Under the hood, the HAProxy Data Plane API and the HAProxy Kubernetes Ingress Controller are powered by a shared set of Go libraries that apply changes to an HAProxy configuration file. In this talk, Marko Juraga describes how these libraries are developed and invites you to use them in your own projects when you need to integrate with HAProxy.
Watch Marko’s presentation video or read the transcript below.
Transcript
Thank you Daniel for the introduction. My name is Marko and I’m working at HAProxy Technologies and I wanted to talk to you about the HAProxy Go packages ecosystem. First, I want to talk about why we even created a Go packages ecosystem.

We created two projects: one of them is the HAProxy Ingress Controller for Kubernetes and the other one is the HAProxy Data Plane API. Both of those projects have been mentioned in talks before today. I’m the Lead Developer for the HAProxy Data Plane API and most of this presentation is based on it, but I’ll mention something about the Ingress Controller too.
We created those two projects, so we can easily integrate HAProxy within dynamic environments, an area that is, as we see, growing nowadays. One of the reasons behind choosing Go as a technology behind those projects is to expand our already great open-source community built around the HAProxy with more Go developers. With that in mind, I would like to invite anyone that has an interest to take a look at the projects I will be mentioning at our GitHub and try to contribute there. We will be happy to guide you through the process.

How did we create it and what technologies did we use? The first project we did was the HAProxy Data Plane API and it being a REST API, we chose a language specification to describe our API. Specifically, we chose the OpenAPI 2.0, formally known as “Swagger”. At the time, it was becoming a standard for defining REST APIs and it has a great tooling support. One of the tools that we used for developing the Data Plane API is the go-swagger tool. Go-swagger tool generates most of our useful code, meaning that it generates structs from definitions you create in OpenAPI YAML files. It generates validation functions, service skeleton functions and much more.
Our workflow while implementing it was that we wrote the specification first, meaning that first, when we add a new feature or make a change, first we change everything in the specification. Then we use the specification to generate the code, and finally we implement the logic for that feature. One of the benefits of using a language to describe your API, specification language to describe your API, is that you can use a wide array of tooling to generate the client code for writing your own apps that will interact with the Data Plane API.

Here’s an example how you can generate a client code library for the Data Plane API. For the example, I went with the Python client code library using the OpenAPI tools, OpenAPI generator. Generating client code for Data Plane API is as easy as calling those two commands up there. So, basically, you pull their Docker image from the repo and you run the Docker image with the following command options. What it does: it creates, in the output location you specify, a whole library of Python client code. It even creates stuff like tests, documentation, README files, travis files and much more.
The bottom example is an example how to add an ACL directive to your HAProxy configuration using the generated client code library in Python.
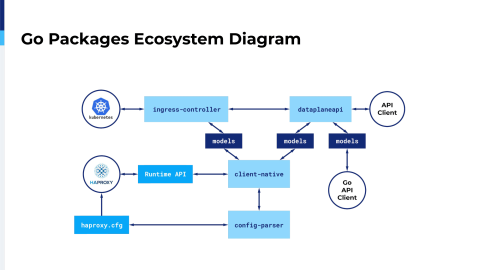
This is what this presentation is all about, so I’ll walk you through this diagram shortly and will explain each of the projects we have on our GitHub in detail in some of the following slides.
This diagram explains how our Go packages interact with each other. Note that this is a logical diagram. The only two projects built as applications are the Ingress Controller and Data Plane API. The rest of the packages are just Go packages used as dependencies in those projects. First, as you see on the bottom left we have the HAProxy running and we can interact with it using the HAProxy configuration, changing the configuration and reloading it and we can interact with it using the Runtime API. The Runtime API is the stats socket directive or the Socket API, however you want to call it.
One of the projects we have is the config-parser. It’s a straight up config parser, as the name says. It just reads and writes HAProxy configuration and stores it in a structured output. The client-native uses the configuration parser to parse the configuration and it uses the stats socket to get some information out of HAProxy like stats, like stick table entries and it uses the stats socket to reconfigure HAProxy on the fly. What client-native does with all of that information is that it packages it into the structs that are defined into the models package and we use those structs to pass information around between client-native and the Ingress Controller or the Data Plane API. Models is a standalone package. So, if you generate your own client code in Go, you can use the models package to interact with the Data Plane API or to interact directly with the client-native. Models and client-native packages are the core of both of our Go projects, the Data Plane API and the Ingress Controller. It’s basically all the server logic of the Data Plane API extracted from it.

Every method on every resource that you have on the Data Plane API is an exported function in the client-native package. We chose to do so, so that we can reuse that server logic in other projects apart from the Data Plane API. The first project that got to use it internally is the Kubernetes Ingress Controller and you can use it in your own Go apps to interact with HAProxy if you include the client-native package. The client-native, as I said, handles the configuration and the Runtime API. It has features like transaction management, meaning that you can bunch up a lot of changes to the configuration in one transaction and apply it atomically. It has configuration file versioning, it holds backups of configuration files and much more.
The other package is the models package. This package is totally auto-generated using the go-swagger tool. The go-swagger tool uses the definitions from the YAML files of this OpenAPI specification and it generates Go structs from those definitions. Other than those structs, it holds methods for validating those structs and it holds methods for marshalling into the JSON.

Here’s an example how you can use the client native in your own Go application. Those who are familiar, this is a Go source code. So, basically I’ve skipped init functions, error handling and much more. You can find all of that in the README on our GitHub project. In the first example, we get the www backend from the configuration file using the GetBackend function. It returns the configuration file version and the instance of the backend. We can then use that backend to edit it. In this example, we’re adding a stick table line to the backend we fetched and editing it with using the EditBackend function.

In the second example, we’re using the runtime client in the client-native. We created a stick table in the previous example and now we can use it in the Runtime API to show some information from it. We can use the ShowTable call to describe the table. It gives us the name of the table, the size, the used capacity. The second call uses the GetTableEntries, which returns all of the entries in that stick table. As you can see with those two examples, you can use the client-native and models package in your own Go application to monitor stuff on the HAProxy: to monitor statistics, stick table entries, and then you can react to them by changing the configuration in the runtime or in the configuration file and reloading HAProxy.

One of the other packages mentioned was the config-parser. The configuration, it’s just basically the configuration logic extracted from the client-native. It reads the configuration and it returns it in a structured output in a predefined order, meaning that it keeps comments and parts of the configuration, too, that it doesn’t understand; meaning that not all HAProxy directives are yet supported in the config-parser or the client-native. But don’t worry. If you have a running HAProxy config and you pass it to the config-parser, it will keep everything that it doesn’t understand in it, but the resulting file might be different. That’s just basically because it uses a predefined ordering. The logic of the execution of the HAProxy should stay the same.
The config-parser doesn’t use transactions, it has no knowledge of configuration files. It basically reads the file you give him and writes to the file you give him. It’s independent of our OpenAPI specification and it doesn’t use the models package. So a lot of overhead is removed from the config-parser and you can also include it in your apps too if you just want to read or write something to the configuration. In the config-parser we used go-generate to generate most of the useful code in it. It’s a tool in Go that you can specify some annotations in comments and then use go-generate to generate Go code.

Finally, all of those projects come together in two of our applications: the Data Plane API and the Kubernetes Ingress Controller. Chad talked about the Data Plane API in detail. I will give just a quick overview. Even Vincent mentioned our Kubernetes Ingress Controller, so I’m going to glance through these notes here really quickly.
The Data Plane API is a REST API for managing HAProxy. It runs as a sidecar process and it runs on the same machine as the HAProxy. It handles reloads, so it reloads HAProxy when necessary. We have a reload delay configuration option. If you have multiple changes in a short period of time you can set the reload delay so that the Data Plane API doesn’t reload the HAProxy every time. It just reloads in that period when there have been changes in that period.
Also, it uses runtime time whenever it is applicable to change the stuff in memory on the fly without reloading. We saw in a lot of presentations today that people have similar implementations of their own of this mechanism, so it’s quite standard as it seems. Also, the Data Plane API targets master-worker processes. If you have a setup running in multi-process mode, the Data Plane API will know and it will target the stats sockets of each process. Or if you have master socket setup, it will communicate with child processes using the master socket.
The Kubernetes Ingress Controller is our implementation of the Ingress controller. It listens for events on the Kubernetes API and it reacts to those events by translating them into model structs and using client-native to change configuration. Also, as the Data Plane API, it tries to avoid reloads as much as possible using the Runtime API. You can configure the Kubernetes Ingress Controller on multiple levels. The service objects, the Ingress object, and the Config-map.

All of our projects have been open sourced at our GitHub account, haproxytech. If you want to use those projects feel free to create issues for possible feature requests, bug reports or anything. We’ll be happy to answer and also if you want to contribute, we’ll guide you through the process. Here is a simple example how you can contribute.
In this example, we’re adding some fields to the server resource in the Data Plane API. First of all, you go to the config-parser, check if it understands that field and if it can parse it, you create a merge request there. You add them to our OpenAPI specification, generate the models package, implement the logic in the client-native package, and finally you generate the Data Plane API project using the specification. It looks kind of complicated, but when you get into it, it’s not.
