In this presentation, Julien Pivotto explains how Inuits uses HAProxy in an unconventional way: as a forward proxy to route outgoing traffic. This unique use case has uncovered a trove of useful features within HAProxy. They have leveraged HAProxy to upgrade older applications to newer versions of TLS transparently; It lets them connect to servers using DNS but fallback to IP addresses if the DNS records can’t be resolved; It allows them to rewrite URLs, specify access controls, set application-specific timeouts, implement canary releases, automate rollouts after a specific date, and get detailed metrics.

Transcript
Hello, hello. So my talk will not be about performance. It will not be about scale because I come from Belgium, and basically, in Belgium, we have nothing at a very huge scale. My story will be about how we use all the features that HAProxy can provide us to achieve exactly what we need to achieve. Setting up the scene. This is about using HAProxy to send requests to the outside world.

Usually, what you do is you put HAProxy at the beginning of your infrastructure and then you route the traffic going in. What we want to do is actually to go out to the Internet, to some private lines, to actually make HTTP requests from HAProxy. This means that the client will be HAProxy and we will offload a lot of things to HAProxy itself. For example, replaying requests that might fail or throttling requests, which means that if a partner is like getting slow, then we don’t want to continue sending it request and request. We want, maybe, to say for that, but for now we only send a limited number of requests at the same time so we don’t overload our own applications.

This is about a message worker in Belgium. Basically, we have a lot of different partners that we need to send messages to. The difference between Healthcare services and other kinds of things is that more often you want the transaction to arrive at the other end and you don’t care that much about performance. So first, it was more important that we knew that the transaction was successful than if it was, like, done in a few milliseconds. With HAProxy we get both, so we are quite happy with that.
Challenges
We also have a lot of services and it means that we have some new ones that are like a few months old. But we also have some services that are like 10, 20 years old that are still running and that are still doing some kind of business. So we still need to maintain older stacks from very old and very new technologies. And another thing that’s important is that we utilize SOAP and REST APIs. So, it’s not about that we don’t need to do a lot of follow-ups on the HTTP request. We only get like straightforward URLs that we know in advance. So it makes older quite easy because of that. Those very old technologies don’t change that much.

One of the challenges that we had that actually forced us to find a solution was that, at some point, you want to migrate your TLS version. At some point you want to use SNI. And guess what? 10 years old, 20 years old technologies cannot do that kind of thing. You cannot suddenly take a very old stack and say, “Yeah, no. We use TLS 1.2.” If that technology didn’t even know about TLS or what was TLS. We wanted to get away, to move, to get that moving and to still be able to move forward with those very old applications. So, we wanted to find a way to do this, to talk to the latest technologies to the outside world. And we wanted that to be quite easy. We didn’t want to spend a lot of time developing applications, developing stuff…developing, I don’t know which kind of service mesh. We wanted something that would bring us quite easy forward.
Architecture
How does it look like? Basically, we have a bunch of applications in different VLANs and they will all talk to an HAProxy server, a cluster HAProxy servers.

That HAProxy server will be responsible to talk to the Internet or to a lot of private lines. So, it’s very important that I mention private lines explicitly because when you talk to the Internet there are some rules like: you have a DNS name, like you have that kind of thing. When you use private lines…yeah, people think they can decide whatever they want and we have some kind of crazy stuff going there. But like, you know, it’s not the Internet so we can do whatever we want. But the applications don’t have access to the Internet directly, so there is no escape path. You must use HAProxy to connect to the partners.

One last point that I want to mention is why we did not get a normal HTTPS proxy. The issue is that with normal HTTPS proxies is that they will just open a TCP socket between you and the target and you are still responsible for everything that’s in the middle. So, maybe they can redo the TCP connection if that fails, but they will not be able to do very much more. We wanted to do something better than that, so we wanted the proxy to know about the request and to be able to do the TLS negotiation and all that stuff, which is not possible with a normal HTTPS proxy.

Instead we have HAProxy. So, we are actually doing our HTTPS connections to the HAProxy server and it will do the final request to the outside world.

That’s how we started to use it. Basically, HAProxy is terminating the TLS connection and starting a new one. The way that we use HAProxy is that instead of calling a URL called example.com, you actually call the internal proxy. It means that for the application, it’s safe. It’s not using a proxy at all. It is just like calling our proxy with a slightly longer URL than you would expect, but we do it so that we can identify a lot of things in that URL.
Proxy URL Composition
We actually have a web page that will enable application owners to decide which URL they need to use. If we look at that URL more deeply, what do we find?

My application, “myback”, will call a long application, but we can actually split that application in multiple parts. If we look a bit further, we see that the new URL is proxy.inuits.eu/, then the name of the application, then the name of the partner, then a bunch of other stuff.

Then you get the partner. We have dozens of different partners. They have different behaviors and they have different applications as well. So, we define a partner that you want to call using the HAProxy. We only have one HAProxy frontend and in the URL we define a partner that we want to call….the environment, the application, and the partner that you want to call.
Then something that’s called the SLA. What we call the SLA is actually just timeouts because we do a lot of business. Some of them is, like, synchronous business. You expect a reply now; and the other thing is like posting a one gigabyte file to the other direction or putting a file of 5 or 10 or 20 megabytes, and for that you don’t have the same timeouts as previously.
And then you have the rest of the URL because, like, in one application you will have multiple endpoints behind that URL.

So, by looking at that we already know a lot about the request that the application is trying to perform. If I take back my URL that you have seen that was very long, actually, I can read it and I know that the application “myback” in production is calling the URL “/helloworld” of the service “www” to partner “example” in production and that we expect quite a quick answer from that partner.
Actually, the reason why we have timeouts is so that every application that we have will now follow the same rules. We don’t need to define in each application what should be the timeout, what should be…we define that in the HAProxy and basically HAProxy will do the work for us to define what will be the timeout, the same timeout for such services.
I know if you can read one of those URLs, you can actually read all of them. If I show you now another URL, well maybe not now, but if you are used to it you can now know exactly what those URLs mean.

When you migrate to calling directly your partners using HTTPS to the outside world, then you also when you migrate to HAProxy use HTTPS so that you don’t have more unencrypted traffic after you move then before you move. The second thing is that the application will need to change the URL in the applications. It’s not like a flag that you pass to the application. We really need to adapt the applications, but that will provide us a lot of benefits. Also, as you have seen, we have two HTTPS connections, which means that internally we can still allow TLS 1.1, 1.0, but to the outside world we will actually use TLS 1.2. So, the best that HAProxy can do to the partners.
Access Control
Let’s talk a bit about access control, because now that you have a central HAProxy you want to avoid mistakes, to get a bit of…to play with HAProxy ACLs, right? We have a very basic access control right now, which is just IP based, which you can not really call security, but it prevents a lot of mistakes at least. So, that’s the first access control that we have in place: just a bunch of clients with the name and an environment.

The HAProxy that we use, basically we have two clusters: one for production and one for non-production; and we have a bunch of ACLs that will tell us, “Okay. That application can come from that IP range.” Then, we actually, for each one of the applications, we actually have another ACL that will look for the path of the URL.

We use the path_beg directive in HAProxy to say, “Okay. If the path is beginning with that URL like “myback/prod/example/prod/www/high”, then I will use the use_backend directive to say, “Okay. For that specific…if those conditions are matched…so in this case it will be that the application matches my client…that the IP matches my client and that the path is beginning with what my client should announce, then you will use that backend.” It means that for one frontend we use multiple backends depending on each one of the requests that we have. We don’t have a dozen different frontends. We route based on the URI that we get and only if the client is recognized, the client’s IP is recognized.

You might notice, also, that the backend is not per client. It means that if we have a partner called by multiple clients, they will all use the same backend. They will all use the same pools. For now, so that we have identified the clients based on its IP and the URL that it is calling and HAProxy would like to validate that it is a client that is expected to come from that IP. Basically, we have everything in the URL, right? We also have some SLA that tells us, okay we want, or not, to send a request with a large or long timeout.

From now on, we have shown quite some features of HAProxy, like path_beg and use_backend. Just know that the backend is just an external partner and not something that we own internally. Right.
SLAs
SLAs, well, what we called SLAs.

Basically we set SLAs for each one of the backends and basically it can vary from a few seconds to several minutes and it’s not really practical to do it for each application. Well, you can do it if you have a unified stack or just two or three technologies, but you actually have a lot of technologies over time. So, just taking those SLAs at the HAProxy level and adding them just on the URI helps us a lot, just knowing what will be the timeout that the application will use or will not use.

That’s what we have. We have some SLAs that are for when you post big files that will be maybe like five minutes, and also some medium SLAs for normal transactions that will go to 30 seconds; and the lowest SLAs we have is like 10 seconds; so we are not in a hurry, right? Some very specific applications can get some specific SLAs as well. Sometimes, we timeout after three seconds and sometimes a bit more. We have really a long range of SLAs that are possible for the application owners at the HAProxy level.

Basically, that’s what it looks, one SLA.
Basically, we set the different timers. One thing that’s common is that we don’t want to queue requests at the HAProxy level, which means that if a partner is responding slowly and we fill the number of connections that we have set for that partner, then HAProxy will return a frontend HTTP request saying, “Hey, you know. I can’t do it now.”
Masquerading Requests
The problem with what we have seen now is that basically the request that we make to the HAProxy is not the request that we want to send to the outside world, right? I mean if I contact a partner and that’s my URL, it’s full of all those things that we have put at the beginning, that’s not going to make it correctly. So basically, because HAProxy is not a forward proxy, it will not actually…it will, by default, just pass my request like it is now, like with all that big path that we want. So, we will change the request and will make it look like it’s actually a request meant for the backend that we want to address.

What do you need to change from that request to make it like a real request? The first thing is that you will want to change the host name, the host name header, right? Because now the header will be like proxy.inuits.eu. The Host header is not correct because in this case you would expect it to be like example.com.

SNI. So, SNI is when you initiate a TLS connection, you can specify which certificate you want to retrieve by, I think, a specific SNI attribute to the connection so that you know, “Hey, this is the server name that I expect to see.” Basically, you need to tell HAProxy which SNI you want to use. The last thing is that we will need to do something with that “/myback/prod” and remove it to only keep the part that is actually interesting us, which is “/helloworld”.
This is how we actually alter the query. HAProxy is full of a lot of different functions that you can use to alter your requests. In this case, we will first set the header Host to www.example.com for that specific backend. It means that it will remove the existing Host header and it will just set it to example.com. Then, we set the SNI in this other part. Basically, we use the str function, which takes a string as input and then you can just specify the SNI that you want to use. By doing those two things it is just like the request was sent for example.com from the beginning.

Then, we define the example.com using its DNS name because as we call the outside world we don’t want to call the IP addresses all the time. We don’t want to put the monitoring to say, “Oh, did the IP change?” So, we are just using DNS resolution. You can see resolvers mydns and in our case we actually use a lot of IPv4. In this case we also say, “Okay, we prefer IPv4 if you support both of them.”
Then there is that reqrep line. What it will do is that the reqrep will replace the request line in HTTP. Basically, what the request line will contain is the method that you are using like POST, GET, PUT, DELETE, OPTIONS, and then the URI and then the HTTP version. In our case, we are interested to keep the method, of course. We want to keep the GET, POST, etc. Then, we want to just remove the client and the environment if we can, and then the “example/prod/www”, all of which are the other attributes that we set in the URI from the application.

Basically, we take the first and the last thing on that request line and that makes the new query, right? So, that makes the new first line of the query. We are also using, for the SSL in this case, we are also using the certificate file provided by our distribution to validate the backends to the partner’s certificate. That’s for the backend path.

So, now we have used a bunch of more HAProxy features that you don’t always use when you want to do just load balancing. So reqrep will enable you to alter the request and change the URI on the fly; set-header will just set a header if it’s not there yet. The str function, very useful when you want to work with strings. So if you, the first time it’s write…you just put the string itself, it’s not working. So, you find the str function, which is very useful. And then sni enables you to, when you do the SSL connection, put the SNI information.
A World About DNS
So DNS. Remember when I mentioned about private lines? That kind of thing? So, that’s my backend and basically I have resolvers mydns inside the backend.
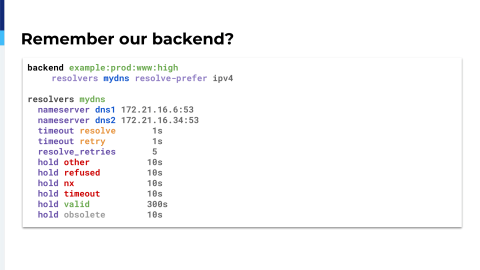
Then we define a bunch of different options and timeouts to the backend…to the DNS information. There is something that you should know about HAProxy if you start using DNS. At least in 1.8, when HAProxy will start and validate the configuration, it will not use that section. What it will do, it will try to resolve the host using the operating system DNS. And then, only five minutes after, well when that timeout is set, then it will actually try to resolve the actual backend DNS name, which means that you can have an HAProxy that will reload correctly because it is using the operating system DNS and then five minutes later, the DNS server that you have in the configuration there will make all the request fail because they don’t have to correct DNS entries.

So, I agree that ideally you should have the same in the operating system and the HAProxy, but sometimes we have that. So that’s the DNS section. Also, when the DNS resolution is failing the error message in the log is not, like, quite crystal clear. So, sometimes, it took us some time to figure out what was going on.

In the real world, we have some strange things. Like sometimes the partners they just don’t publish the DNS entries. When would they publish a DNS entry? “Oh, you know. Not yet.” So, we had, sometimes, a partner that would say, “Yeah, we will put that new service up in like 10 days and then you will need to switch to that URL.”
And then you ask, “Okay, but we cannot resolve that yet.”
And they say, “Yeah, when you can resolve it, then the service will be up.”
That’s not very helpful for us because we like to prepare stuff in advance. We also have some partners that, don’t ask me why, they decide that the production and the non-production will have the same host name, but different IP addresses. So this is very inconvenient for you. So what you used to do is like changing the hosts file on the end, but that’s really a mess. We don’t know why that happens, but basically it’s a use case that we used to support for like ten years, so now we need to say, “Okay. We will support it. Yeah.”

So, that’s very easy actually, the “no DNS” scenario, because all you need to do is just put the IP address as the backend.
It means that HAProxy, because we have the sni and the http-request directive in the file, it will be completely transparent for the backend if we did use DNS or not. In those cases, that makes our life very, very easy and we don’t need to change the /etc/hosts file on all the different hosts because HAProxy is clever enough to just do all the work for us. And if we have a different backend with a different IP but same host name, there is no issue for HAProxy with that because they are completely independent. And that’s really, really great.
Advanced Topics
So, some advanced topics that we have. Now that we have all of that thing in place, what can we do more? What can HAProxy bring us more than what we had in the past?

We can do canary releases. Like, we have a partner that will tell us, “Yeah, we want to try a new service or we have something new that we would like to try.” And, basically, we can just change the path of the request when HAProxy is treating them, so if you put that first, then if the condition is like rand(100) is less than 10, then 10% of the requests will go to the new service.
We do it just by changing the path of the request and because we are able to do ACLs and we check for that first, then it will actually enable us to switch to the new service in 10% of the cases, which is really convenient and which we can do just in the top of the configuration file.

You can actually do some…we can also do that for other advanced topics. Like, in this case, we have a partner that informed us, “Hey, by the way, on Sunday at 10 a.m., we will work. So please, at that moment exactly, change your HAProxy URL, your URL to point to the new URL because we will, like, switch data centers for this service.”
And we were like, “Ugh. Do we really want to work at 10 a.m. on Sunday just to make sure that the partner will be happy that we called the new URL?” So, instead of that, we actually use the date function in HAProxy, which means that just at Sunday at 10 a.m. at that moment exactly, we knew that we would use the new service at the partner; and no one needed to, like, wake up on Sunday or work on Sunday. It was just all done magically via HAProxy.
This is actually really, really great because you can actually plan the changes in advance. You can plan the rollout, you can plan…a bunch of this stuff is that date function that before was painful because you had no other solution that, like, “Okay. We will restart all the different applications on Sunday at 10 a.m. just to change the URL.” Now, we do all the work at the HAProxy level and it is clever enough just to do it just when we want it to do it.

We also have some partners to which we need to work with client-side certificates, which I don’t know who would use that internally, but I mean we can do it nicely with HAProxy. There is a crt directive that enables us to talk to partners using a client SSL certificate.
You also have a partner who is like, “I want to make sure that you use TLS 1.2.” And how do you do that? Well, you have a nice force-tlsv12 in the configuration. I’ve seen that in the latest release, you also have force-tlsv13. Basically, it makes sure that HAProxy will only talk TLS 1.2 to the partners. So, you can tell them, “Okay. No, if you roll back to TLS 1.0 and disable TLS 1.2, we won’t talk to you any more, but you asked for it, you have it, right?”
Setup and Maintenance
Let’s take a look now at the setup and the maintenance of all that setup that we have with HAProxy.

So basically, we have quite a big file so, we have like 4000, 5000 lines of configuration. That’s the point when we are happy not to have a big scale or a lot of, like, hundreds of partners, because, well, I think the file is quite nice.
What’s important is that for the application owners, for the people that need to connect to the proxy, it’s very easy for them. Because, all they need to tell us is who will be the client, who will be the partners, and which kind of SLA do they want us to configure. Basically, that’s pretty simple YAML files with a couple of lines for each entry and then we turn that into the gigantic HAProxy configuration using Ansible.
It means that we have an abstraction between that big HAProxy configuration that will actually enable us to remove a lot of mistakes that you can do or that you can also make a lot of strange things. So basically, we know in advance which kind of input we can get from the application maintainers and we can basically abstract that nicely. It also means that our developers, they don’t need to know everything about HAProxy. They don’t need to know about the configuration. They don’t need to know anything. For them, it is just like providing a URL and a bunch of other inputs and then that will just work out of the box.

Monitoring. Basically, we make HAProxy log to a file using syslogd type of things and we are reading that file. It means that we are not affected when we reload by…and those kinds of things. It’s really easy for us to continue to read the file, whatever happens. And in that file, we can see a lot of different things.
So, when we look at one line of the file, you will see the client, your environments, also the partner, the environment, the application. What’s interesting is that when we change the URI, like when we want to send 10%…the example at 10 a.m. on a Sunday…actually, the URI that you will find in the logs will be the original URL. So, the URL that the application wanted to call, but the backend that you will see in the log is, obviously, the backend that was actually used. You can see which request was done on which backend, even when you have those rules like the Sunday at 10 a.m. rule or the 10% to another service rule. Basically, the log line doesn’t lie and it shows the correct input.
Then you see the status and the duration, which enables us to build a dashboard with the rate meter, which means we see the requests, we see the errors, and we see the duration. So, we can see when something is going wrong. What we are using is Prometheus. We are big users of Prometheus. Regarding monitoring, we are quite up to date. We use Grafana, the HAProxy exporter. We are still on 1.8, so we don’t have the native metrics yet, and we use mtail.

Just a word about mtail. Basically, mtail is…it enables us to do via all logs that we get to design kinds of queries where we can see exactly for that partner, for that environment, for that target, what is the status? I have put on my GitHub page an example of an mtail program; mtail is a small program in Go made by Google that just parses log files and makes Prometheus metrics.
This is very tied to our usage and it’s very flexible. You can do a lot with that and at the end we have a full visibility on what’s going on, which partner is failing, when that partner is failing, that kind of thing. Then we can do very precise alerting to know which application is failing now to talk to its partner. Sometimes, it will be because of the application, sometimes because of the partner, and we have, actually, a really nice view on that thanks to this.
Conclusion

So, conclusion. The configuration of egress is now a very simple concept for the application maintainers. They only know what they need to know. We have put very nice monitoring on top of it so that we have, actually, some Grafana dashboard where you can just select, “I want to see now the traffic for that application in that environment to that partner.” So we can quickly dive into what is going on in the infrastructure and we are actually using a lot of advanced HAProxy features…what I mean is features that you would normally not use with HAProxy, but that are really nice for some use cases like our use case.

So now we have…we completely understand how our applications will talk to the outside world. We understand the timeouts; We understand how they will see that TCP connection; We have detailed metrics, so that’s very nice of HAProxy to provide us like: in that connection, how much time did we spend connecting? How much time did we spend sending the data? So, all of that we now have fully detailed reports for Prometheus metrics.
We can now be quickly alerted when something is not responding, when something is down. It means that when we need to change, when we need to analyze a failure at the partner, we know it directly. So, we can already see ourselves the business impact. Maybe for the partner, just an application will not be able to talk to a service at the partner. We see it directly now. We see it at the HAProxy level and we don’t need to look at different places. So, HAProxy will just centralize all those things.
It also means that for even a 20-years old application will also talk TLS 1.2 now, which means that we are not blocking partners to make their TLS stack evolve. We are just very happy to say, “Okay, yeah, we will support TLS 1.2. We will support SNI. Just do whatever you want. We will not block you.”
It also means that the timeouts are unified across all the stacks and the TCP retries, as well, are just unified. Also, the two-way SSL is now delegated to HAProxy. It means that when we need to deploy the client certificate, we do it just on the HAProxy cluster and not on four different applications in five different VLANs, that kind of thing. It’s not a pain any more because we delegate that to HAProxy itself. And all that’s nice, so we don’t need to work on Sunday morning. We can kind of take it easy, that kind of thing. It’s very nice and very helpful with HAProxy. So, we really like it.
It also means that when we want to change something, we can usually do it. When we want to change the URL, when you want to change something, we don’t need to restart the applications any more. So, you can imagine that when you have a 20-years old application that you need to restart it multiple times to change or tune the URL; and then usually you want to avoid that. So, basically, it’s very helpful for us to just…being able for the application to say, “Yeah, if we need to change some egress configuration, we can just do it at the HAProxy level and then, maybe, if that’s needed, we can change the configuration properly at the application side.” But just being able to do it at the HAProxy level only, prevents us from having to restart those very old applications. So, thank you!
Modernize and Secure Your Traffic with HAProxy
Julien Pivotto's presentation perfectly illustrates how HAProxy's flexibility solves complex, real-world challenges far beyond typical load balancing. The challenges faced by Inuits—from modernizing legacy applications to managing complex partner integrations—are common across the enterprise. Their solution is a masterclass in creative, high-impact infrastructure design.
The most relevant solutions for achieving these results are:
API Gateway: At its core, Inuits built a powerful egress API Gateway. They used HAProxy to centralize control, intelligently rewrite and route traffic based on the URL, and translate protocols (like older TLS to TLS 1.2) without touching application code. This decouples applications from the complexities of external partner integrations.
Security: A key driver was security modernization. HAProxy's ability to enforce modern TLS versions and centrally manage client certificates (
.crt) for two-way SSL instantly enhances the security of older systems. This removes critical roadblocks and simplifies compliance.HAProxy Enterprise: This entire strategy is powered by the advanced and programmable features found in HAProxy Enterprise. The ability to automate point-in-time rollouts with the
date()function to avoid weekend work, perform canary releases withrand(), and gain deep observability through detailed logs are transformative features. They reduce operational risk, increase agility, and provide the robust control needed for mission-critical systems.
Whether you're managing ingress or egress traffic, HAProxy provides the definitive tools for security, observability, and intelligent traffic control.