While Kubernetes simplifies many aspects of containerized application management, optimizing traffic flow, especially at scale, presents unique challenges. This presentation by Zlatko Bratković , Hélène Durand, and DarioTranchitella, delves into how HAProxy addresses these critical networking needs within Kubernetes environments.
This session explores three key approaches to routing traffic: the established Ingress API, the forward-looking Gateway API, and the highly advanced HAProxy Fusion Service Discovery. You will gain an understanding of the strengths and limitations of each method, learn how HAProxy's robust features such as its runtime API and hitless reloads excel in dynamic Kubernetes environments, and discover the power of HAProxy CRDs for full customization.
You will have a clear picture of the diverse options available for traffic routing in Kubernetes using HAProxy, empowering you to choose the most effective solution for your specific application and infrastructure requirements, whether you're managing a single cluster or a vast fleet.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.













Zlatko Bratkovic
Hello, everyone. My name is Zlatko, and I'm here with Hélène and Dario. Let's start by explaining Kubernetes. I think most of you know what it is and have some experience with it.
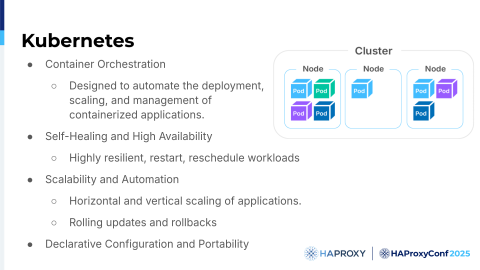
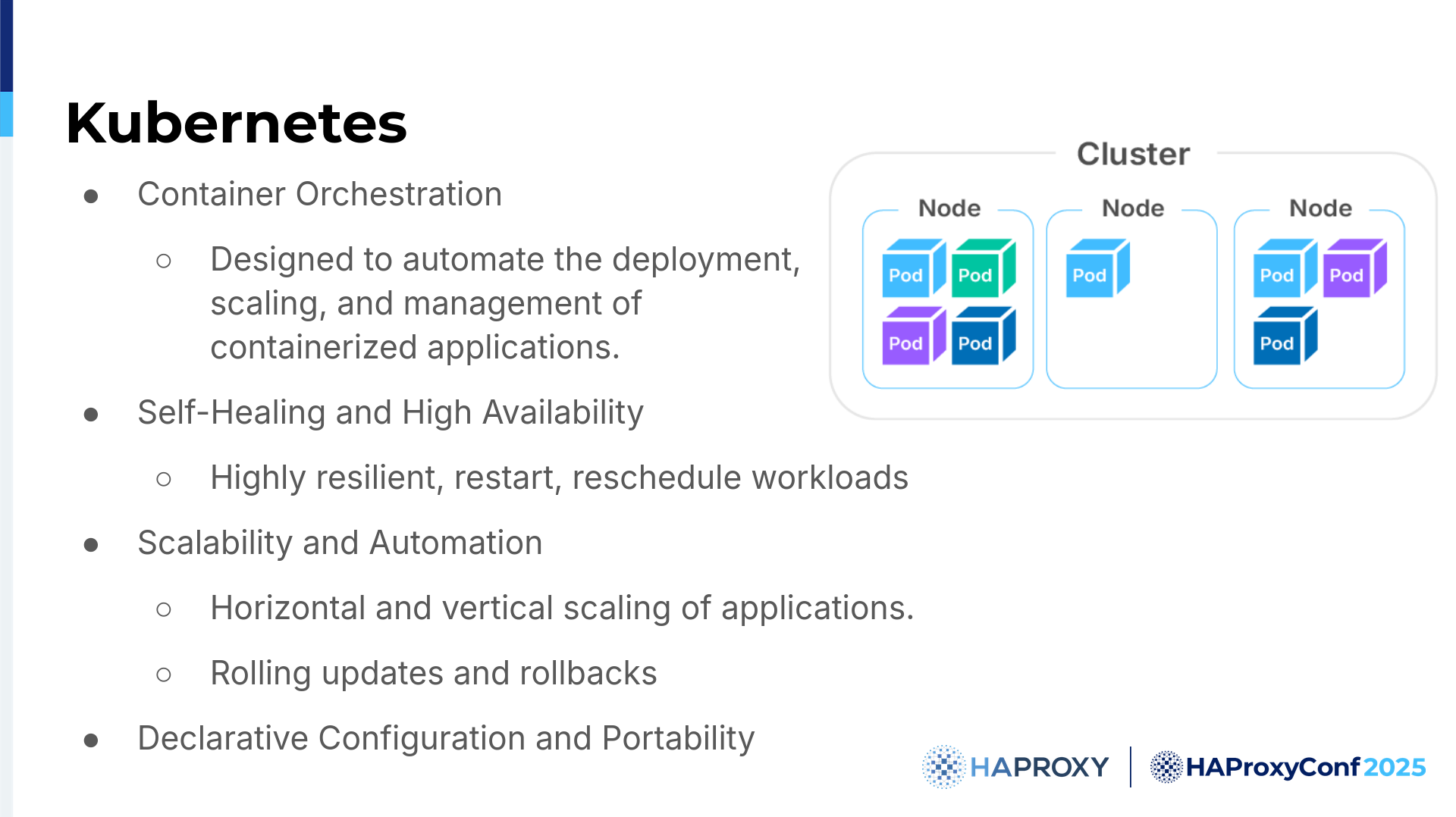
At its core, Kubernetes is an open-source platform. It's designed to automate the handling of containerized applications. Basically, it's making sure that applications can run anywhere in the cluster. You don't need to worry where they are, if they will fail or not fail, or if they are on-premises or in the cloud. Kubernetes is there to cover you.
Kubernetes operates on a declarative model, so you define the desired states and then the Kubernetes cluster continuously works to achieve that state. Of course, some errors might happen, so that state might not be achieved, but there are fallback mechanisms and the statuses that you can rely on. In this presentation, we will touch on a few ways of routing traffic for your applications with HAProxy.

We'll first touch on Ingress, then we will talk a little bit about the future with Gateway API, and at the end, we will cover HAProxy Fusion Service Discovery, which we can consider to be the most advanced way.

Let's talk first about Ingress and what we can do with HAProxy.
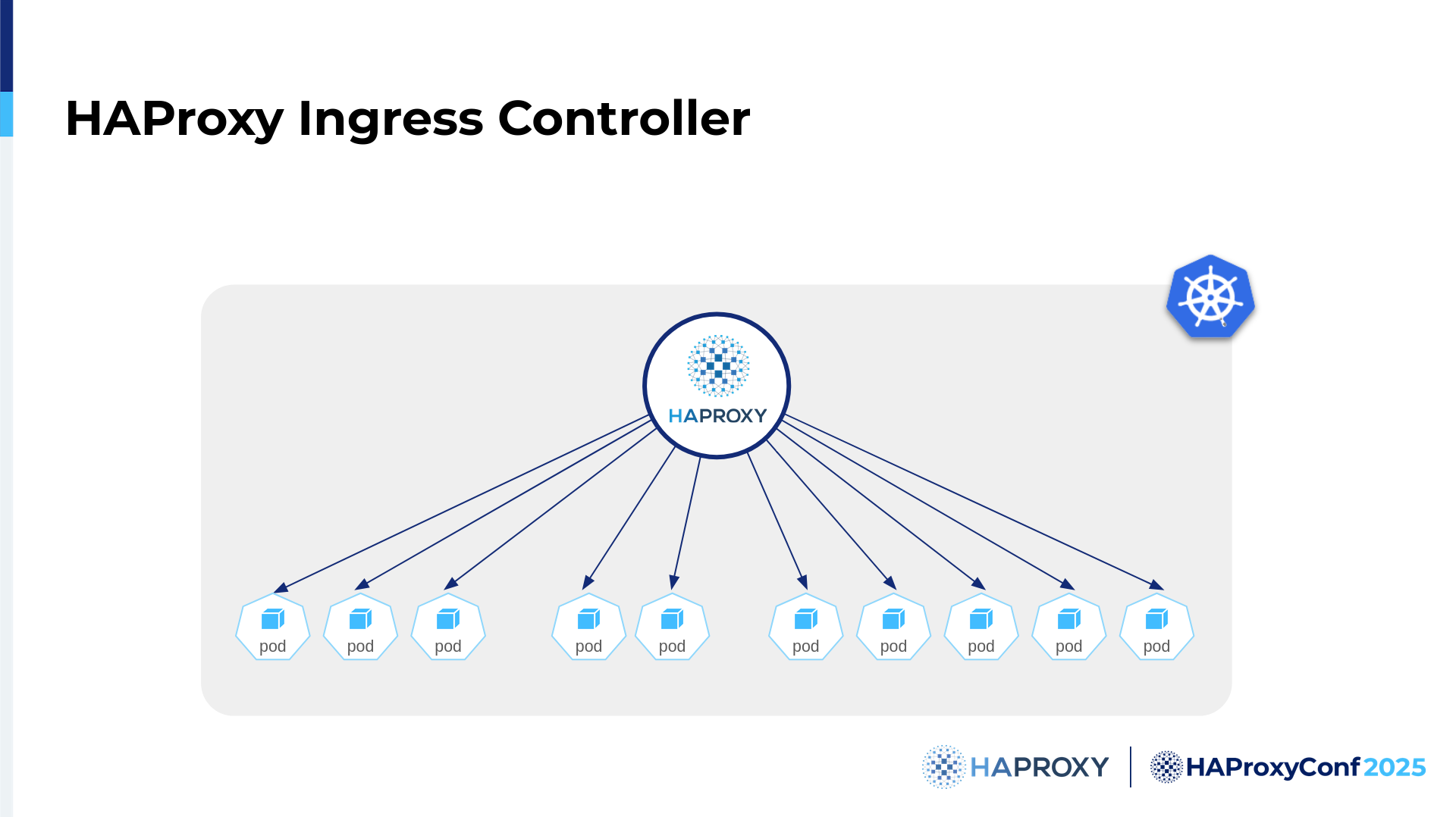
HAProxy is best known for its reliability and performance. It automatically fits all of the needs and requirements to be an Ingress controller. Compared to using HAProxy in general, there's not really a difference in how requests are load-balanced from a traditional standpoint. With HAProxy, it doesn’t matter if you are using Kubernetes, or on bare metal, or in a VM, or in Docker images, or anywhere else. HAProxy can handle all of those environments.
Specifically in Kubernetes, we know a high amount of traffic is expected, and the whole environment is highly dynamic because of the high number of Pod creations, updates, deletions, and even the moving and reallocation of Pods. For HAProxy, with its Runtime API and hitless reloads, we excel in such environments.

As I mentioned, Ingress is an object. It's part of the Kubernetes API and, in fact, the oldest API for configuring routing for incoming data. It has a relatively simple design and is used to describe traffic on Layer 7, or HTTP.
However, as this is the case with many applications, some applications can handle Layer 4 traffic, or TCP traffic, so that's not a problem. One of the biggest strengths of Ingress is actually that it's a standard, and it's part of the Kubernetes API, and it's quite stable. About five years ago, it became v1, even though its usage was quite common and a lot of people used it in beta status. In fact, a lot of things in Kubernetes in a beta state are production-ready.
One of the biggest things that we might say is that Ingress really has a simplistic design. You define routes and the service you want to connect to, but sure, due to its simplicity, not everything can be configured.
For that reason, we extended Ingress, as do all other Ingress controllers. We added a lot of annotations, and we did that to unlock the full power of HAProxy, as annotations can also be set at multiple levels. So, you could set an annotation globally with a ConfigMap, or just at the Ingress level or the service level. There's really high customer facility and complexity you can do with this setup. Over time, though, we saw that users were having difficulties combining all the possible options. For that reason, we introduced HAProxy CRDs that match the HAProxy configuration sections. This allows users to fully unlock all of the power that HAProxy has in different environments.
When I say all, not everything is currently implemented in a CRD, but the next version we plan to release will have the rest. It's important to note that the schemes or CRDs that we have are basically the same as those present in the Data Plane API and HAProxy Fusion.
So, across all of our applications, you can do the same setup and use similar approaches in all applications. That's really nice, because you don't need to learn anything else. It's basically just the same thing in a different way.
For example, compared to Data Plane API Open Scheme, for Ingress, you just add the metadata that Kubernetes requires; nothing else is needed— everything else is pretty much set up.
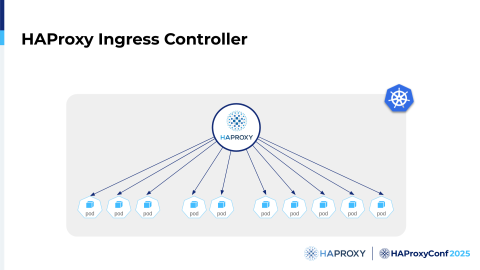
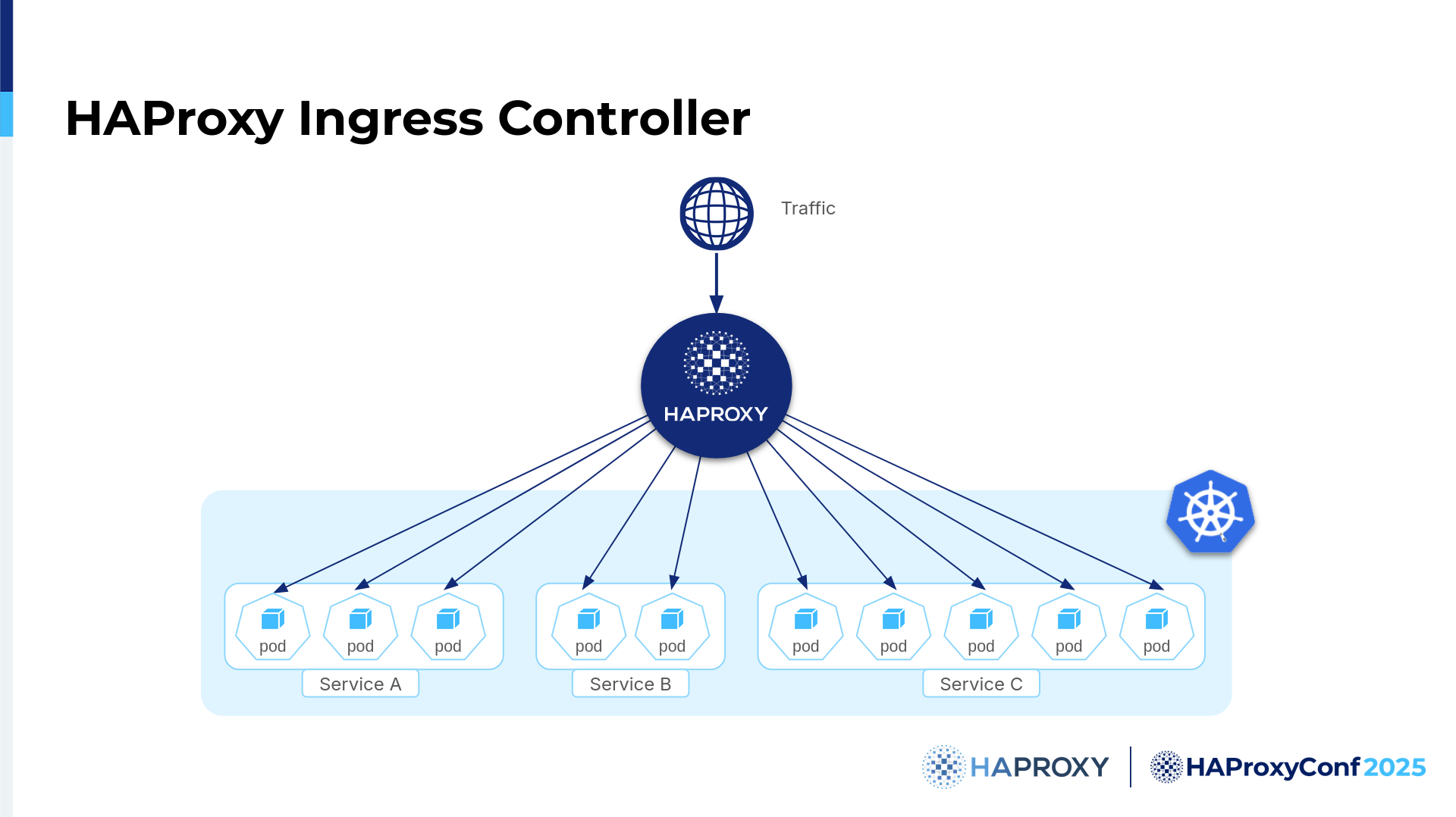
One of the big strengths for our Ingress controller is that we wanted to avoid extra hops. That is, not routing traffic to the Service, but directly to the Pods. There are multiple reasons why. It improves latency, as you avoid one extra hop, but you also allow the controller to directly see what's going on. As it has checks, it can respond much faster. Plus, if you use service-level balancing, you're limited on what you can do with it.
Just as a side note, one really, extra-cool feature is this: even though the Ingress controller is primarily designed in a way that you can run it, and you need to run it, inside of Kubernetes, ours can run in external mode.
You can actually start it outside of Kubernetes; it doesn't need to be run inside. How is that achieved? It's a complex topic, but we have a really nice blog post on our haproxy.com page, where we explain. There are some tricks with the networking, but it's pretty simple.

In general, the Ingress controller allows for any kind of traffic routing. At the same time, it allows you to configure basically everything that you can do in HAProxy everywhere else, so you're not limited by what you can do with Kubernetes objects and its API. We have extensions that allow you to do that. They are most interesting in terms of customizing routing, but also for security purposes like rate limiting, bot protection, and WAF.
That's the overview of Ingress controller. I will pass it to Hélène to talk about the future with Gateway API.

Hélène Durand
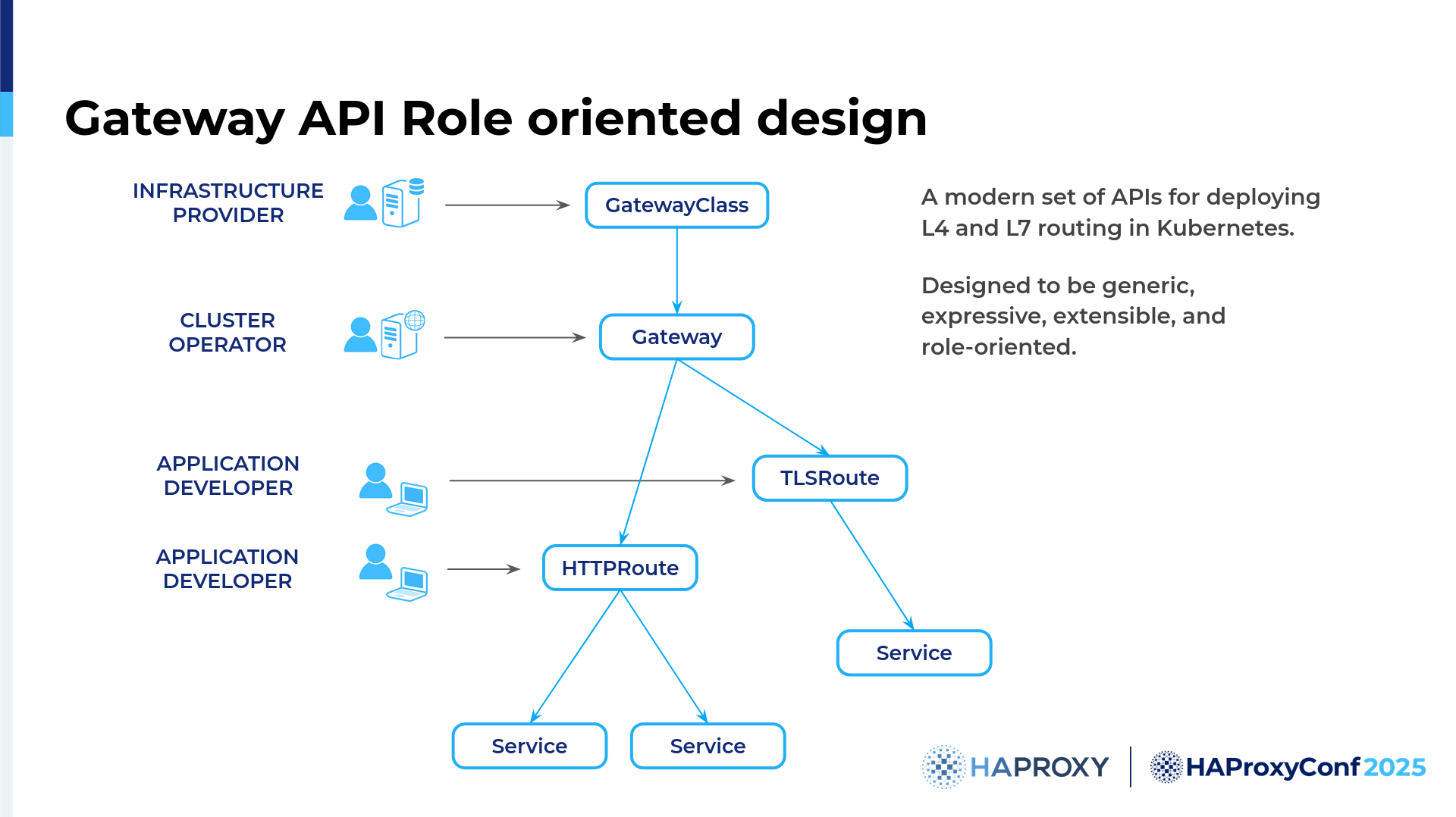
Thank you, Zlatko. OK, let's now jump into an overview of Gateway API. It is a Kubernetes networking API that is designed to eventually replace the more limited Ingress API.
It was launched in 2019 and reached v1 in 2023 for its core concepts: the gateway, gateway class, HTTP routes, and reference groups. However, its other features remain in alpha or beta stages.
So, what are the key features?
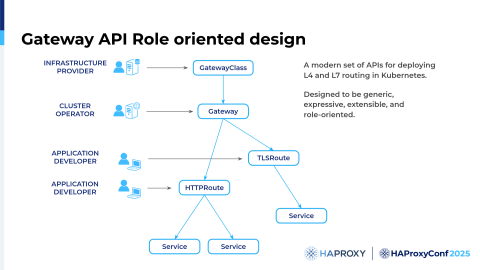
It has a role-oriented design. It splits responsibilities across different teams. It is extensible.
The Gateway API is not built into Kubernetes, but it uses custom resource definitions, CRDs, to define the various objects. Unlike Ingress, which was mainly limited to HTTP, the Gateway API introduced, for example, TCP and UDP routes. It also offers cross-namespace support. The routes can exist outside the gateway's namespace. Compared to Ingress, the Gateway API is designed in a way that allows multiple teams to handle their own parts of the routing. For smaller companies, that would probably be the same person. Larger organizations, however, would typically have dedicated teams. That way, developers do not need to know or even worry about the infrastructure part of the routing.
So, what are the plans for HAProxy for the Gateway API implementation?

As Zlatko said, the Ingress Controller has been in development for more than seven years now, and we have learned a lot about customer needs and usage in that time. We are applying all the lessons learned to the Gateway API implementation.
One of the main lessons that we learned is to think big - really, really big.
No one could foresee the scale at which Kubernetes would be used, and neither did we. One huge part of the API experience is observability. We need to be able to easily track and observe how the traffic flows; a big part of this is logging and metrics. For example, we experienced that just having log levels is not enough. We plan to extend this to define a lot more fine-tuned settings for logs and metrics.
The advanced configuration of the logging will be done dynamically and will be as easy as updating a custom resource. We will also benefit from the Replay tool, which was developed for the Ingress Controller, and Zlatko will explain more about it a bit later in this presentation. This tool will allow us to test our implementation for huge clusters.
Of course, we will also rely on dedicated HAProxy CRDs, similarly to what we have done for the Ingress Controller, to fully customize all the HAProxy configuration sections.
As the Gateway API is evolving, we will also evolve with it.
The paths that are now in alpha or beta will gradually be updated as soon as they upgrade to v1.
So, for community users, we are announcing a new product that we have started to develop: the HAProxy Unified Kubernetes Gateway. It will offer a Gateway API implementation with a design similar to our current Ingress Controller.
Like the Ingress Controller, this gateway will also run in a single Kubernetes cluster.
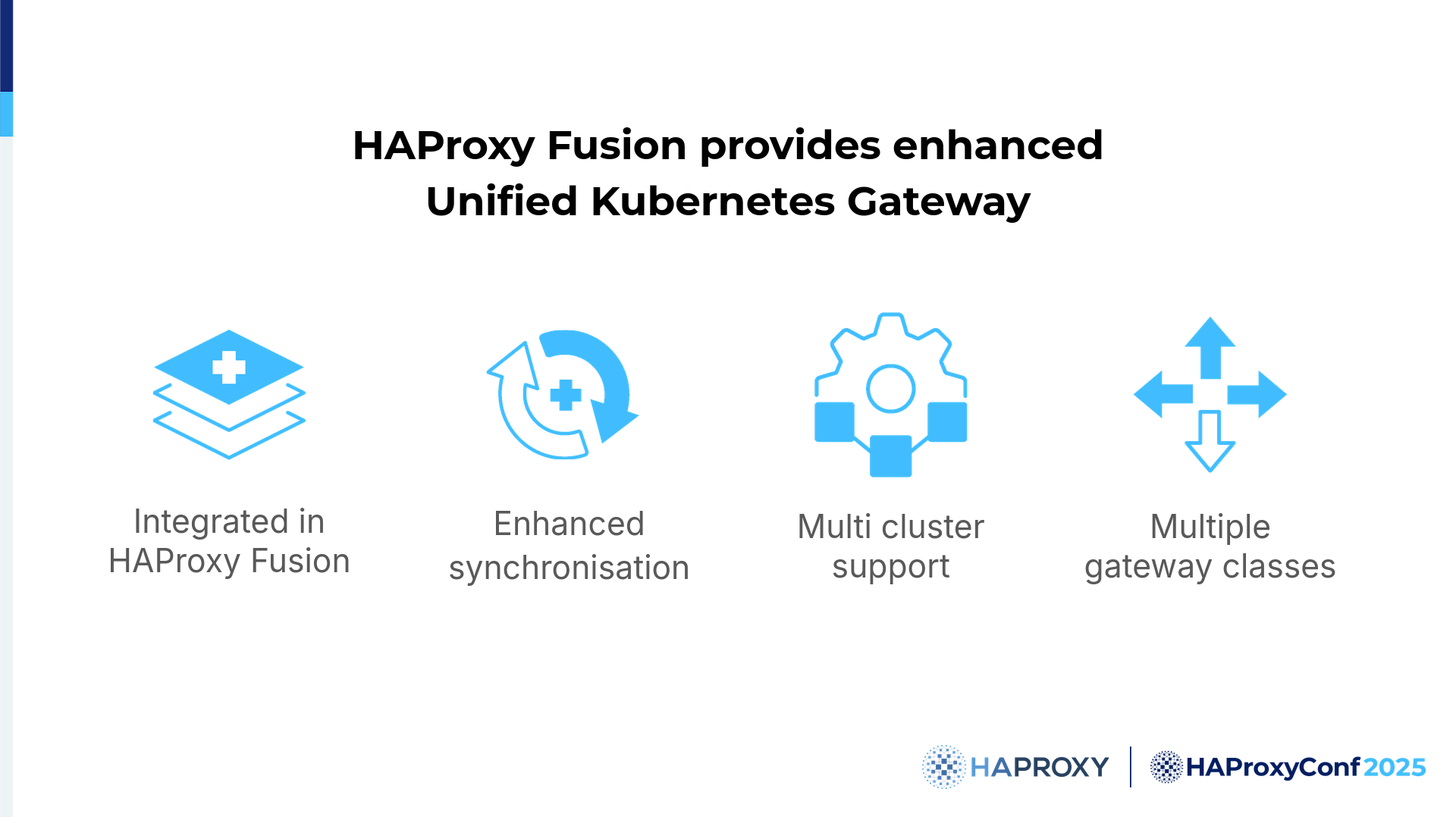
On the enterprise side, the Unified Kubernetes Gateway will be integrated into HAProxy Fusion. It will support multiple gateway classes, and the integration into HAProxy Fusion will automatically bring all the powerful features of HAProxy Fusion that you were shown during these presentations at this conference.
Among the most exciting features of the Gateway API that we can mention are that we will get a federation of multiple Kubernetes clusters, which is a huge plus, and enhanced synchronization between all the HAProxy nodes. I will now leave the floor to Dario, who will talk about the next option, the Service Discovery options.

Dario Tranchitella
Thanks a lot, Hélène. We have already had some talks about the HAProxy Fusion Control Plane, which is our single pane of glass that orchestrates a lot of HAProxy instances. So, it's great to be here to talk about both Kubernetes and the HAProxy Fusion Control Plane because there are a lot of similarities between them.
In Kubernetes, we use and orchestrate Pods. Inside of HAProxy Fusion, we orchestrate instances of HAProxy.
Networking is very complicated in Kubernetes. I used to be a site reliability engineer, and there are plenty of pains in Kubernetes. We have storage, but we also have the network. We learned by interacting with the community and our customers that we need to create a framework to empower them to create products on top of Kubernetes with their own business cases.
We saw something similar with the Ingress class and the Gateway API in platform engineering. Essentially, we have developers, admins, and platform admins, and we need to empower them to use Kubernetes without any issues. Kubernetes has multiple ways to do networking, including Ingress and load balancers.
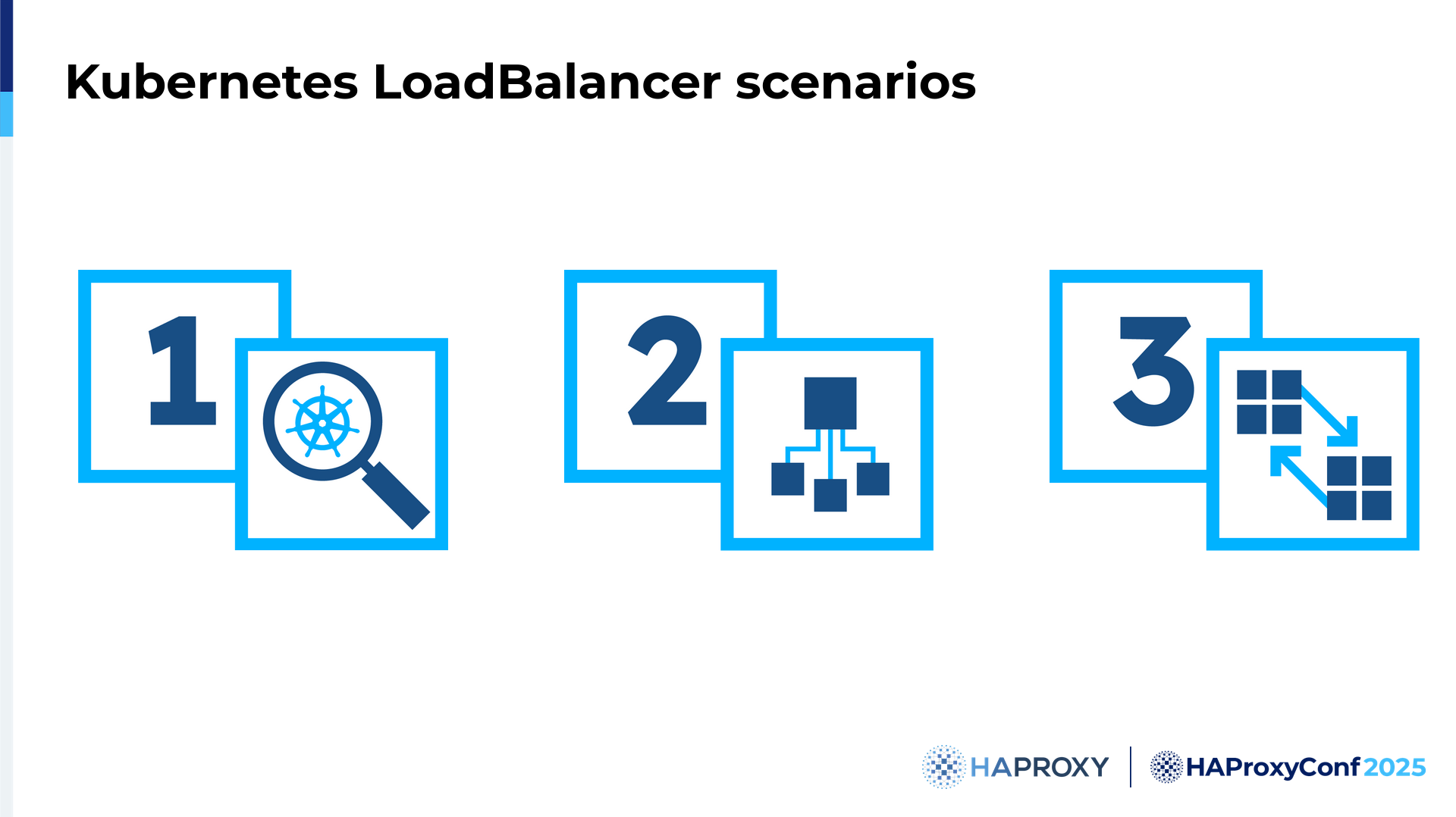
For the sake of time, unfortunately, we will explore just three use cases, but I'm pretty sure that these are interesting for all of you who are using Kubernetes. We have the Pod discovery, the load balancer, and the multi-cluster routing.
Right now, we will just talk about one Kubernetes cluster, one controller, but the real power of HAProxy Fusion is that we can tame a fleet of Kubernetes clusters. When I was doing site reliability engineering for Kubernetes, even just having one cluster was very painful, so you can imagine what's going to happen if there are a dozen, a hundred, or a thousand Kubernetes clusters.
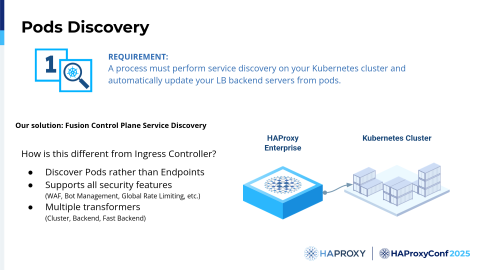
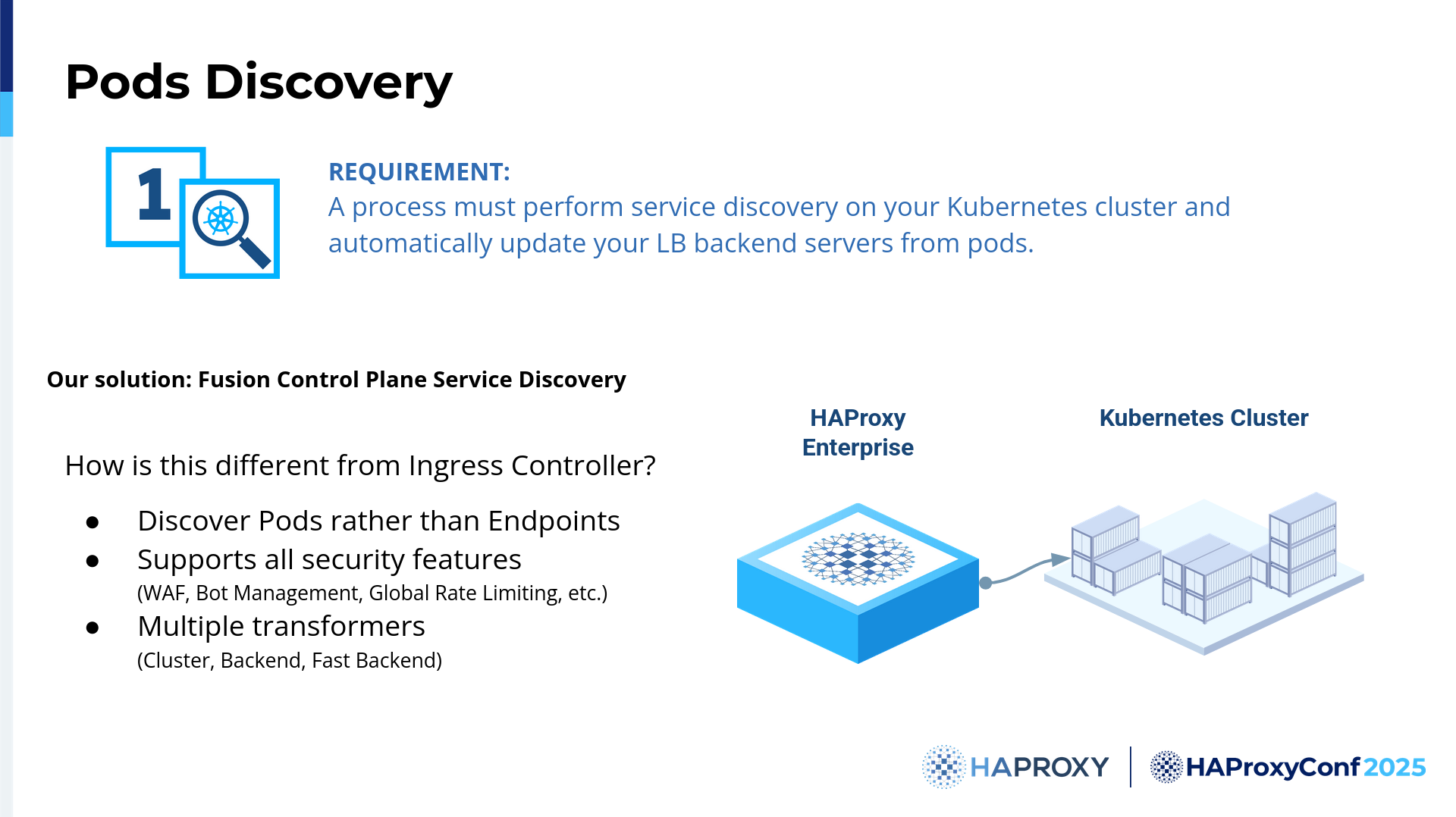
So let's start with the Pod discovery. We all know that in Kubernetes, we have Pods. The Pods are our applications, and we want to discover them.
It sounds pretty similar to what an Ingress controller does, right? Well, in HAProxy Fusion, this is the backbone to create something for your use case. In HAProxy Fusion, you can discover Pods according to the Services. These Services can be NodePort, so we can easily target the node ports, or we can target the Pod IPs. You can do that easily by using the Services of Kubernetes, and we also have all of the features powered by HAProxy Enterprise Edition.
What we love is that we have the same platform engineering concept in HAProxy Fusion. Essentially, you have the developers, who deploy their own applications, and then the cluster administrators, the HAProxy Fusion cluster administrators, can specify which transformers are needed. Do we need to create just a backend, so an HAProxy backend, or do we need the front end and backend together? Or we can use the fast backend transformer?
We are going to have a very interesting session from PayPal, which is using HAProxy Fusion Control Plane. They were looking for a solution to tame thousands of Kubernetes Services. It's very interesting because we work together with our customers, trying to understand their needs and address the scale of their needs. You can use Pod discovery to target any Pod and easily have a building block for your service mesh.

My background is as a site reliability engineer. I used the cloud, but I built it for customers. We all know that the cloud is very cool because in the cloud, when we need storage, we just need to create a persistent volume claim, and we've got the storage.
But you can imagine that if we need a load balancer, we need something that drives the external traffic inside of my Kubernetes cluster, so I'm talking about LoadBalancer. With HAProxy Fusion, essentially, we implemented native support for Kubernetes where you can define an IPAM definition to say, "I want to get these IPs automatically assigned to my Service of type LoadBalancer." And trust me, on-prem, this is very hard. So with HAProxy Fusion, we are making that simple. You see here that we have the IPAM definition, and that the IPAM definition is cluster-scoped.

It means that at the same time, we are addressing the platform engineering division. It's a cluster resource so that the cluster administrator can define the ranges of the IPAM for each cluster, and then the developers just need to create a Service with a special annotation.
It seems like magic— what we are doing is that we are automatically assigning the IP to that Service, and that service will then be backed by one of the HAProxy instances that we are empowering and coordinating with HAProxy Fusion.
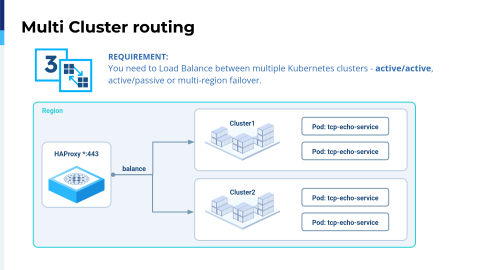
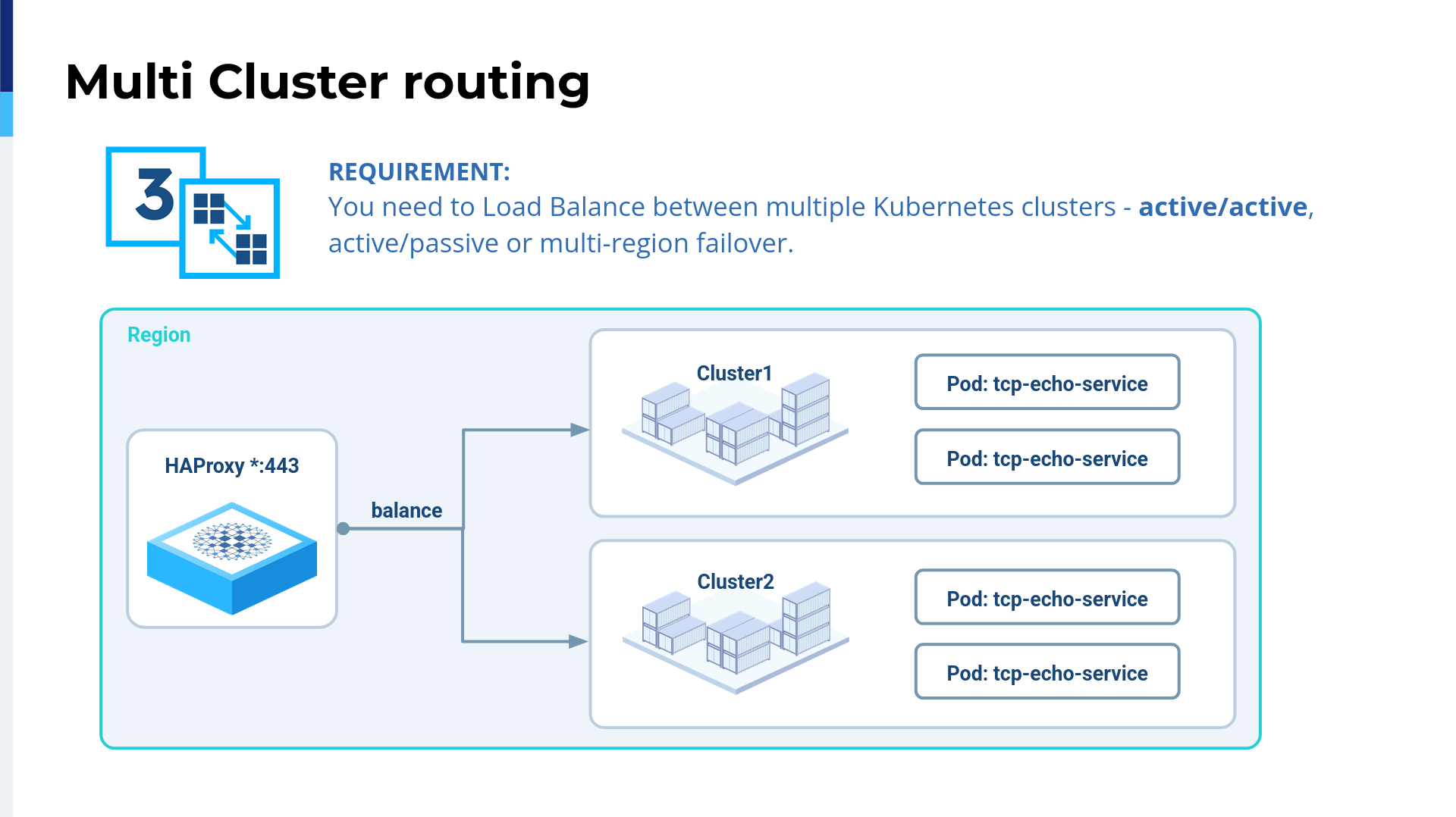
Also, we encountered another taming problem with Kubernetes because it's multi-cluster. When I started my journey in Kubernetes, I managed just a single cluster and still lost my hair. You can imagine what would happen if we had multiple clusters.
Anyway, with HAProxy Fusion, we have multiple ways to target not one but many Kubernetes clusters. We have here the third example, which is active-active. It's very complicated because you may have a team that needs to scale their applications across a fleet of data centers. You can also do this as active-passive, but using an active-active configuration allows you to scale your applications.
HAProxy Fusion easily covers this. When you create a Service Discovery resource definition, you can select as many Kubernetes clusters as you want. We get a unified configuration tracking for all the pods.
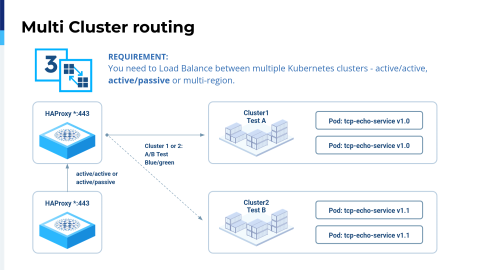
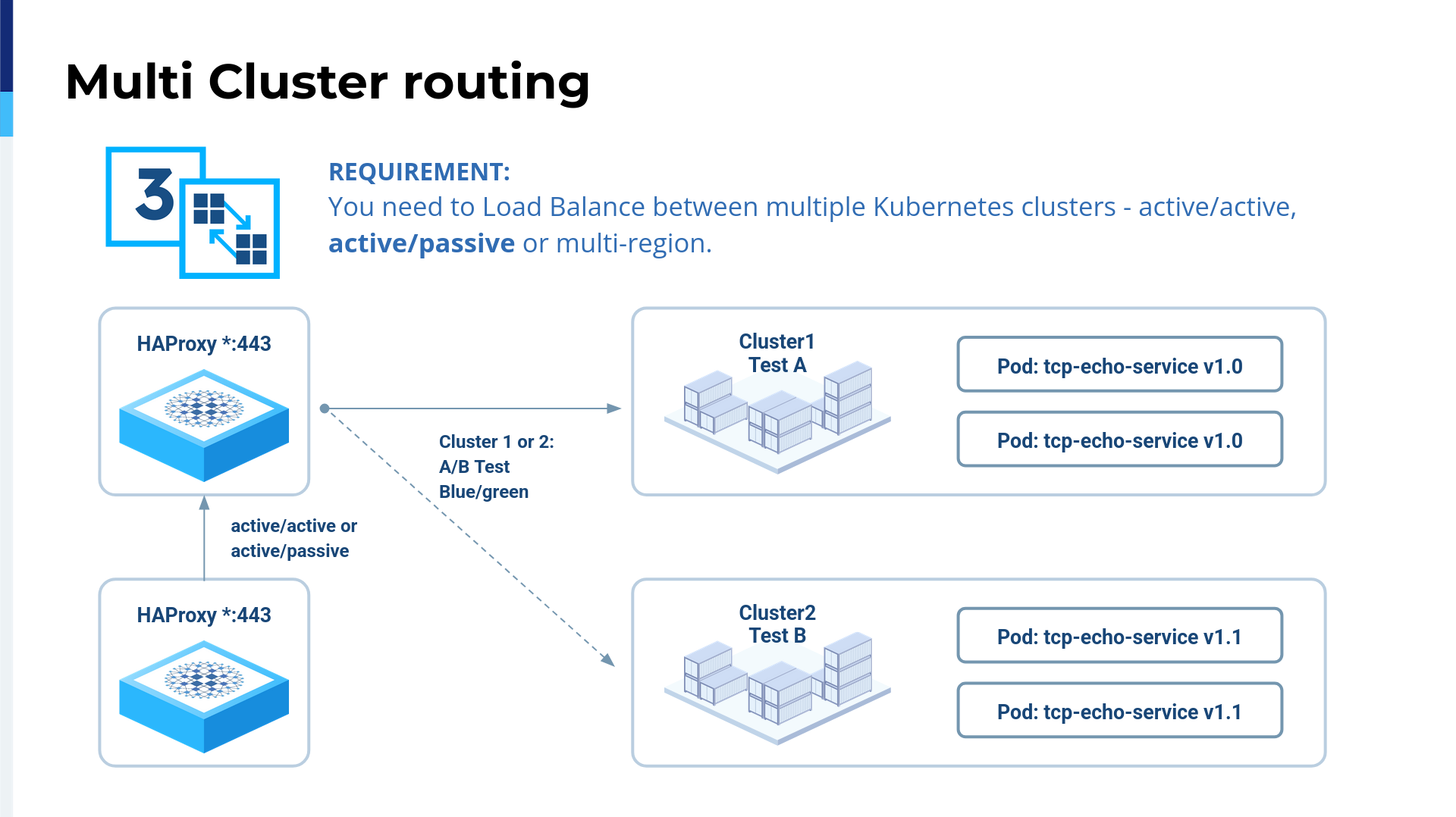
We also support active-passive, so it's up to you.
HAProxy Fusion is not just a product. As I said before, it can be used to create your own business logic.
The active-passive configuration can be very interesting, especially if you have workloads that rely on the state. In the end, everybody would like to have storage active-active, but sometimes there are some policies for distributed computing. What you can do with HAProxy Fusion is track one cluster and another cluster, and then you add the switch to forward all the traffic. This could also be very interesting for doing a sort of A-B testing in real life.
It's that simple, thanks to HAProxy Fusion always using the Kubernetes primitives. Very interesting.
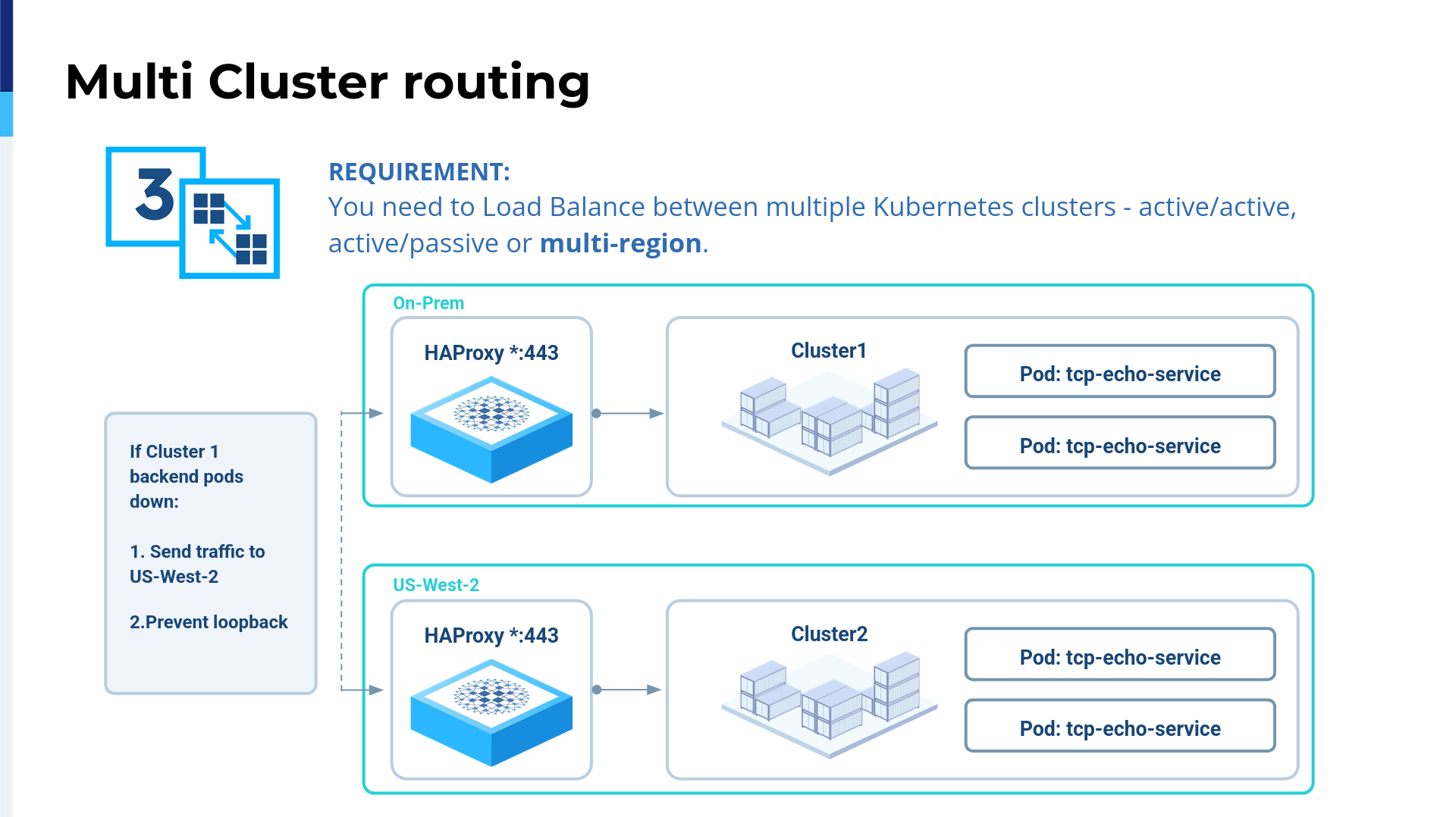
Last but not least is the multi-region support. As I said before, we were used to running Kubernetes on the cloud because it's that simple. We are living in 2025, so Kubernetes is not complicated anymore.
Maybe. Who knows?
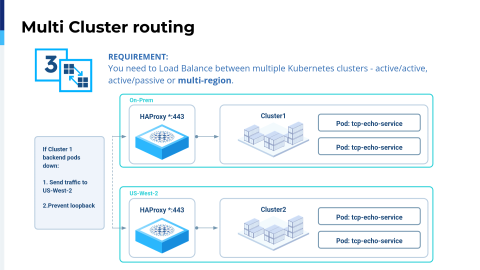
So yeah, it's complicated. "It's not stressful at all, Dario."
Essentially, one of our use cases is that we want to have multi-region support, where multi-region could be even multi-cloud— AWS, Azure, DigitalOcean, Oracle, even on-prem. With HAProxy Fusion, you can get multi-cluster routing easily for the cloud and then also on-prem, and you can create your own network mesh. Of course, it really depends on the network, but this is feasible.
What I really, really love about HAProxy Fusion is that it has been designed according to the customer needs and also uses the experience we witness as Kubernetes developers. What I really love about HAProxy Fusion is that we can have the same networking experience across different infrastructures. It doesn't matter if it's on-prem, if it's AWS, or if it's Azure.
We are simplifying because we are creating an abstraction for each cloud provider. Essentially, it's like Kubernetes. We are using Kubernetes because we don't want to get infrastructure lock-in. What we are doing with the HAProxy Fusion Control Plane is taming the networking in Kubernetes. Maybe I spoiled a few of the lessons learned, but I'll pass the control to Zlatko.

Zlatko Bratkovic
I want to mention a few things that we learned over the years because we have been involved in Kubernetes for a long time now. Let me start with the first thing. The Data Plane API, HAProxy Fusion, and Ingress Controller all share definitions for customization on everything.
As I mentioned before, we have CRDs in our case, and HAProxy Fusion and Data Plane API have the OpenAPI scheme. This offers you a lot because even if you are switching across our products, you are always somewhat familiar with everything that we offer. Sure, for some cases, as I mentioned, for the Ingress Controller, you need to add some extra data that acts as metadata due to Kubernetes' nature, but the core is the same. What you see in Data Plane API and what you can do with Data Plane API, you should be able to do in HAProxy Fusion, and you should also be able to do it in the Ingress Controller. However, on top of that, technology is changing constantly.
Besides that, our understanding of the whole process and routing traffic in Kubernetes has also been greatly improved.
One of the things that we learned is that—and it's quite obvious when you go to the conferences and ask people how they use Kubernetes—everybody is practically saying, "oh, we love Kubernetes, we use it. However, we have our own use case that doesn't exactly fit. We have this and that, left and right." It turns out that about 90% of people actually have something that they have customized or need and have a desire for that.
That's why I think the power of CRDs and the ability to have full options from HAProxy is highly useful, because you are not limited to what you can do with our kind of controller.
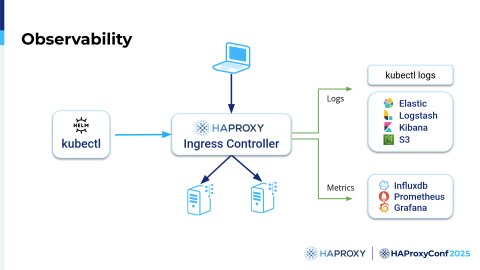
So one of the biggest challenges we face is troubleshooting. Why?
Because Kubernetes clusters are only getting bigger and bigger, we have more metrics data and need to understand more about what's happening. Metrics data can be really helpful when dissecting issues. But as clusters grew, we reached the point where complete replications or simulations of what is going on have become a challenge all their own.
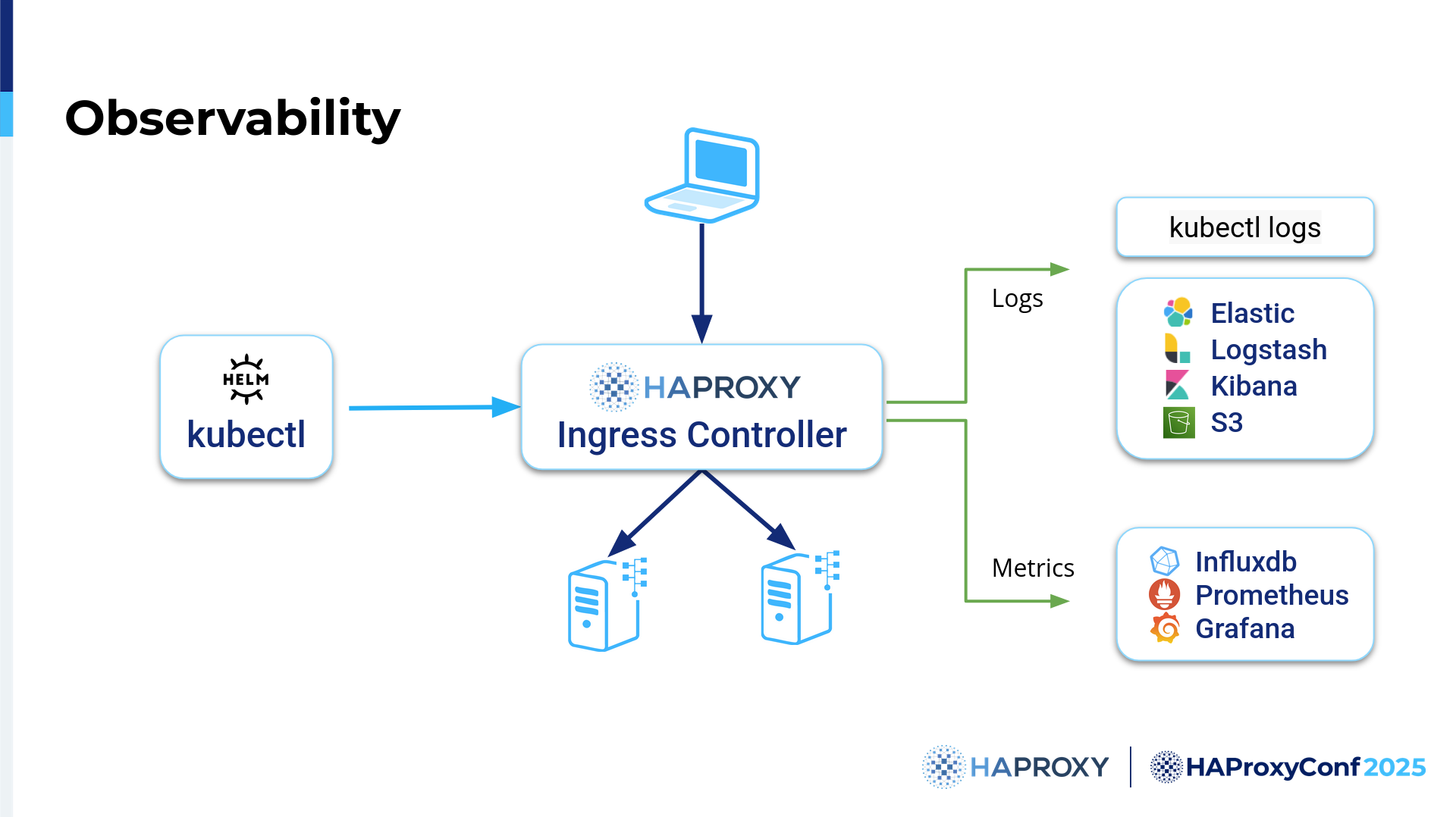
So, for that reason, over time, we expanded what we can do with logs and metrics in the Ingress controller, and I'll explain this in the next couple of slides. The point is, you can use kubectl, but there are so many logs, and there are so many things that it's practically impossible and unusable.
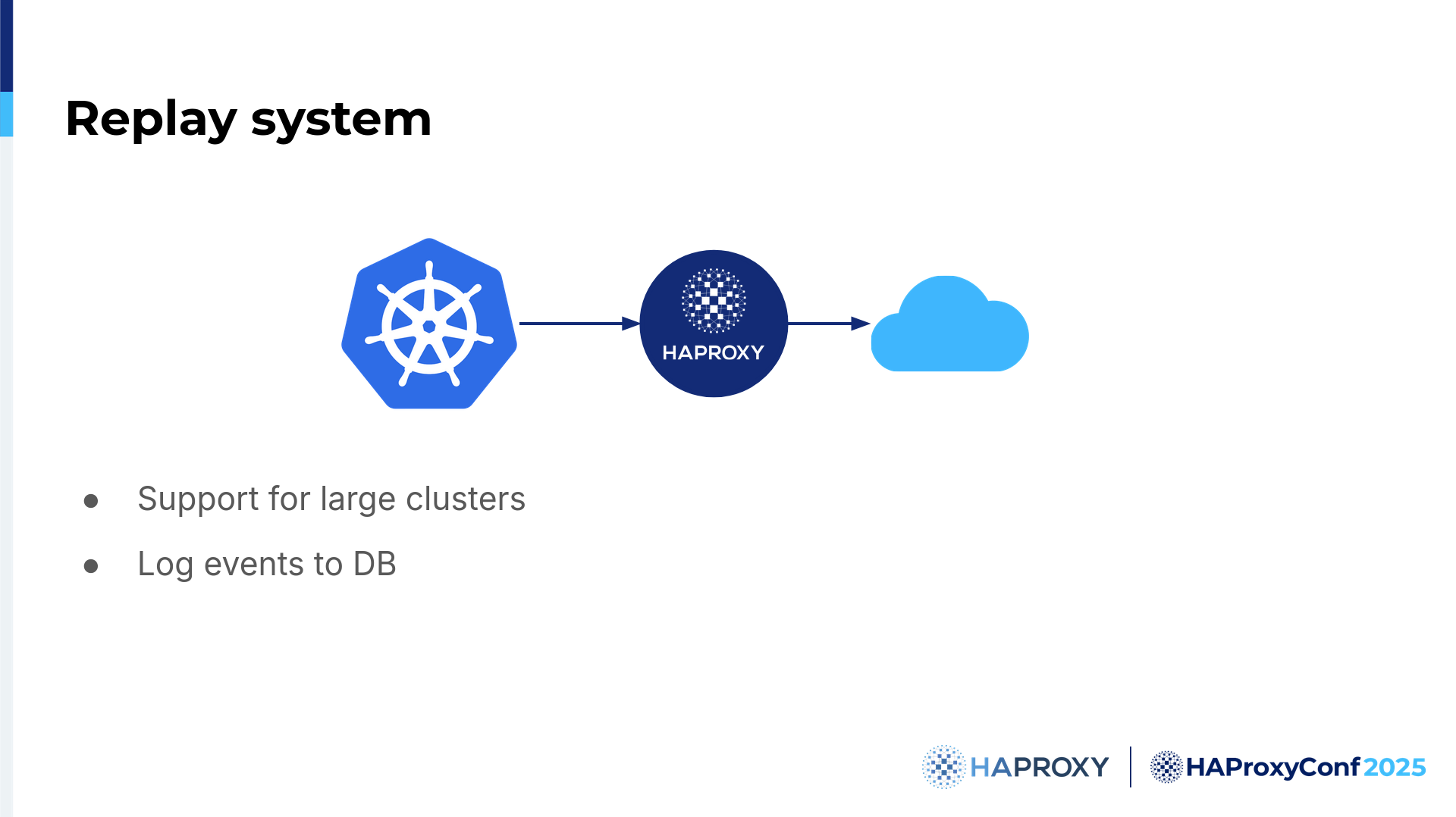
To enable us to troubleshoot what's really going on at certain points in time, we allow the logs to be pushed to various databases, and metrics can be pushed basically anywhere, depending on what you actually need. We use that system to create a sort of Replay system.
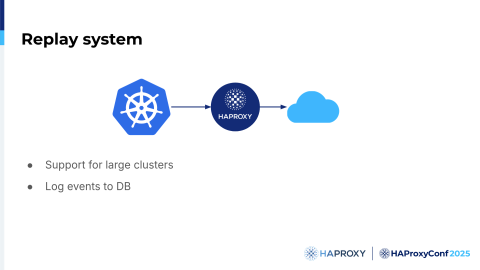
So what is it? It's primarily designed for the Ingress controller since Gateway API is still in the works, but now the size of the Kubernetes cluster is not really relevant to us. We can now easily reproduce a cluster of any size. So what's the idea?
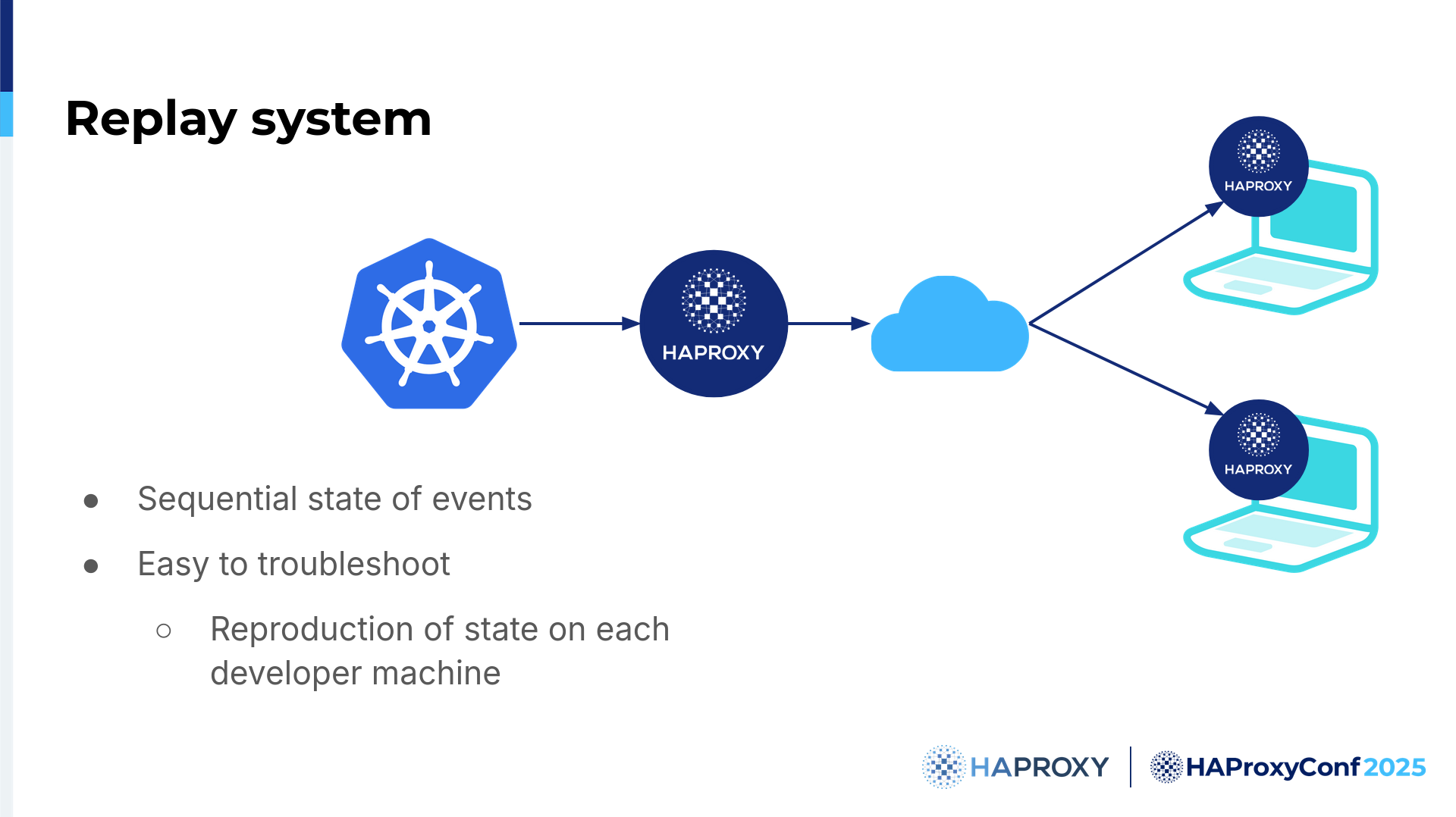
The idea is this: we log all relevant Kubernetes events that we have, as we can do that in the Ingress controller. It works on just a single machine or a large number of machines. Because we need reproducibility, we can reproduce the entire state. We can do it as many times as we want; we can stop the world, see what's going on, and examine everything, which is highly useful to us.
For example, we can try to generate any kind of cluster in a lab environment, but we all know that there are a million tiny points and a million tiny configurations that you cannot really reproduce, especially from customers with large clusters. Even if they are highly detailed in telling you what they actually have, it's very difficult to reproduce huge clusters on the scale they have.
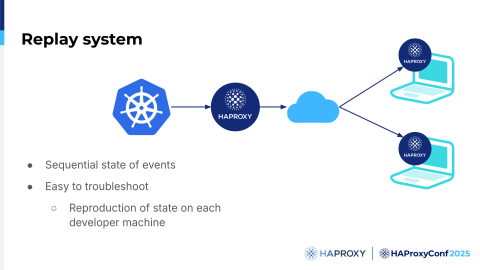
Real data and real complexity have now become almost impossible to replicate, but I say impossible to replicate, but not impossible to reproduce. Why?
Because, with this system, we can do it, and it's not a problem. For example, we had one specific customer who had a problem during an update; it was a really complex system with a huge amount of annotations on multiple levels—they used practically all the features they could—and just having to figure out the cause of the issue was difficult, so we needed to improve things.
This kind of system allows us to scale up and see what's going on perfectly because we have been able to literally jump into a reproduction of their production environment without touching it. We improved the whole update procedure 450x in speed over this year, so not a small amount, and we actually did it really, really fast.

To conclude, we have multiple options for how you can use HAProxy in Kubernetes, and I think we have something for everyone. For the community, we have multiple projects, but for HAProxy Enterprise, HAProxy Fusion is the centralized Control Plane.
As for real-world examples, we will have two presentations today because I think the best way to see what's going on is to allow other people to talk about how they use our products. One from PayPal to see how they use HAProxy Fusion Service Discovery, and another one later in the day from DeepL about their usage of the Ingress controller.

If you have any questions, please feel free to reach out to us. Thank you!


