In this presentation, Vincent Gallissot from M6 describes how his company leveraged HAProxy to migrate their legacy application to the cloud and Kubernetes. They utilized many techniques, including infrastructure-as-code, deployments triggered by Git pulls, canary releases, and traffic shadowing. M6 also uses the HAProxy Kubernetes Ingress Controller to easily scale up or down their Kubernetes pods and gain first-class observability.

Transcript
Let’s talk about the journey to Kubernetes with HAProxy. Three years ago, the UEFA Euro 2016 took place in France. It was a big event for us because we broadcasted the whole live match on our streaming platforms.

The French team even made it to the Final, increasing our loads and exploding our bandwidth. I remember that final match because we were 10 colleagues at work, watching our Grafana dashboard, our monitoring screens and searching for potential anomalies. But nothing bad happened that night and we ended up drinking beers and eating pizzas.

I remember the fear, the fear that our platform could go down. The huge event we were experiencing could bring us down. That’s one of the reasons why we decided to migrate to the cloud, to use the elasticity of the cloud, so even the biggest events won’t be a problem anymore.

I’m Vincent. I’m a Network and Systems engineer. I work at M6. I’m the lead of the operations team. M6 is a French private TV channel and after some years M6 became a group owning 14 TV channels and doing all stuff. This group is part of the RTL group and for the RTL group, we manage the French VOD platforms, the Belgium VOD platform, the Hungarian VOD platform, and the Croatian VOD platforms.

This represents some nice users and we have some nice use cases. It’s a nice playground. We have some nice API calls and we have a seasonal use. So, we have different API calls during the day, during a week, and during a year. Everything’s different, so it’s really nice to follow.

We chose to migrate from on-premises to the cloud. For that, we check up our legacy platform. We were using almost all available CPU on our ESX cluster; 98% of CPU was used. So, it was time for us to migrate.

We checked. We had 30 microservices at this time, but they all follow the same pattern. Our backends are written in PHP and our frontends are written in NodeJS.

For all those applications, the traffic goes through a bunch or Varnish servers and Varnish servers forward the requests to virtual machines. The virtual machines all run NGINX for the HTTP part and PHP-FPM or NodeJS.
Migration to the Cloud
We decided to migrate. The first step to migrate was to create a platform in the cloud. For that we’re using Terraform. Terraform is a really nice tool because you can control resources you have in the cloud either AWS or Google Cloud. We even control our Fastly CDN configuration through Terraform. A really important thing for us is to write the projects, infrastructure-as-code, inside the GitHub repository of this project, since it gives a lot of autonomy to our developers and this is really nice to follow.

For example, we have an API to generate images. We have a lot of videos on our platform, so we have a lot of images for which we create thumbnails. One of these API images has a .cloud directory; and in that .cloud directory we have a docker subdirectory in which we have Dockerfiles and every configuration needs files to create Docker images. We have the Jenkins directory in which we have Jenkinsfiles to control the CD pipelines and every test over that Docker image. We have a charts directory, in which we have the Helm charts to deploy that Docker image inside a Kubernetes cluster; and we have Terraform to write all the needed managed services used by that API.
An example of a terraform directory: we have a single Terraform file for each managed service we use and the differences between every environment for those managed services are written in a dedicated vars file. So, if we have some sizing change between instance types and everything, we’ve wrote those differences inside dedicated environment tfvars. And the code…the rest of the code…is the same between all environments.

Each project is autonomous. If a developer needs a MySQL database or a DynamoDB table, you just write the code and open the pull request and give the pull request to an administrator. We review the code and together we apply the modification.

There are shared resources between all projects. For example, network, network policies, DHCP, everything that is shared between all projects. We have a dedicated administrator Git repository for that. A developer can open a pull request to that repository and propose an instance.

Now, we have a platform in the cloud using Terraform for AWS and all the EC2’s network and etc. We are using kops to deploy a Kubernetes cluster in that cloud platform. Kops is a really nice tool. It allows you to control the master nodes, the worker nodes of Kubernetes. You can do rolling updates. It’s really nice and it works almost out-of-the-box.

We had this application on-premises.
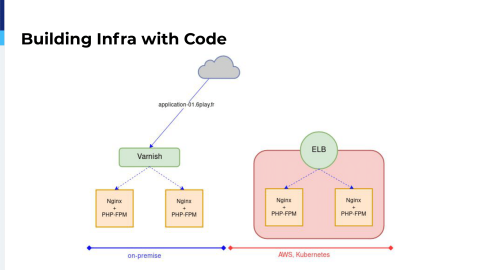
We took our time to build the cloud application, to deploy a Kubernetes cluster inside that application. Then the application was available through an ELB, an Elastic Load Balancer. So, the same application was available through our Varnish servers or through the ELB and we had to migrate it.

So, the first thing we did was to add HAProxy at the very top of our network. All the traffic for a specific application was going through HAProxy and at the beginning, HAProxy sent 1% of the traffic on-premises.

The backend configuration, it’s quite simple. We have a single backend for an application with two servers. The first server is our on-premises Varnish server. The second server is the ELB, the clouded application, which is disabled.

When we are ready we can start migrating production traffic to the ELB. For that, we start by sending 1% of traffic to the ELB and the rest on-premises.

The configuration changes a bit. We’re using weight as Oleksii just explained before. We also added observe layer7 on the second server, on the ELB server.
I appended parentheses around observe layer7 because this is really how we could secure our migration; observe layer7 is HAProxy checking for HTTP response codes.

HTTP response codes and it will adjust the health of the server accordingly, which means if we have 500, 502, 503 or 504, HAProxy will detect it and mark the server as unhealthy. In real life, we add this application, which we call the middleware. The middleware is the backend with two servers.


In blue, we can see the server on-premises, our Varnish server, and in green, the cloud server. As we can see, we have 5xx waves over the cloud applications, which means there is a problem. HAProxy detects those 5xx errors, marks the server as unhealthy, and automatically the traffic is routed back on-premises. So, there is no user impact and it works without human intervention.



Okay, back to our migration. We migrated 1%, then 2%, then 5%, then 10% then 25%. At each step, we observed HTTP response codes, the average connection time between HAProxy and backend. As we can see here, we have the green line which is the cloud ELB and in yellow we have the on-premises. We have only one millisecond difference because our on-premises is located in Paris and we’re using the AWS Paris region. So, we have only one millisecond difference between the two. This is really interesting for us because we could spend a lot of time migrating. It was not a problem of latency. We also checked for average response times because it’s really a nice metric for us to follow our applications’ performances.

Then, we ended up migrating 100% of the traffic to the ELB, but the traffic was still going through our HAProxy on-premises server.

At 100% of the traffic sent to the ELB, the first server, which is the on-premises server, was marked as backup, as Oleksii just presented, and we still used observe layer7 on the second server. Even at 100% traffic sent to the cloud, if there were problems, HAProxy would send it back on-premises.

Once we were ready, once our developer gave us the go, we just pointed the DNS to the ELB. This is our migrating our first application and the application time came after.

Until we faced a problem: To be cloud-native, some applications had to be rewritten. For example, our Images API, it was writing images into an NFS endpoint and we had to change it to write to an S3 bucket. For that we changed the pattern from before. There are two things we did.

The first thing was to replicate production traffic. We’re using GoReplay for that. It’s a really nice tool written in Go.
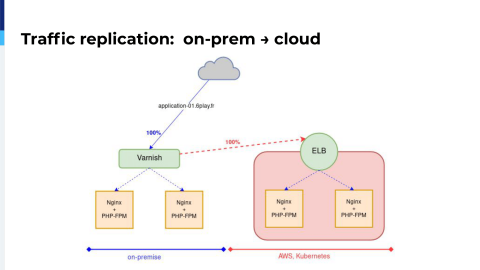
GoReplay allows us, at the very beginning of the migration, on the Varnish servers, to capture traffic and to duplicate that traffic to the ELB. We could monitor over the ELB how the application would react with normal production traffic.

That helped us find our limits and our capacities, limits of our NGINX and HAProxy and PHP-FPM configuration, limits over our Kubernetes autoscaling parameters, and also the capacities of the managed services we were using on AWS.

For example, on managed services you have known limits. When you create a DynamoDB table, you know that you have to define a provisioned maximum writes per second, which is in red. In blue, you can see that we replicate traffic and we reached that maximum. So we, by replicating traffic, we knew that we had to increase that maximum.

There are also hidden limits. Like we have this application using a lot, Redis, and we were replicating traffic and starting at 25,000 connections, our application was crashing and the error message was, “Cannot connect to Redis anymore.” So, we stopped the replication. We checked for everything, but Redis is not a serverless service on AWS. So, you have to check for the CPU, the memory, the disk and the network interfaces, and everything was going nice. CPU was not used, there was a lot of memory free, disks were not used and network interface, these were doing nothing.
So we were like, “Okay, let’s replicate traffic again.” We replicated traffic again and 25,000 connections and the application crashed again. We kept half of the traffic replicated, so we replicated only 50% of traffic and everything worked fine. We opened a support ticket to the AWS team and they responded, given the sizing of our sever, of our Redis server, the maximum connections was hardcoded to 25,000 and it was not written in the doc. To get rid of this limitation we had to choose bigger servers, even if they were doing nothing in the previous sizing.

So, replicating traffic helped us find our limits, but it also prevented outages before we could crash our production, before real users could experience it.

A gor script example is this one. We use a special BPF filter keyword, which allows us to capture traffic on a really specific port and TCP IP, and we’re sending the traffic to the ELB of the application in the cloud. With GoReplay, you can do a lot of things like change the request, add cookies, add headers, really do a lot of things. It’s a really nice tool.

HAProxy 2.0 comes with traffic shadow capability, apparently the same thing. I never tested it, I don’t know how it works. Don’t ask me any questions about it, I don’t know the answers. Maybe the HAProxy team knows.

The second thing we did to migrate our most complex application was to migrate only a part of the application.

So, we had this application-02 and we started to add HAProxy that will receive the traffic.

The application-02 has two paths, the V1 path and the V2 path. We know the V1 is legacy, we won’t migrate it. We will migrate only the V2 path and on the V2 path we want to migrate with weight and observe layer7, as we did before.

We’re using map files for that. We’re using map files from the very beginning. It was available in the configuration; and we’re using the special keyword map_reg, reg stands for regular expression.

Inside the map file, we define two regular expressions. The first one names the V2 path only. So, if the first line matches the regex, the traffic will be sent on the backend named application-02-migrating and the rest, which is a catchall, the second line, will be sent on backend name on-premises-only.

The backend configuration is quite simple. For the backend named on-premises-only we have only one server, which is our Varnish servers.

The second backend follows the same pattern as we did before.

With that, we could migrate the application from 1% to 10% to 25% only for the V2 path. Watching our Grafana dashboards, we could show that the V1 was less and less used. So, at the certain point we could migrate back the DNS to point it directly to the ELB. This is our migrating even our most complex application in the cloud.
Using HAProxy Ingress Controller with Kubernetes
Now, we’re still using HAProxy as an Ingress Controller inside Kubernetes. Why do we need an Ingress Controller for?

With the pattern we had, with one application and one ELB and we add one ELB, elastic load balancer, per application and per environment, this cost us a lot of money. Also, because on AWS and in the cloud generally, you pay for everything. You pay for starting your service, you pay for the number of requests that goes to your ELB, and you pay for the bandwidth that goes to the ELB. So, it was a lot of money.

We also have previews; previews is when a developer opens a pull request. If they add the correct label, which is cd/preview, the branch code will be deployed on a dedicated environment. So, the developer will be able to test the code and see the behavior. One preview means one ELB. We have one ELB per preview, per application, per environment. It is a lot of ELBs.

Also, previews can be deployed independently per tenant. We are four tenants: French, Belgium, Croatia and Hungary, and we are able to deploy a preview for specific tenants. So we have one ELB per tenant, per preview, per environment, per project.

So, of course, we reached the maximum possible ELBs for an account.

To get rid of this limitation, we thought about using ALBs instead of ELBs. ALB stands for application load balancer. ALBs are HTTP aware, so you can do SNI to support a lot of certificates and so have a lot of APIs on a single ALB. Because they are HTTP aware you can route requests depending on the Host header. The ALB will be able to send the requests using node ports.
That came with a problem of our implementation. Because our infrastructure code is inside the Git repository of the project, we cannot control a single ALB from different sources. Also, because we have previews, we have a lot of previews depending on pull requests, so it would mean changing a lot of single ALBs for each pull request. It would be a nightmare to maintain and therein comes the Ingress.

The Ingress is a load balancer, HAProxy. Inside the cluster, HAProxy receives traffic from the ALB and sends the traffic to the right container inside the cluster. To do so, the Ingress, HAProxy, needs an Ingress Controller.

The Ingress Controller is a tool. In the case of HAProxy it’s a Go binary that runs alongside the HAProxy container. It’s inside the cluster. It watches Kubernetes objects and so it’s able to modify HAProxy configuration accordingly. For example, if a project has specific routing preferences the Ingress Controller will watch the Kubernetes object and modify the HAProxy configuration. That means our project was not using modifications over ALBs. All the ALB code would be back written inside our administrator GitHub repository. So, there are no modifications over the ALBs inside the projects.
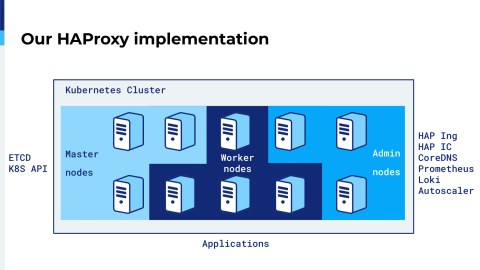
How we use the HAProxy Ingress Controller: We have a Kubernetes cluster in which we have some master nodes of the etcd parts and Kubernetes API and a lot of Kubernetes stuff. We have admin nodes and admin nodes are dedicated to administrator binaries like the HAProxy Ingress Controller. With the Ingress we have DNS, metrics, logging, autoscaling, everything that is administrator-related is deployed only on those admin nodes. The rest of the nodes are dedicated to our APIs and our applications.

HAProxy Ingress is deployed as a daemonset, so you have a single HAProxy instance running on each of our admin nodes.

An example: We have a client that makes a request to the ALB. The ALB, which sends a request to one of the admin nodes, and because the ALB is using a round robin algorithm, it would choose either this node of this one or this one. With HAProxy on each admin node, runs the Ingress Controller, which is aware of each applications running on each worker nodes. So, it knows if it can…HAProxy knows if it can forward the request to this container or this one or this one.

Applications. You can have a lot of Ingresses running inside your Kubernetes cluster. To say that your application will be managed by HAProxy we define an annotation, which is the Ingress class haproxy-v1. This YAML code is written inside the GitHub repository of a project and when we have the correct Ingress class set the Ingress Controller will watch those objects. The specific rules here are HAProxy will watch for the domain name foo-241.preview.bar.com and would forward the traffic to the service named foo-service on the NGINX port.

The Ingress Controller will watch this object and will create the HAProxy configuration accordingly. We will have three servers inside a single backend; So, three servers as three containers running for that service.

If we scale up, the Ingress Controller will know about it because it doesn’t watch only Ingress objects, but all the Kubernetes objects and it will add the new containers inside the configuration.

If we scale down, the Ingress Controller will remove from the HAProxy configuration those servers, those containers.
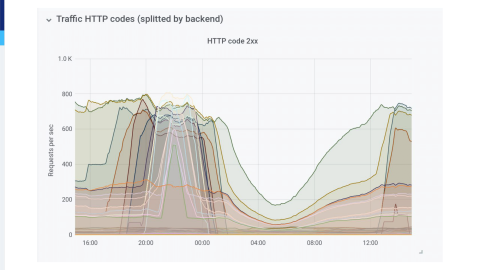
We keep an eye over the Kubernetes cluster from the Ingress Controller. We know everything that runs inside the cluster. We are able with the Prometheus exporter to watch metrics at the node level, at the service level, and at the container level. So, if something fails we know where it fails.

We also collect HAProxy logs. We’re using Grafana Loki, so we can even create dashboards from the logs; and it gives us a lot of information. For example, when an application fails, it creates a 5xx metric, but with a 5xx you don’t know if it’s a 500 or a 503. You need to dig in the logs to get more information.

A short summary from this presentation: We migrated our platform to the cloud because our on-premises platform was becoming legacy. It didn’t fit our business needs anymore. It was a business decision to migrate to the cloud.

We started to migrate, building the infrastructure in the cloud using kops and Terraform. All the infrastructure code dedicated for a project is stored inside the Git repository of the project.



We migrated a more simple application without downtime using observe layer7 keywords and we migrated complex applications by replicating production traffic and by migrating only a part of an application. Today, we’re still using HAProxy as the Ingress Controller and that let us define an infinite number of projects and of previews. Thank you very much for your attention.
