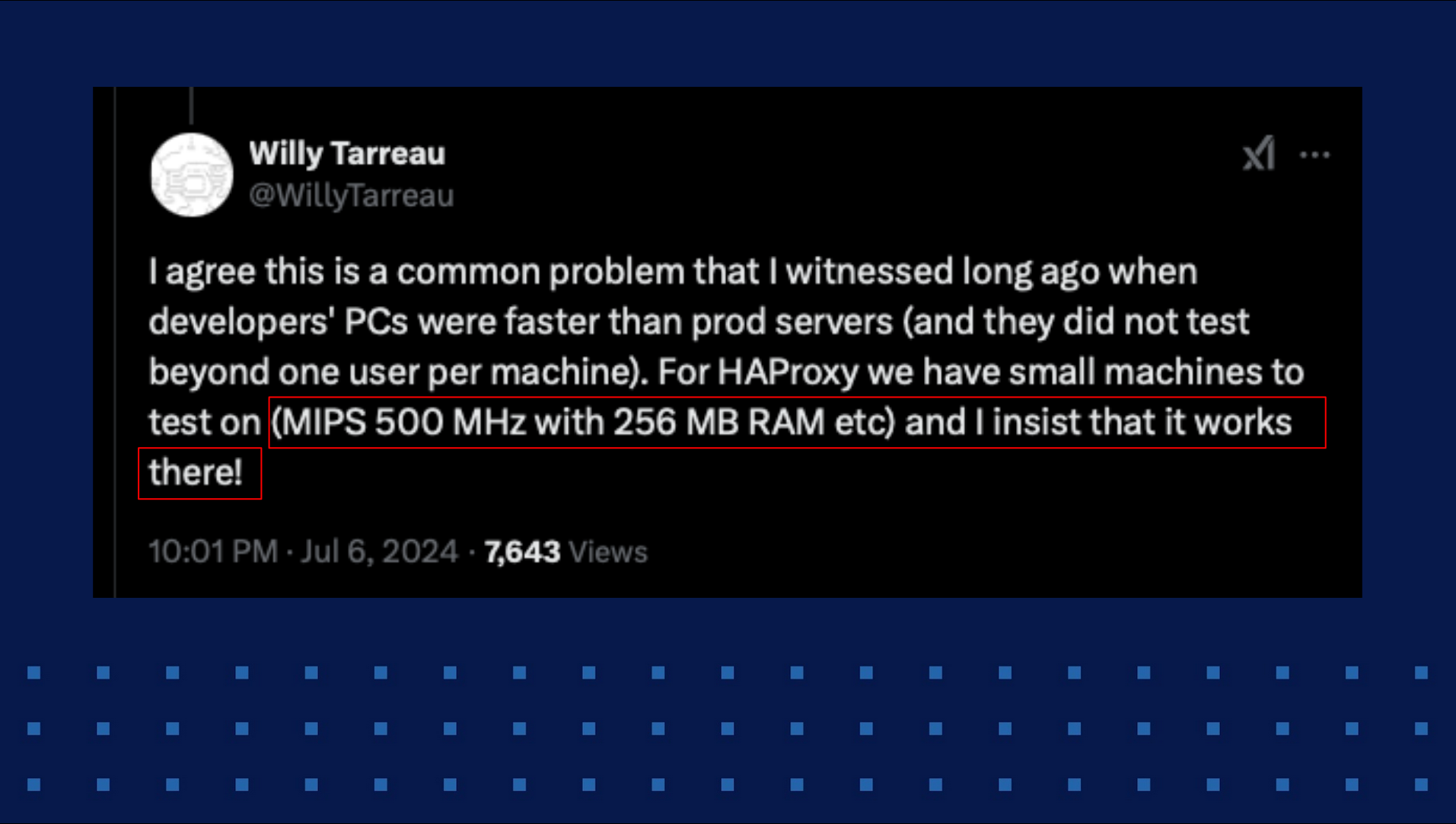
This is a very fantastic tweet from Willy. It's a reply to my tweet, "why does modern software feel slower?" What I said—the idea is because we keep developing on high-end machines, we mask bugs. We mask memory leaks. All of this stuff is hidden because we don't see it. All machines are great—I have 16 gigabytes of RAM; I have all these cores. I don't feel it. So what they do in HAProxy is they make sure the tests pass on a 500 megahertz, 256 megabytes of RAM machine. It's amazing. It's a challenge. I'm pretty sure it's painful, too.

There are some configurations that I'd like to go through. The first one is net.ipv4.tcp_rmem, which stands for the receive buffer. We talked about the receive buffer. When you establish a connection, you get a receive buffer for free and a send buffer. The send buffer is for the data you're sending. The receive buffer is where you're receiving your data. You can control how big this is in the kernel by this configuration. The default can be tiny, so HAProxy recommends changing that.
This is another thing I didn't mention: when we discussed the journey of the request, the anatomy of the request, imagine this journey for the CDN, which is a reverse proxy. There you have the load balancer, the API gateway, and then you have the actual backend. That, what we just discussed, decrypt, encrypt, decrypt, encrypt, is happening all over again. It's happening in the CDN, in HAProxy, the load balancer side, and it's happening on the API gateway because that's just another reverse proxy. It's also happening at the backend. The way I think about it, it's like a car slowing down as you put more obstacles on top of it. The request can be very fast and the throughput of the request can be very fast if it has the least friction possible. You can control the receive buffer.
You can control the send buffer with this option, net.ipv4.tcp_wmem. SOMax Connection (net.core.somaxconn) controls the maximum number of connections that can be left in the accept queue. Remember, when we establish a connection, it goes to the accept queue, and then when the user, when the backend, calls accept(), it pops from that queue and goes to the application, and then it's gone from there. If you have a slow application that doesn't Accept fast enough, then you will essentially have a problem. Clients will get an error connecting when this gets filled up, so you need to increase that a little bit.
Hey, we're done! That's all—the end. I'm going to leave it for you if you have any questions. Thank you so much—appreciate you guys.

Kelsey Hightower
I think this was amazing. I guess it's a simple question—did you just describe the fundamentals?
Hussein Nasser
Yes! Yes, yes! It might be boring for some, these fundamentals. But I love going through them. It's like reading the same book over and over again that you enjoy. You always learn something new. Even in this very presentation, I learned something. I paused for a second, if you noticed. I was like, oh, I just learned something, and I'm going to go later and contemplate on it. So yeah, fundamentals are everything for me.
Dylan Murphy
We do have one from the chat. OK, this one's about your approach to a new tech stack. So what's the first thing you do when you begin understanding a tech stack that's new to you?
Hussein Nasser
Okay, so the question is, "what is my approach when I understand a new tech stack?" First, if there is no desire, if there is no motivation or inspiration for me to pursue that stack, I don't even go there. I try never to go there because I'm forced to. And that is the most important thing, because if you're forced to do anything, then it becomes a chore. It becomes a job. You'll be bored. You'll be bored doing it. So then once you have that, the problem is solved. Because the rest is just me just flailing and understanding things. Like, okay, what is this? And asking questions. The only reason I ask questions is to actually get to the bottom of that stack. And very few stacks interest me. I'd rather spend a lot of time on the fundamentals. And then there is one that actually fascinates me. You see, there is a problem we have today. Not a problem, but a limitation. We have two transport protocols. That's all that we have today. We have TCP and we have UDP. Yeah, we have QUIC, but to me, QUIC is built on top of UDP. We don’t have a kernel-level transport protocol, as far as I know. That’s the only two that are really being used 99% of the time. The problem with TCP is, I mean, the good thing about TCP is it's a streaming protocol. That means, hey, I'm just sending a bunch of bytes. That's it. And then I guarantee order and flow control and all that stuff. But that doesn't have the boundaries of messages and requests. And UDP, on the other hand, doesn’t have guaranteed delivery, but it has messaging. We need both. We need something that has both. We need a message-based, reliable control that is focused on the message itself. And I think there's one that I actually covered on my channel. It's called HOMA. And it tries to bring those two together. And that's fascinating to me.
Audience
What are your thoughts on kTLS, something William Lallemand mentioned potentially in the future for HAProxy?
Hussein Nasser
I did not explore that. That's the first time I've seen it yesterday, actually. I want to go back and explore that protocol a bit. William's here, so you can talk to him after. Yes, William, I'm going to bug you later.
Audience
What stands out about HAProxy handling requests compared to other proxy solutions?
Hussein Nasser
Okay, so the reason I like HAProxy is because of the focus of all this stuff. Willy and the rest of the team focus on these fundamentals so much, and that's what says it all, right? Because who spends all this time and energy making sure their software runs on a 500 megahertz – with an M, guys, megahertz – CPU, right? And 256 megabytes of RAM. Just to have that mentality, that means your goal is efficiency. And to me, the most important thing is efficiency. How can I be as efficient as possible? And I think that goes into our human psyche as well. How can we be efficient? Because we have skills, we have talent, but what prevents us from being at maximum capacity is efficiency. We are so inefficient in most of the things we do. And that's why we have these conferences and we learn from each other to be as much as possible. And I think that's the reason HAProxy tries to be as efficient as possible in everything it does.
Dylan Murphy
If people want to get in touch with you or suggest something for you to cover on your podcast or YouTube channel, what's the best way for people to do that?
Hussein Nasser
Yeah, you can reach out to me at h@husseinnasser.com. Feel free to shoot me an email.

