
How do you efficiently manage and rapidly deploy thousands of test environments daily in a sprawling, multi-data center architecture with tens of thousands of containers? This was the significant challenge faced by PayPal, a global leader in online payments. Alternative load balancing solutions struggled to meet the team's demands for dynamic configuration updates, scalable service discovery, and complex traffic routing for A/B testing and canary deployments.
In this session, Srivignessh Pacham, Sr Software Engineer, discusses how PayPal Genesis leverages HAProxy Fusion to overcome these obstacles. He delves into the limitations of open-source solutions for their specific use case, highlighting the relevant core features HAProxy Fusion provides — such as the Map API for dynamic frontend configuration and automated service discovery for Kubernetes environments.
We'll dive into PayPal's architectural design and cluster overview for HAProxy Fusion, including their specific SLB requirements. Plus, Srivignessh demonstrates HAProxy Fusion's scalability and stability while handling frequent configuration updates and discovering a massive number of service objects. If you're facing challenges with enterprise-scale, dynamic application deployment, this talk is for you.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.



Hello, everyone, I'm Srivignessh. I'll jump right to the slides here.

The PayPal team also shared their insights on a different subject in their second talk, "Building bridges across clouds: the PayPal approach to unified business communication."
At PayPal, we have a QA environment and a production environment. The use case we have been testing HAProxy for focuses on our test environments.
Let's go over the agenda. We'll first cover HAProxy Fusion features, which have been generally presented by everybody here. Next, what are the problems we face in our test environments? Why do we need to use HAProxy Enterprise and HAProxy Fusion over the open source version of HAProxy? We'll also discuss our design and give a cluster overview. Finally, let's go over the LNP results.

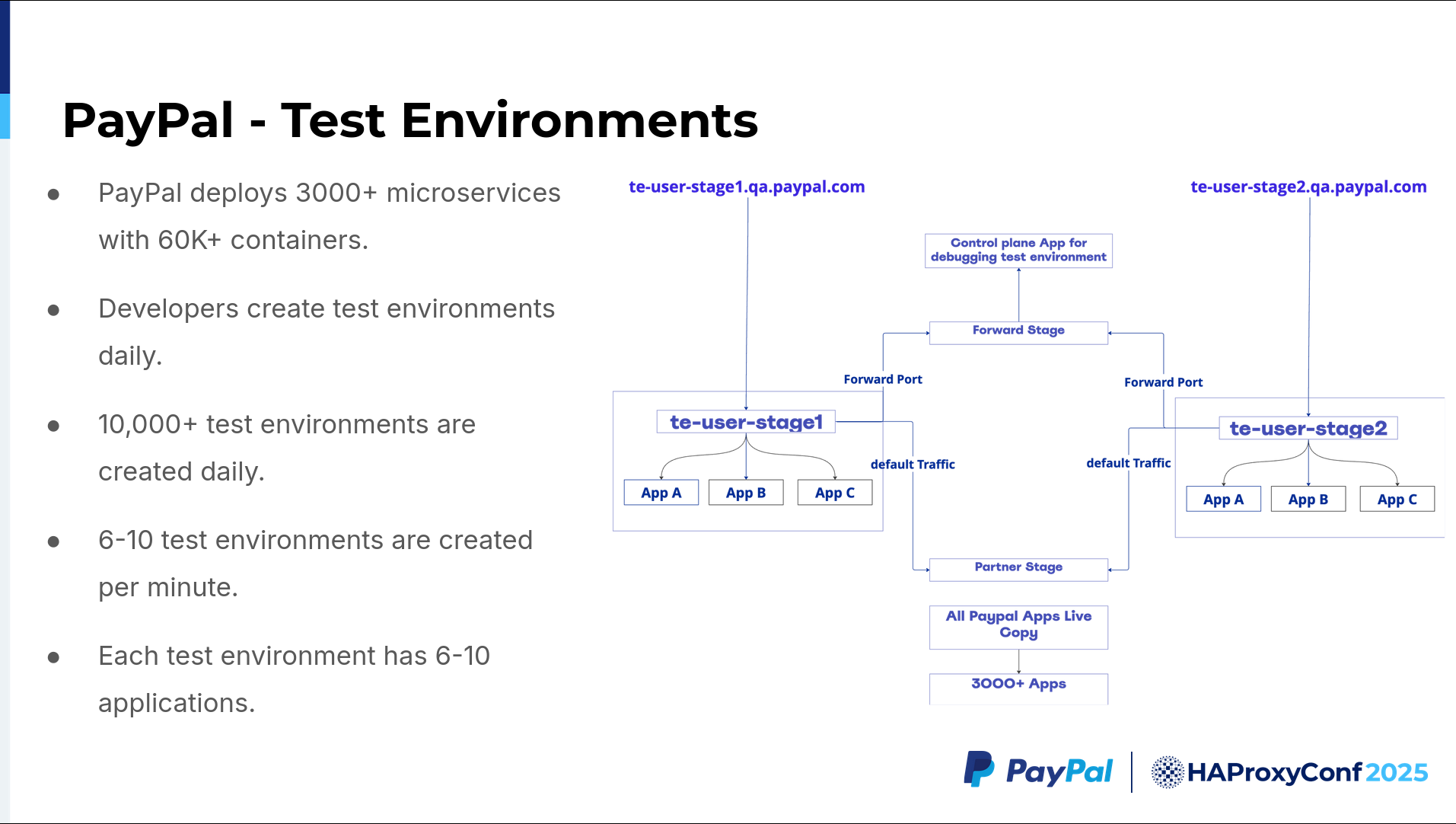
Before moving on to the test environments, let's summarize the scale at which PayPal deployments happen today. We have five or six data centers spread across Phoenix and the Salt Lake City (SLC) areas. Each data center has roughly 60,000 containers up and running; some are on-prem, and some are in the cloud. Plus, we have nearly 30,000 employees that create nearly 10,000 test environments per day.
We have 3,000+ apps. Each team owns a few apps (such as App A, B, C, or otherwise) and wants to test their custom versions alongside the live versions of the existing apps. In general, it's easy when you have only one app you need to test against a couple of other apps, but if you have a group of apps and want to test them against 3,000+ other apps, things get tricky.
Here is an example where we have two users, such as te-user-stage1 and te-user-stage2. Two users have a few apps like App A, App B, and App C, while another user has a couple of similarly-named apps, or any set of three apps out of those 3,000 total apps. Each user wants to independently test their custom application groupings against a live version. With just one app, it's easy to use DNS to find those other apps before routing it. But when we have a group of apps, we have to ensure that the traffic comes back to the corresponding group of existing applications within a given production group. If that app doesn't exist in the group, then traffic must follow the default traffic path.
There is a partner stage where we deploy duplicates of every live, running instance. If we have 3,000 apps in production, we also have at least one copy of each app. For scalability, we usually have at least four copies of these 3,000 apps in different environments, across multiple availability zones. We also have a forward stage for users who want to run top, or ps, or a couple of basic commands inside their application containers. We've built a simple control plane app primarily for that.
Anybody who wants to run basic commands can call a couple of APIs to run those commands for them. It's more like a backdoor which runs only a set of predefined commands, so users don't have to directly authenticate, jump through RBAC hoops, and wait. Users can simply run these commands from their application or the CLI, which makes testing very easy. Accordingly, this is the use case we are trying to solve here.
We've picked HAProxy Fusion over open-source HAProxy because we have 10,000 test environments created daily, or roughly 6 to 10 test environments per minute. The challenge is that if you use HAProxy Community and have nearly 60,000 containers, configuration updates will take 30 seconds to be reloaded. Every time I update a single config and then reload HAProxy, it takes 7 to 10 seconds to spin up and nearly 30 seconds overall to stabilize across all the servers.
We can't wait 30 seconds for every config update when we create 6 to 10 test environments per day. The test environment includes a virtual service alongside applications A, B, and C (for example). The entire package has to be deployed very quickly. With open source, we are not able to make ends meet.
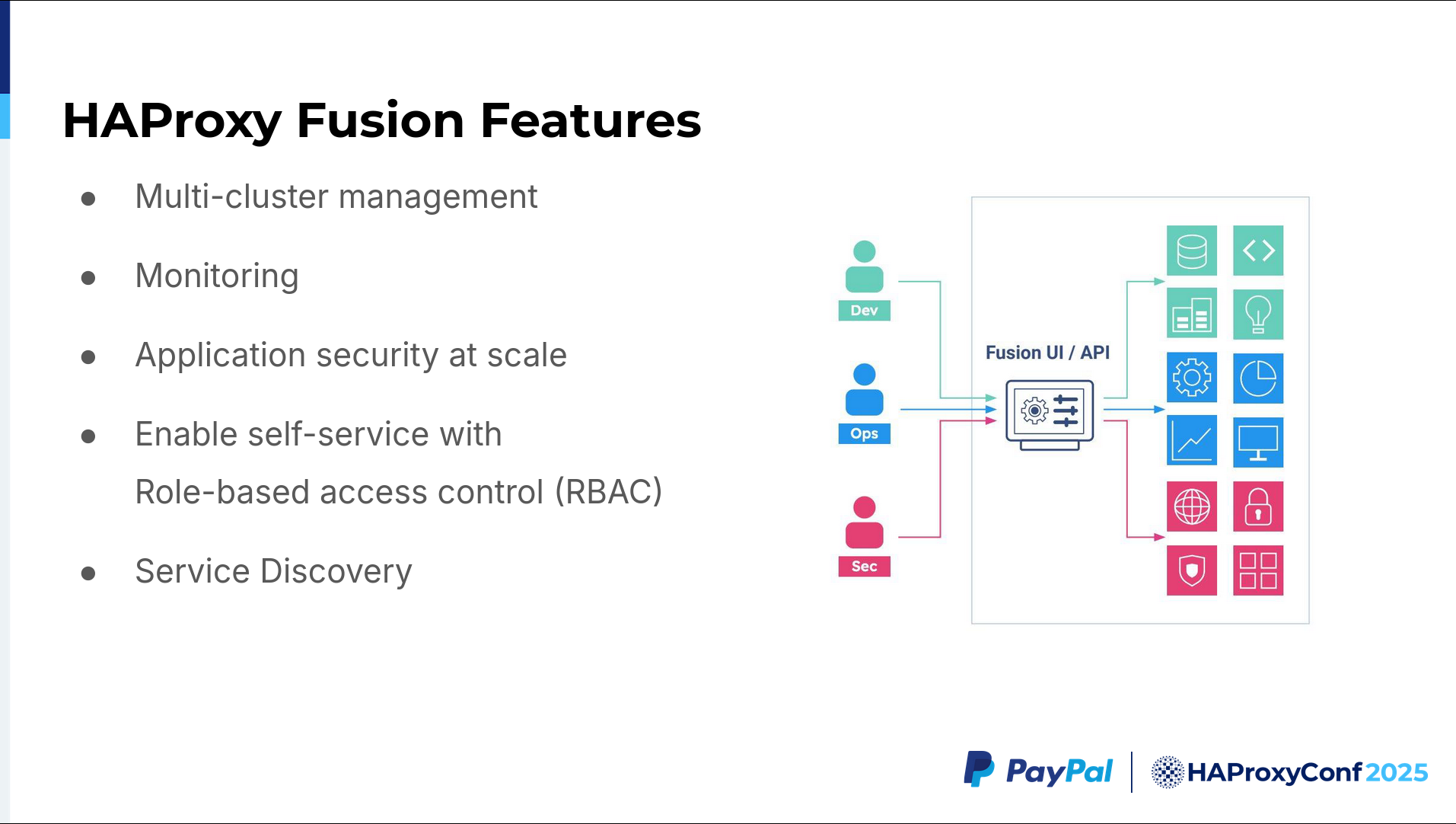
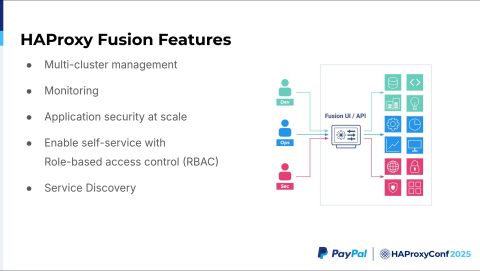
HAProxy Fusion provides two functionalities that we regularly use. One is the Map API, which helps us dynamically configure the frontends. For the backends, we have automated service discovery, which discovers our Kubernetes Service objects dynamically and then helps us discover our pods quickly.
The service discovery feature supports up to roughly 12,000 service objects per Kubernetes cluster. We have maybe four clusters. We are, therefore, able to discover up to 48,000 service objects per HAProxy Fusion deployment. Plus, each HAProxy Fusion cluster can manage multiple HAProxy Enterprise clusters. We are running four HAProxy Enterprise clusters managed by one HAProxy Fusion deployment.
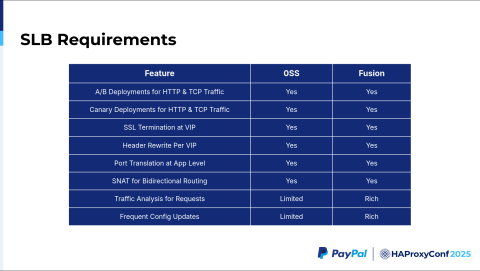
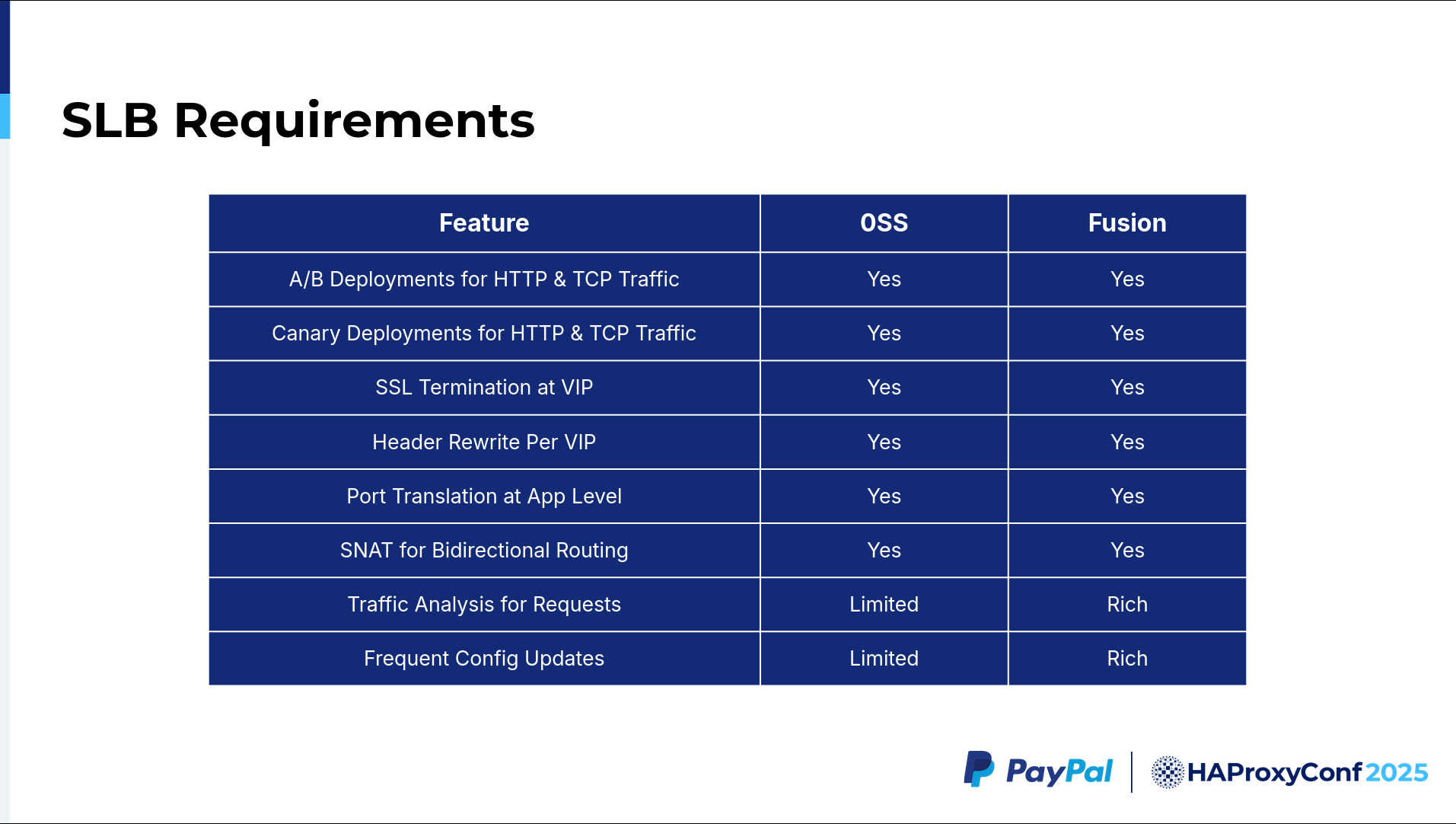
The SLB requirements are our requirements for a particular test environment, such as needing A/B deployments for HTTP and TCP traffic. We have header-based routing, path-based routing, and port-based routing—which is generally a user requirement—plus our required canary deployment. We want a given deployment to capture just 1% or 2% of the initial traffic. That is most likely not needed for QA, but for production, we definitely need it.
That said, we want HAProxy Fusion, which should definitely support our future production use cases as well. We also have SSL termination at the VIP, because any time a user makes a request, we want to terminate at HAProxy and do basic TCP without SSL to reach the servers. Everything is happening within the availability zone. A header rewrite for each VIP is also required. For example, any request coming to hello.qa.paypal.com should be redirected to https://www.qa.paypal.com.
We need the header to be rewritten and then routed to a different path. We also need a feature like SNet (Scalable NETwork) for bi-directional routing. Currently, if you put a reverse proxy on top of your service, you will get the reverse proxy's node IP as the source IP address for your destination applications.
That challenge is very relevant if you use a Kubernetes Service object, which generally provides the Service IP, after which the application itself will usually see the node from which the application responded. You will not see the actual Service IP. That was a challenge when we were trying to compare Kubernetes-based routing versus the bi-directional routing we needed.
Comparing the features of HAProxy Community with HAProxy Enterprise and HAProxy Fusion, the Request Explorer feature is vital in terms of navigating where the errors are—at either the HTTP, HTTPS, or TCP layer. It was very useful. That was one of our key requirements aside from accommodating our frequent config updates. We need to support approximately 10,000 config updates per testing environment. Each test environment has three config updates, including one to create the virtual service and one to then deploy the applications.
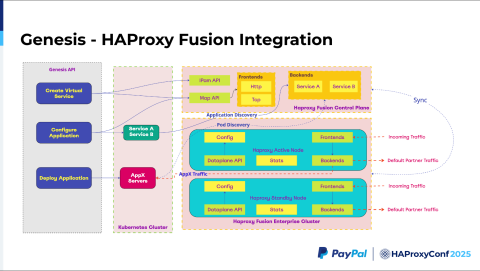
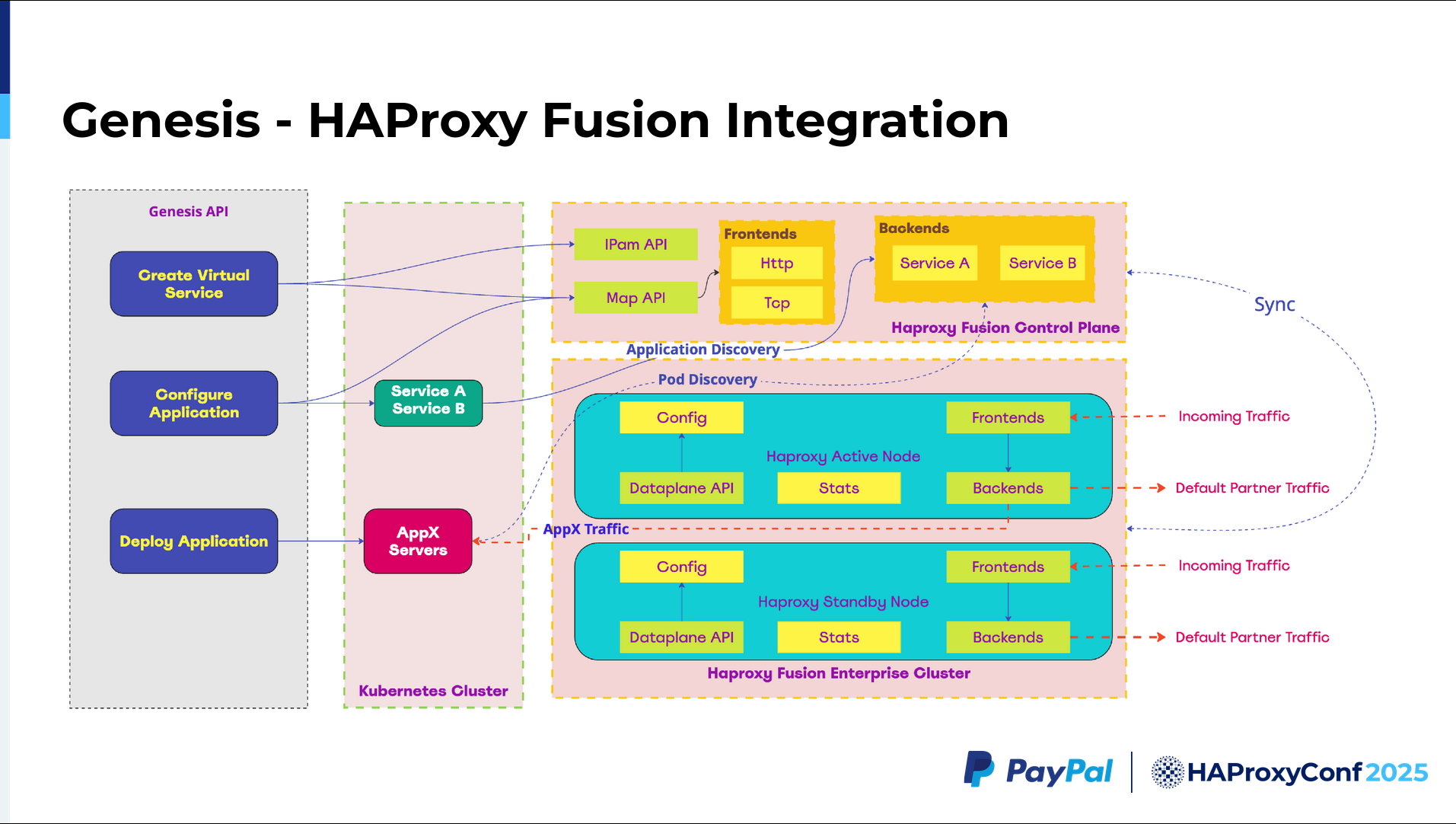
I work with the Genesis team at PayPal. How do the Genesis APIs talk to the HAProxy Fusion API? Before creating an environment like te.qa.paypal.com or userstage.qa.paypal.com, you'd first create a virtual service. The virtual service is a concept widely used by the Ingress gateway, Avi, and NetScaler. Consequently, that is the terminology I'm going with here.
When we create a virtual service we make a call to the IPAM API and reserve the VIP. Once we reserve the VIP, we call the Map API, and then update the default configuration.
As you've seen previously, we have the forward traffic and the default traffic. We need to configure static configurations that are pre-initialized for both. We call the Map API and then set all of those things. Next, we need to configure the application. Say we have applications A, B, C, or D. We can configure all applications at once or using individual calls. We also need to configure both the frontend and backend in HAProxy.
The frontend configuration will most likely make a Map API call, which will help us create our "A" pool and "B" pool, enabling A/B testing. We then create "service A" and "service B" which basically serve as headless Kubernetes Service objects. Next, we deploy the application.
Here's where HAProxy Fusion shines. The best part is that during deployment, you don't have to touch the HAProxy Enterprise cluster at all. HAProxy has a controller running internally, which helps you automatically discover all Services added to the Kubernetes cluster backend by looking into its Service objects. As soon as the Service objects register, Kubernetes Service objects identify the parts matching the label. HAProxy Fusion controllers, in parallel, discover those matching Services and automatically add them to the backends.

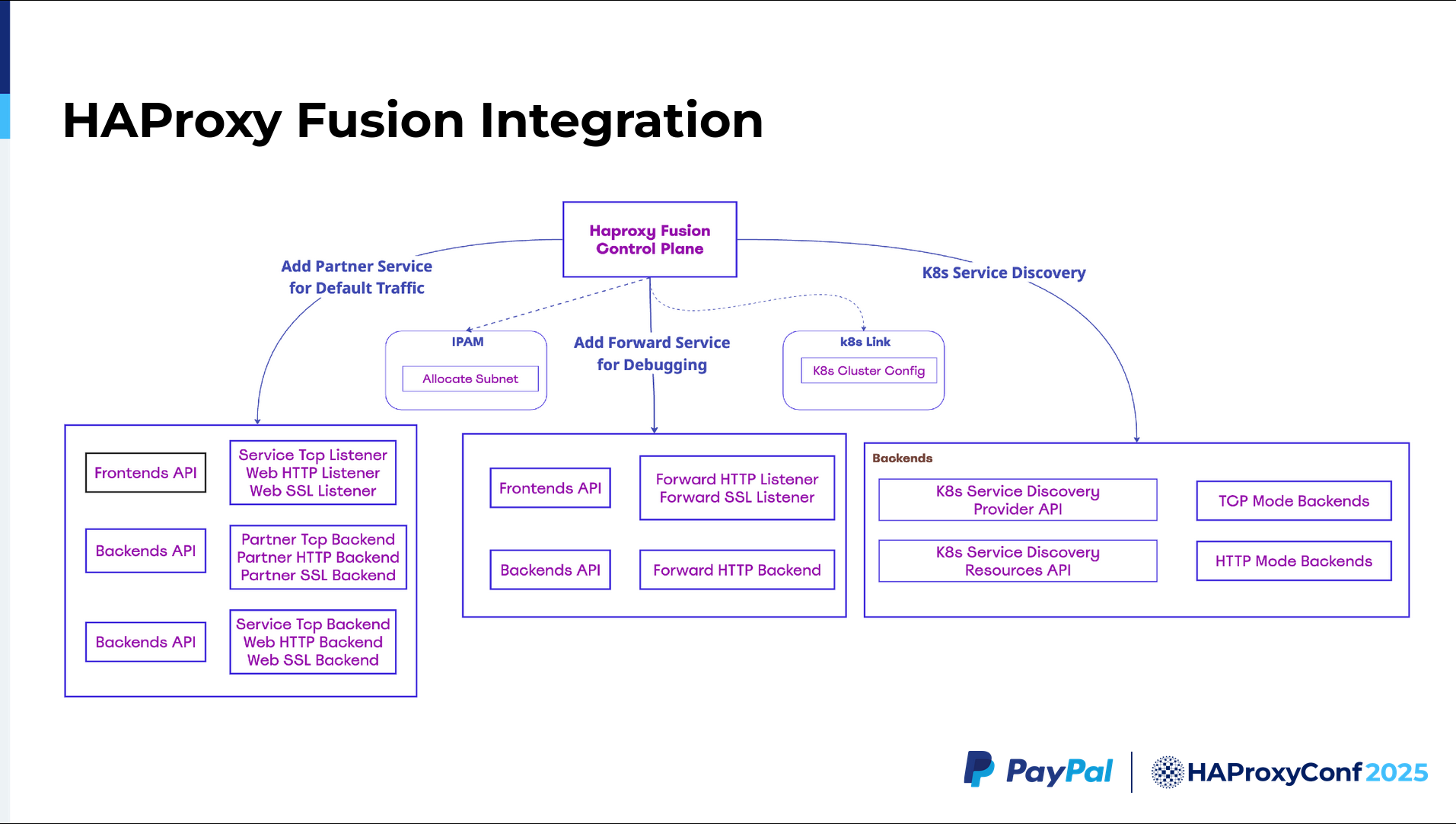
This is how our HAProxy Fusion integration looks in terms of setup, before even configuring, for example, when creating a virtual service. We need certain static assets to be created. The setup has both the partner service and the default traffic. This partner service for default traffic exists since we need to create listeners for every HTTP, HTTPS, and TCP application.
Next, you create a default backend for all of those apps, including the partner service, to successfully pass along our default traffic. The TCP backend, web HTTP backend, or web SSL backend (shown in the bottom-most portion of the diagram) coincide with listeners that will be dynamically modified by the Map API. This ensures that we can capture all relevant traffic.
We also have the frontends and backends we created for the forward traffic. Then for service discovery, we have to configure the Kubernetes Service Discovery Provider API provided by HAProxy Fusion. With that, we can configure the TCP and HTTP backends separately. The TCP backend, TCP ports, and HTTP ports are discovered separately because each has separate health checks and such.
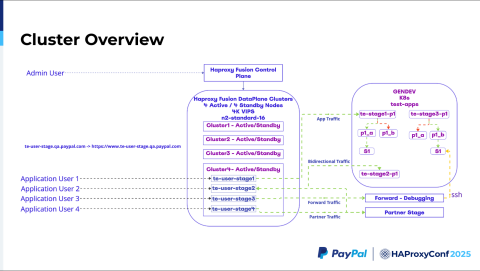
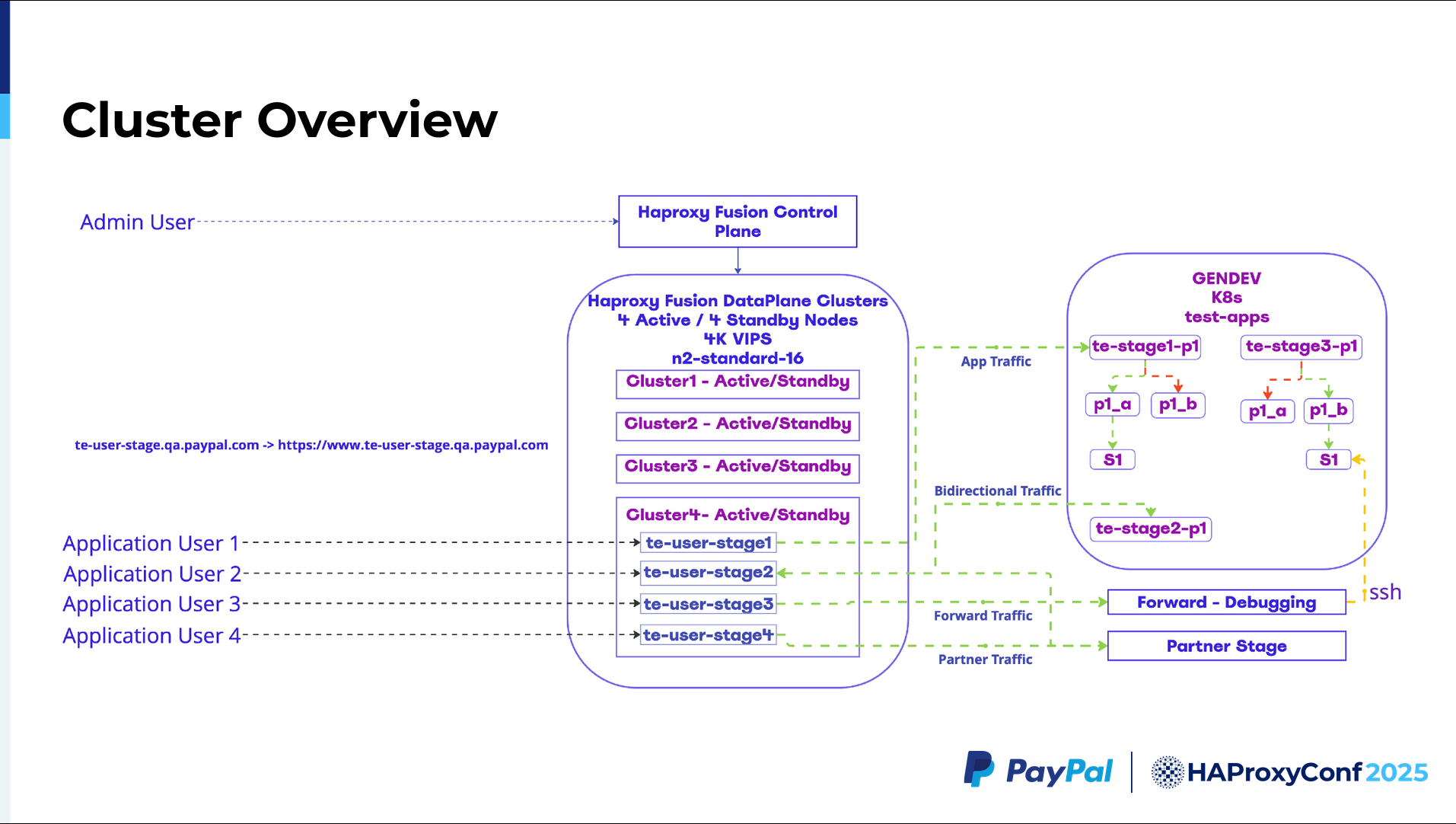
So, this is the cluster overview. Each cluster is made of two nodes: one active, and another in standby. And we have four HAProxy Enterprise clusters managed by the HAProxy Fusion Control Plane. It's a single control plane that lets you monitor these four HAProxy Enterprise clusters.
Whenever a user makes a call, our Genesis API automatically chooses which of those Haproxy Enterprise clusters that request will land on. In this example, we are picking cluster four. This cluster contains four applications with four virtual services, which point to Kubernetes clusters containing different applications in different stages. Both Pool A and Pool B serve traffic here.
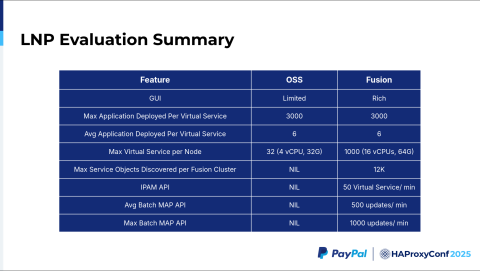
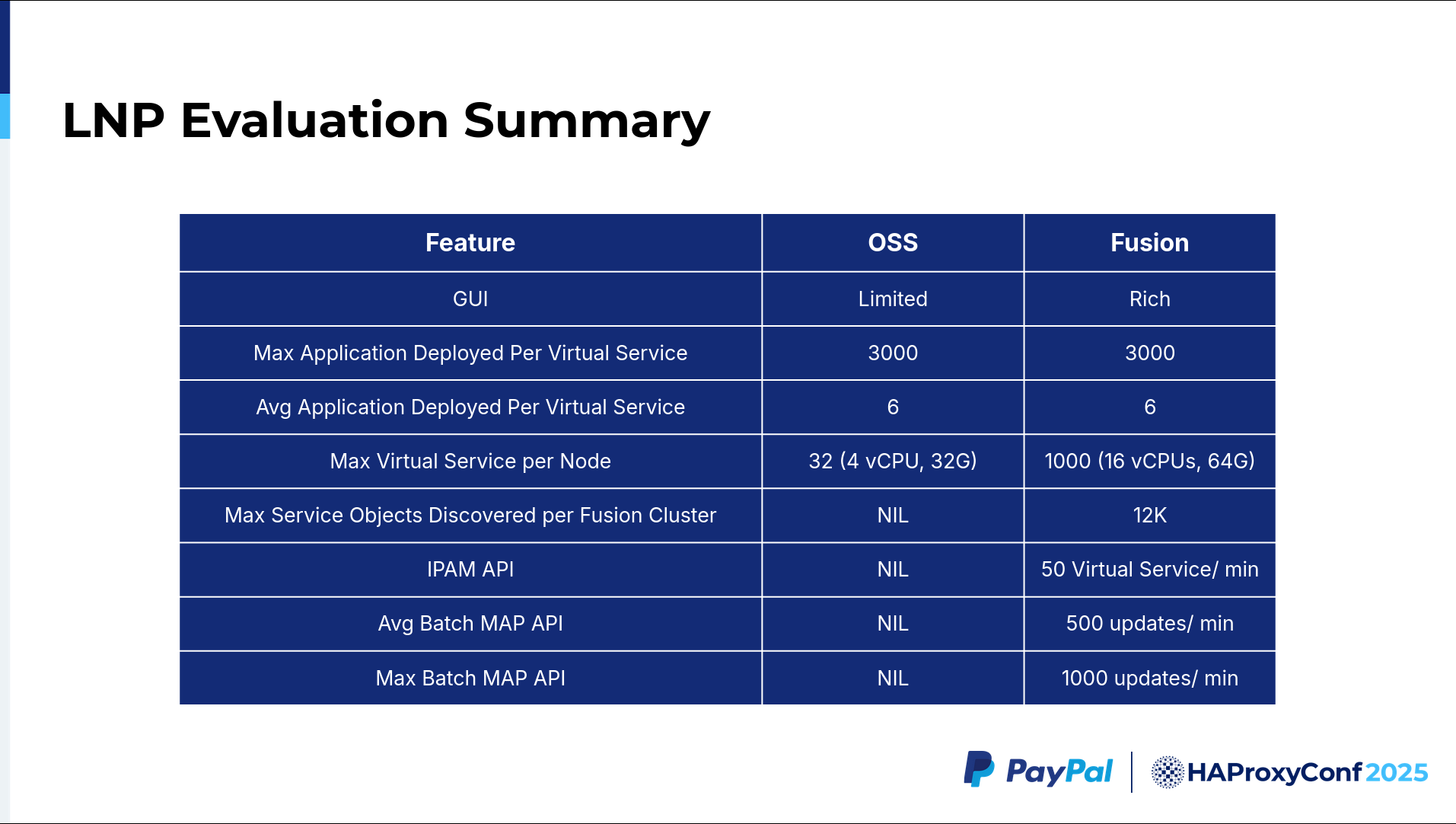
Let's go to the evaluation summary. When we compare HAProxy Community versus HAProxy Fusion, the UI is where HAProxy Fusion shines, from Request Explorer, to service discovery, to the Map API UI. The HAProxy Technologies team, including Jakub, Dario, and others, have helped us greatly in expanding the Map API to include a UI on top in HAProxy Fusion. This addition helps us update our maps both individually and in batches. We now have three to four varieties of Map APIs to handle these changes automatically.
All of these configurations are pushed in less than 10 to 15 seconds. You can configure those in your HAProxy Fusion config, which was very useful to us. Additionally, the maximum number of deployable applications per virtual service, for our use case, was 3,000. This was very much supported in the backends.
We deploy six applications on average, which was helpful when setting up an eight-node cluster. The max number of Service objects discovered per HAProxy Fusion cluster is about 12,000, and these are dynamically discovered. Aside from that, you have to make an API call to register the server. In the open-source version, there is a dynamic HAProxy Runtime API where you can register these servers, yet we found that was not helpful when dealing with 5,000+ servers.
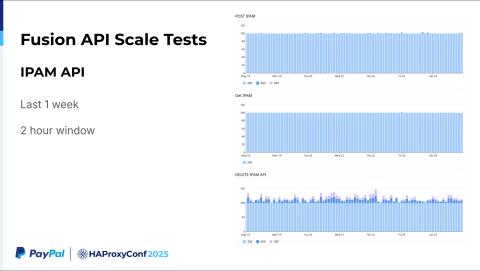
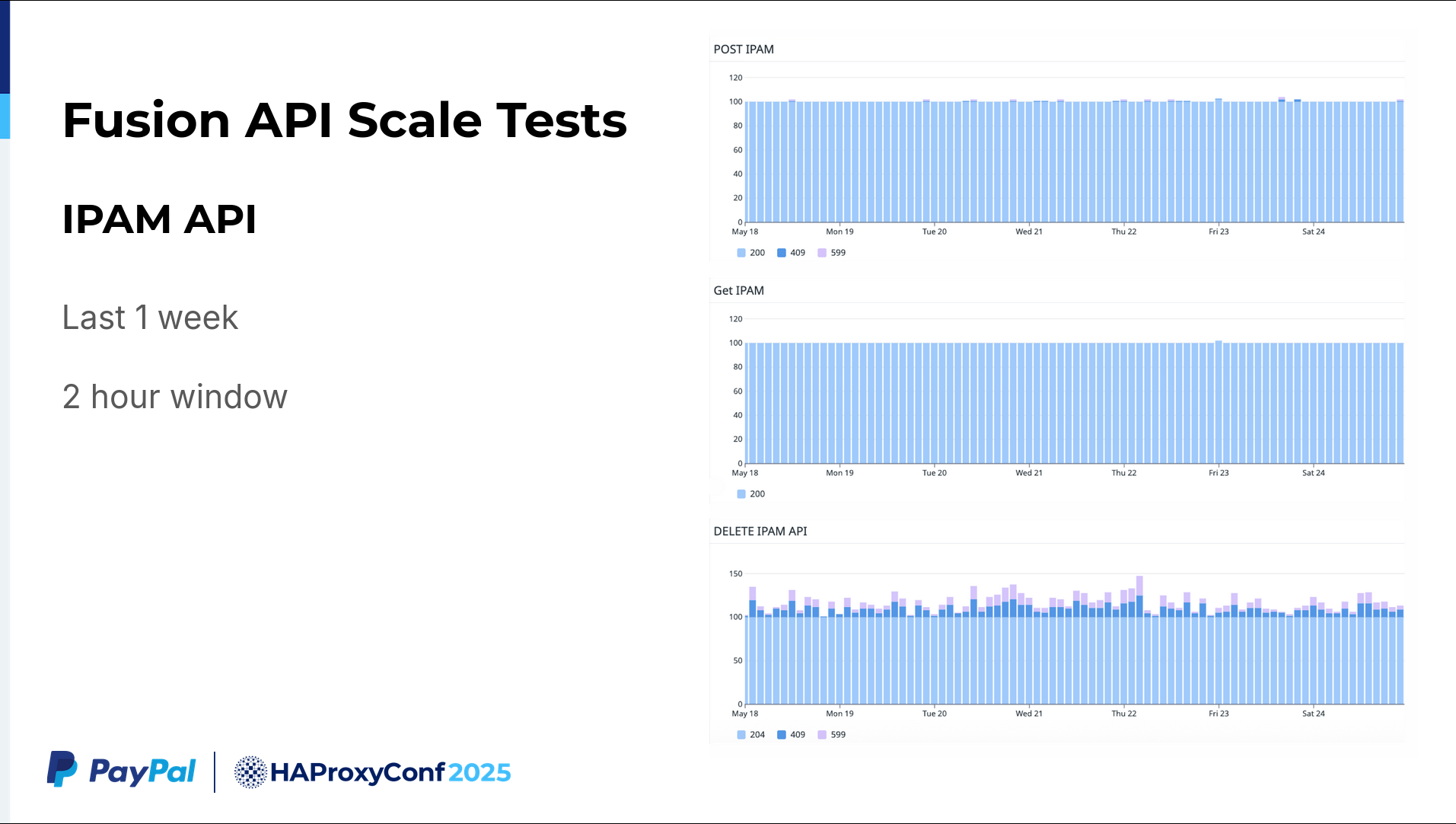
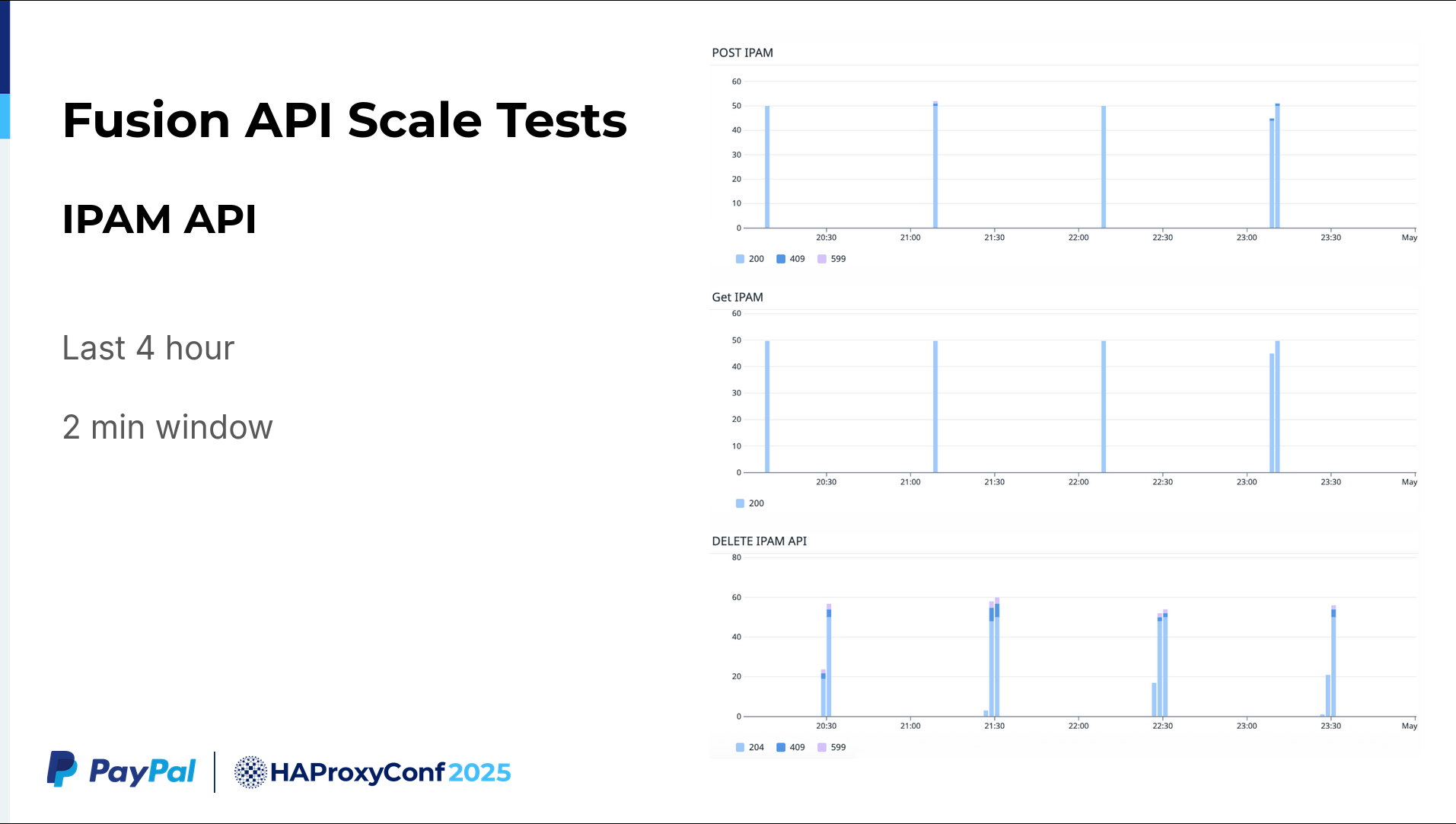
Regarding the scalability testing of the IPAM API: this is roughly a one-week dataset I have collected over a two-hour window. We are continuously running a regression test and LNP test. This two-hour summary depicts us making 100 IPAM API POST calls, GET requests, and then DELETE requests after a couple of minutes (following validation).
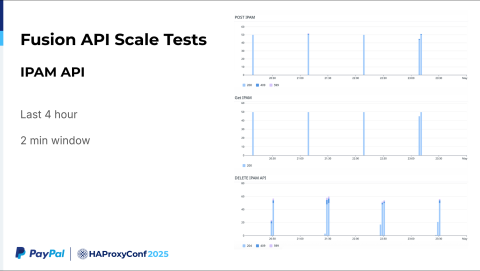
If we go a little bit more granular here, say the last four hours in two-minute windows, we make 50 API calls to the IPAM API. In a one or two-minute window, we create roughly 50 virtual service calls. While our requirement was merely 6 to 10, we successfully tested at five times that scale. It's highly scalable.
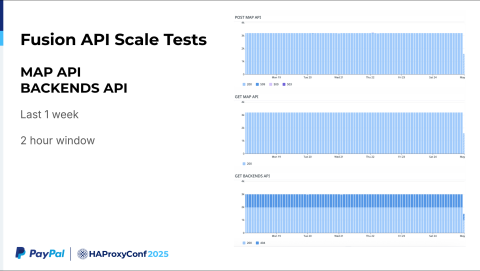
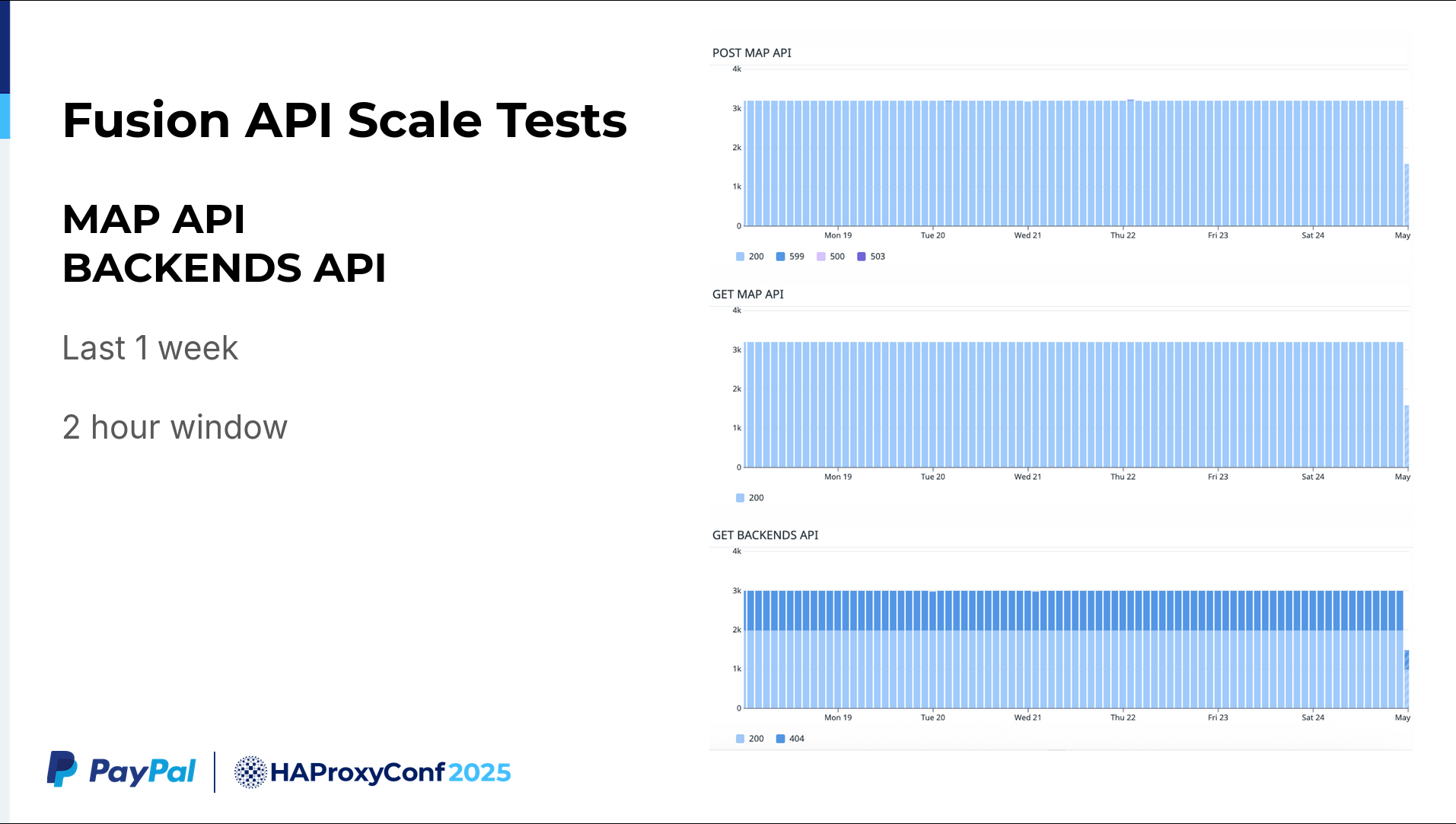
We collected data in the same way for the Map API and our backends. For the last week, we averaged nearly 3,000 calls across a two-hour window.
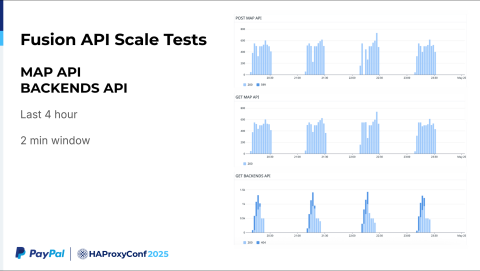
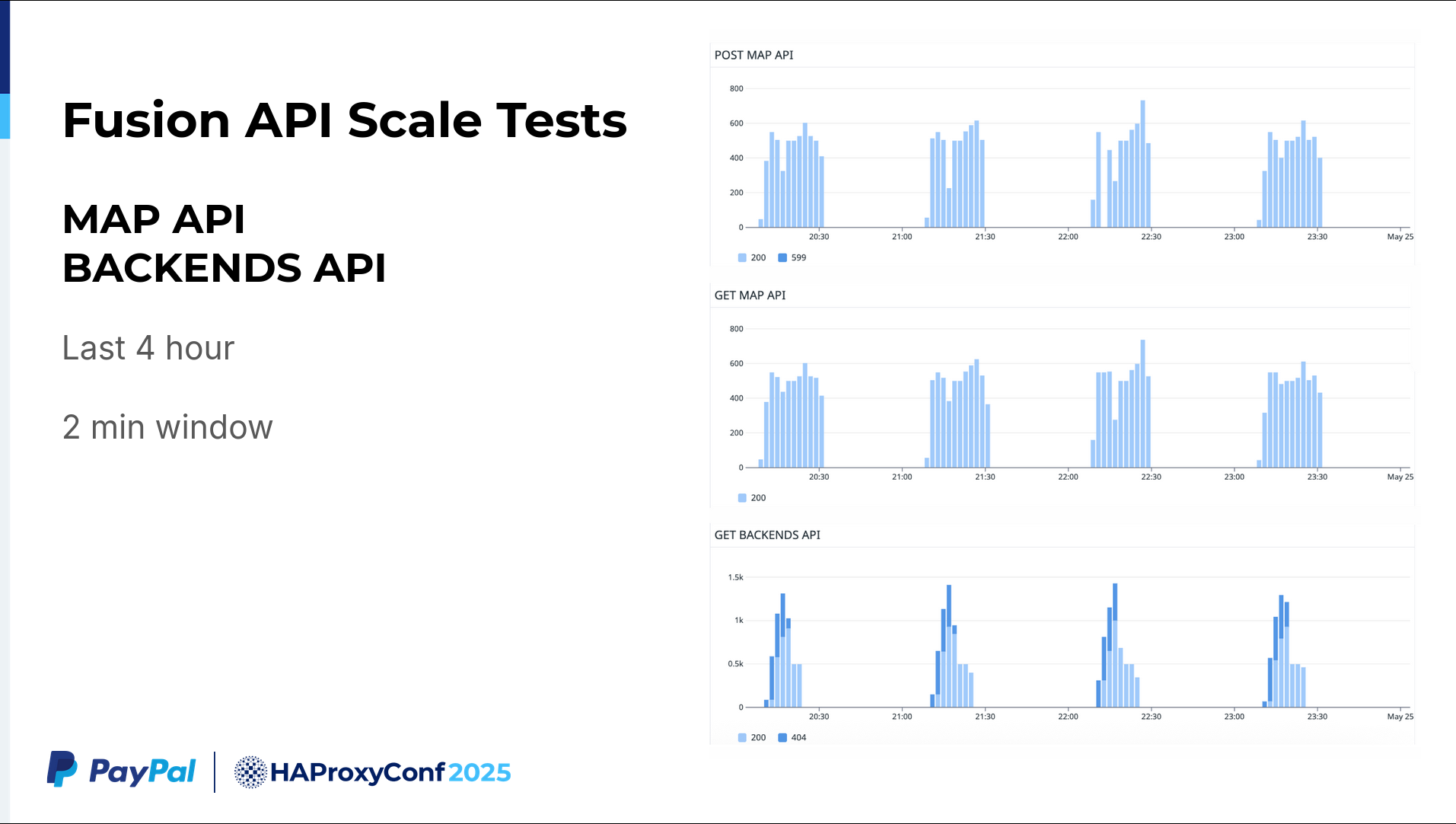
Finally, if you look at our last four-hour report, in two-minute windows, you'll see we make 200 to 500 Map API calls within this time period. The APIs can batch all of those updates together. They are then able to push everything to the HAProxy Enterprise config in a very quick fashion.
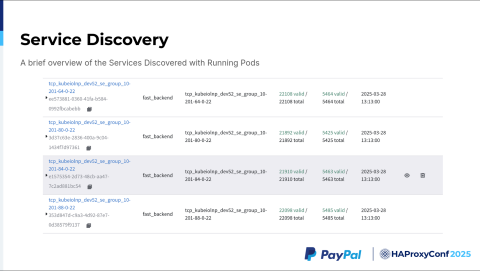
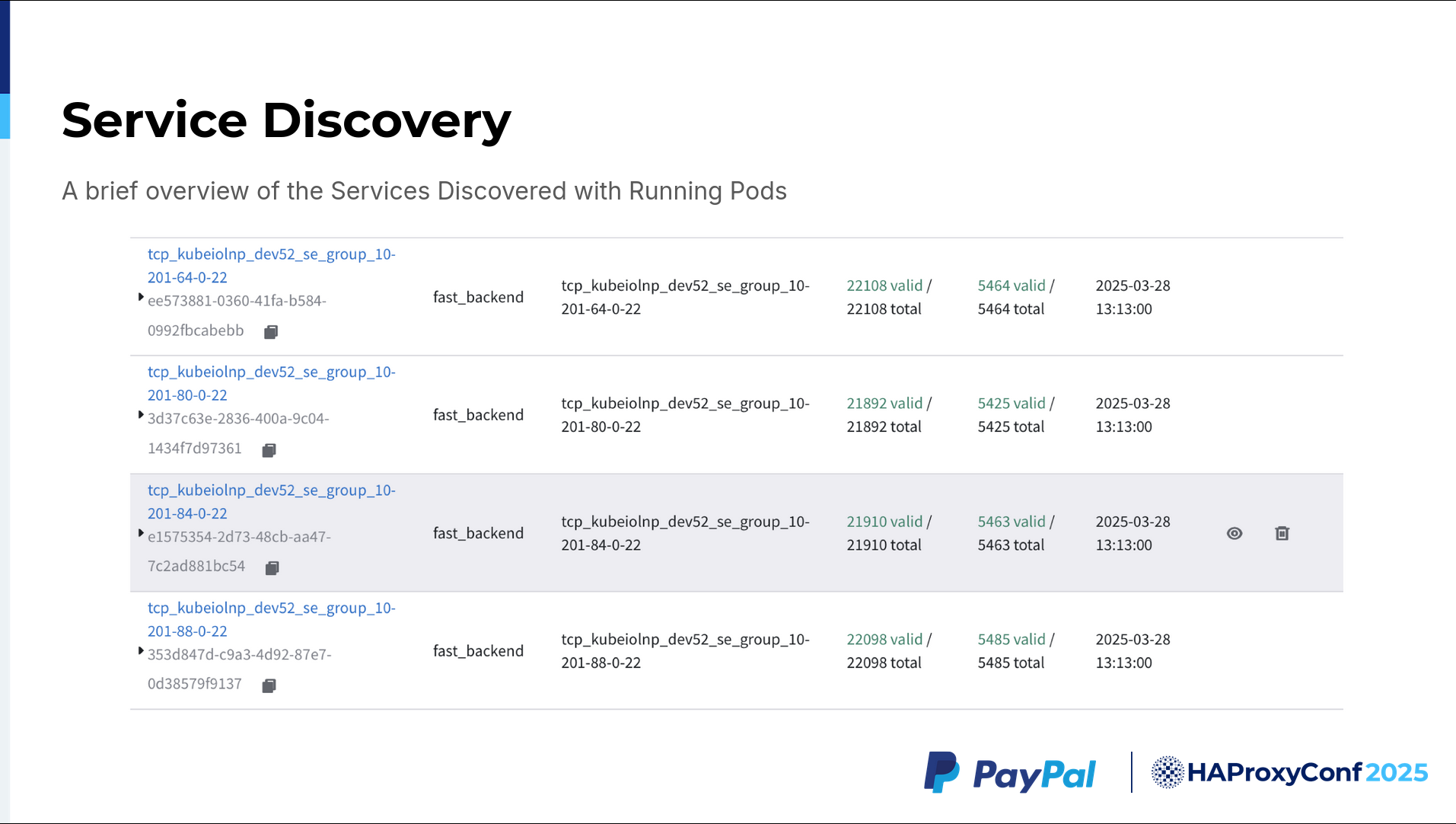
Regarding service discovery, we were told to test up to roughly 12,000 backends. However, we tested up to 20,000 or 22,000 backends, and HAProxy Fusion was very much stable for that.
The lefthand side of the service discovery UI shown here contains our various services, while the righthand side displays our total number of discovered servers.
