
Are you grappling with the challenges of exponential business growth, increasing traffic, and the complexities of managing load balancers in a rapidly-changing infrastructure? Philipp Hossner, Senior Staff Engineer at DeepL, shares his company's journey from managing a small online dictionary to building a leading AI-powered translation service — highlighting the pivotal role of HAProxy in navigating these growth issues. Philipp dives into DeepL's infrastructure evolution, the organizational hurdles they faced in empowering developers while maintaining best practices, and how HAProxy addresses a surprising number of these problems.
We'll also explore DeepL's transition from NGINX to HAProxy, the reasons behind this shift, and the subsequent move to HAProxy Enterprise within their Kubernetes clusters. Philipp discusses their innovative approaches to streamlining abuse protection, establishing "shoot-in-the-foot" protection with OPA Gatekeeper, and simplifying TLS management. You'll also learn how core HAProxy Enterprise modules for geolocation, fingerprinting, and bot management play a part.
Looking ahead, Philipp shares DeepL's vision for a perfect platform, where operators can create a simple and safe-to-use interface to unlock HAProxy's full potential when used as a Kubernetes Ingress Controller. Learn how custom annotations and templating could expose specific HAProxy functionalities — empowering developers while avoiding bottlenecks. This session offers valuable lessons for operators and developers alike from using HAProxy to reach operational flexibility.
Slide Deck
Here you can view the slides used in this presentation if you’d like a quick overview of what was shown during the talk.




















Hello everybody! I'm Philipp, and I like load balancers. But what do I want to talk about?

I would like to talk about DeepL first — what we do, what makes us different, and then a little history of our infrastructure, followed by the current state, and then a little look at a possible future.
Let's see.

DeepL was created in 2017 — that's not so long ago — and we provide AI-powered machine translation and writing assistance services. Our translation service has about 30 languages. Actually, it's a matter of how you count them, so really, it's 30-plus. And Write currently supports four languages, but it's increasing every once in a while.
DeepL was not entirely new. It emerged from an online dictionary company. You can see what I mean by looking up our Wikipedia page. HAProxy has actually been used in this company, if you count the online dictionary, since 2013.

Since about 2019—two years after its inception — DeepL's business has grown exponentially. And with it, so did the number of developers, web services, machines, data centers, changes in the infrastructure, requests per second, traffic spikes, and attacks.
Well, it was exhausting. It was challenging. This is especially how we operators felt during these years.

Sure, there were technical challenges — but more interestingly, organizational challenges. We constantly faced questions like how to enable developers without requiring them to know the infrastructure, especially if it's constantly shifting around and changing. They are not supposed to know that. They are supposed to actually focus on what they're good at and not say, "Hey, where do I need to deploy this?"
We also contemplated how to enable developers, but not enable developers too much, because they might shoot themselves in the foot. This is actually what the meme over there is referring to. Please raise your hands if you've had this kind of situation as an operator. Okay, at least a few.
We also had to determine how to enforce best practices and avoid organizational bottlenecks, which was especially challenging.

So, how does HAProxy actually fit into all this? This was a rather generic problem, right? Load balancers are affected first by growth issues. For example, if you have more traffic, scale up the load balancers. You get more abuse suddenly — stop it at the load balancer. Please don't let it come to our applications.
You get more endpoints. You suddenly have to manage a bigger load balancer config and come up with new solutions to that. You have more teams, and suddenly you have to think about something like blast radius. How do I keep one team from messing up the configuration for another team or bringing down the entire load balancer (which is also possible)?
And, of course, compliance. When you grow, you need compliance, and then you need to think about things like a web application firewall and bot management. Thus, HAProxy was involved in—and also solved—a surprising number of growth issues.
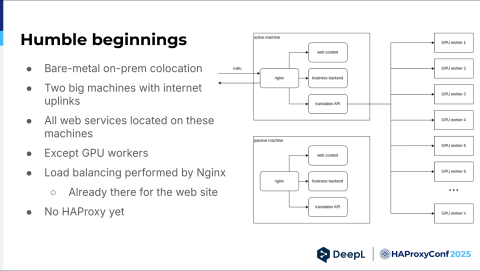
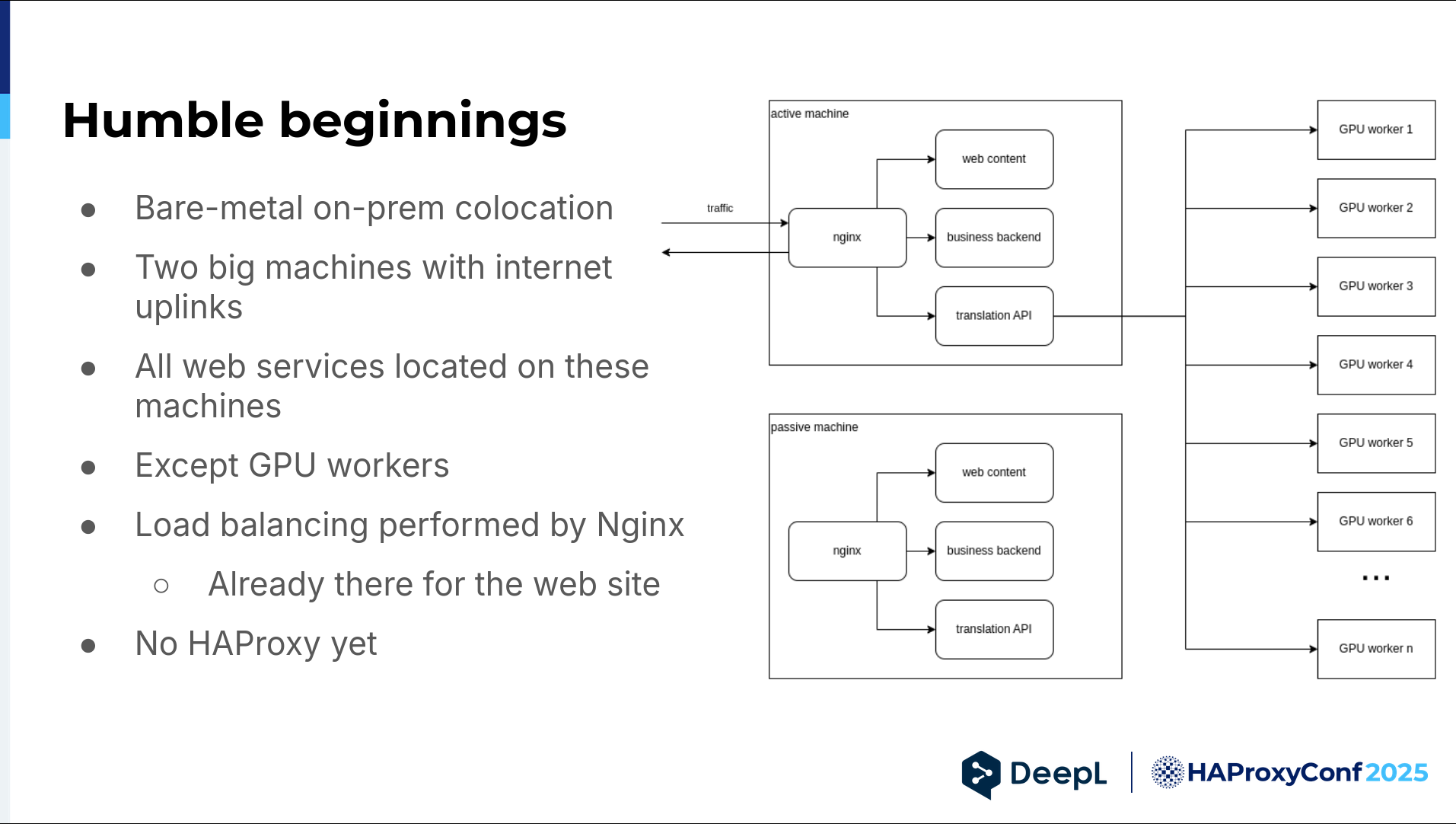
We started out small. We are still mostly on-prem, but back then, we had two bare-metal machines on-prem (co-location), and those were an active-passive pair of machines. They both just had internet uplinks. We also had an NGINX on them, and it reverse-proxied to web content, our business backend — think payments and such — and our translation API. This API talked to all of our GPU workers.
But why NGINX? There was no decision. We needed to serve web content, and we already had NGINX. We also needed to do some load balancing, and NGINX can do that as well. It's fine. There's no HAProxy in the picture yet outside of our old online dictionary.
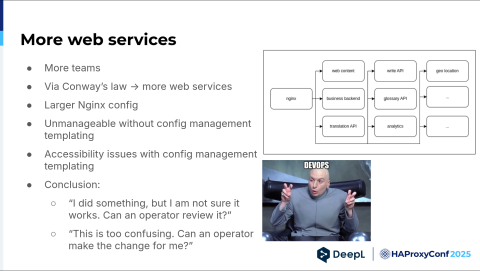
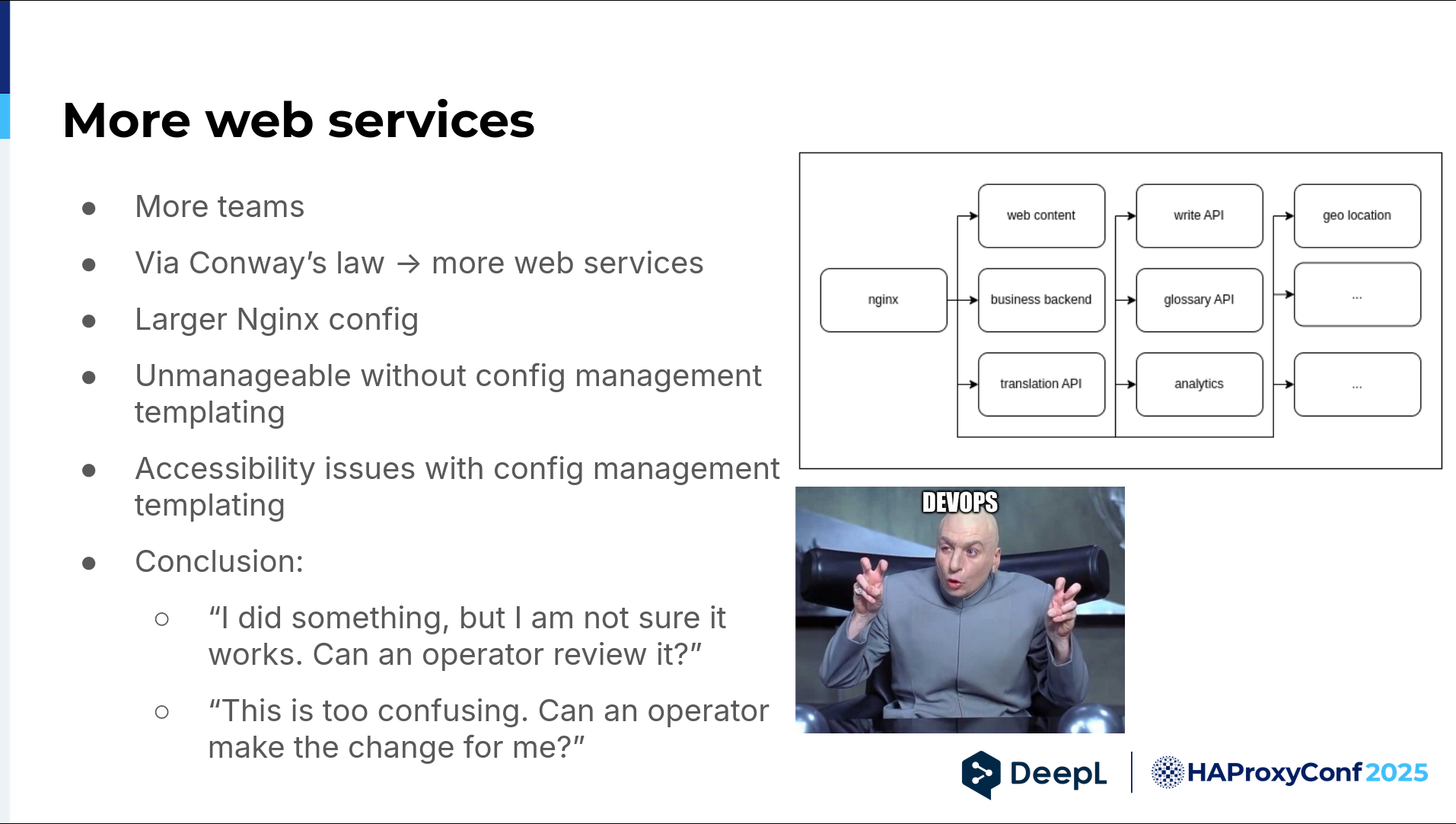
So, we started hiring a lot, and we had more teams. Via Conway's Law, we also had more web services, which you can see in the diagram. We suddenly have an API glossary, API analytics, geolocation, and so on and so forth. The list just grew. And it was still all on that machine, by the way, but it was quite beefy.
We had a larger NGINX config that quickly became unmanageable without templating, and the templating was done by config management. But templating usually comes with additional mental load. This led to developers saying:
"Hey, I actually know how to do NGINX things, but I tried something. Can you review it, please? I'm not sure whether this works. I'm not familiar with your config management system. I don't know how it deploys. Can you have a second look?" Most often, they'd say, "This is too confusing. Can you just do it? I would like to have that subdomain. Just do it, please."
And yeah, this is the DevOps everybody's talking about (chuckles).
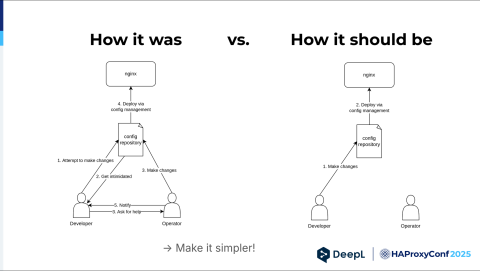
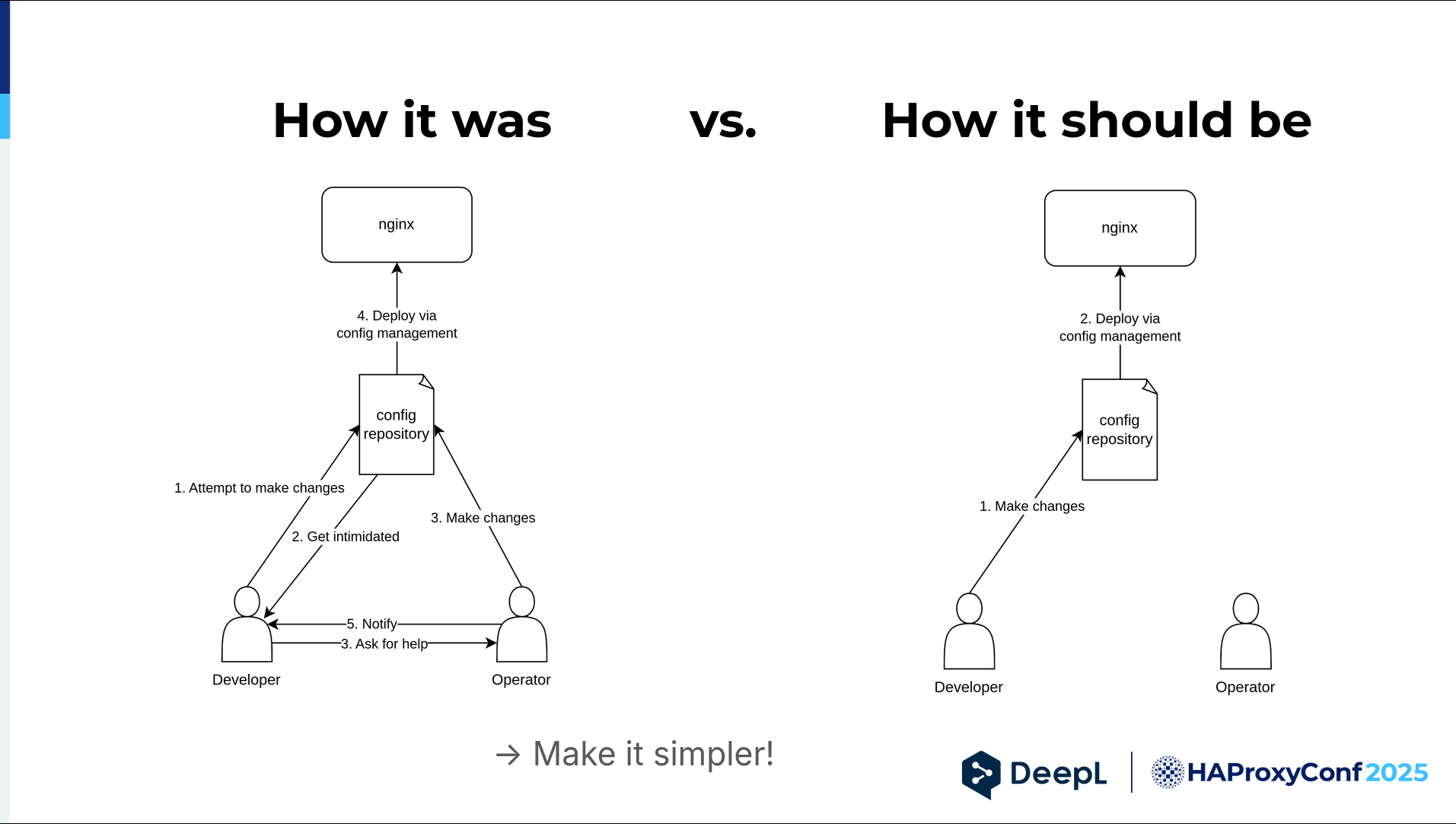
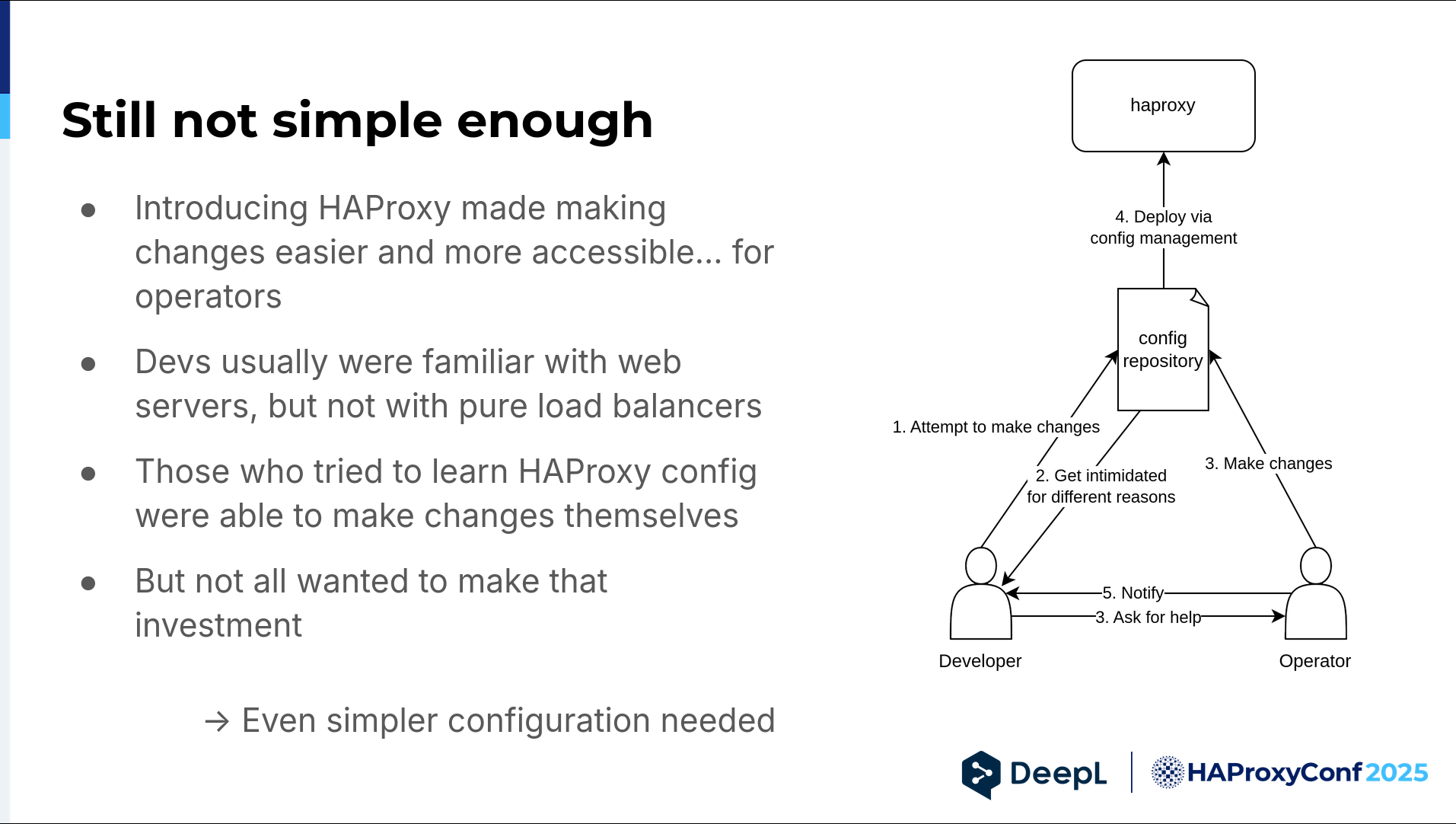
Let's reiterate how it was: The developer wanted to do something, got intimidated, and then came to us. We had to do it ourselves and coordinate with the developer.
So we said, "Okay, can we deploy now?" Maybe the developer was at lunch, so we had to put this off — and maybe I was at lunch when the developer came back, and so on. It's unnecessary.
It should be like this: the developer wants to make changes, does them, and the operator has their hands free to do something else. How do we get from left to right? We had to make it simpler somehow and give developers the confidence to make changes themselves.
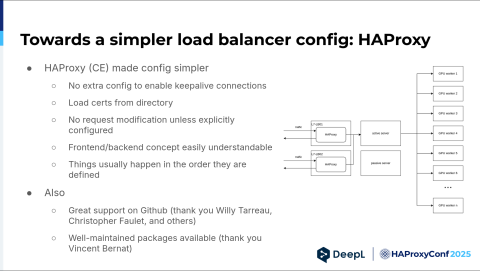
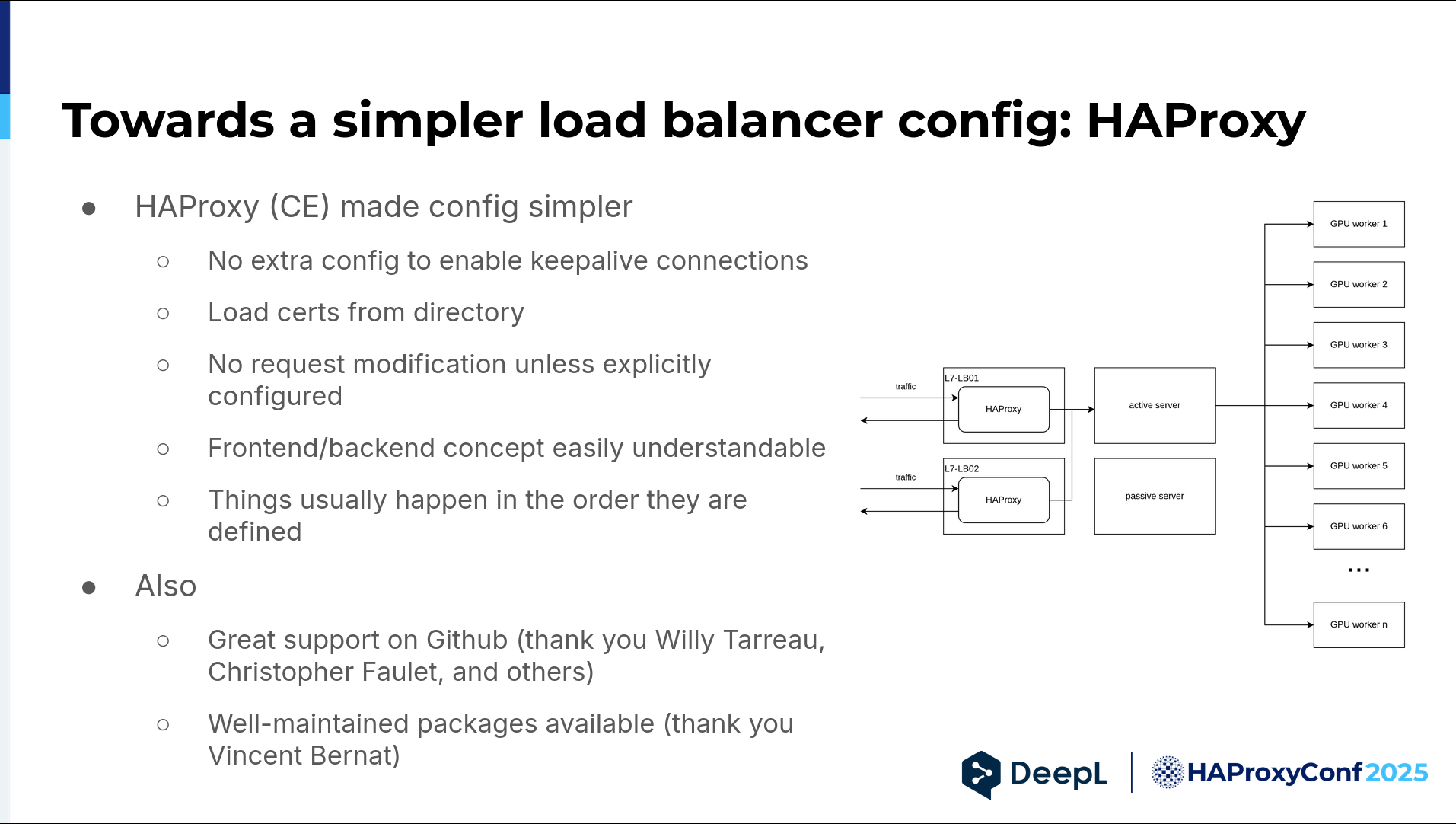
The first step towards that was realizing we were not happy with NGINX and how it did configuration, and remembering we still worked with HAProxy for our legacy online dictionary. We knew HAProxy, and there were certain aspects we liked about it.
The first and most important one was that no extra configuration was needed to enable keep-alive connections toward the backend servers. I do not actually know how it is now with NGINX, but back then, you had to include several lines for each upstream to ensure a keep-alive connection pool was established. And if you didn't do this, you learned that problems like ephemeral TCP port exhaustion exist, and you have a lot of fun finding out why that happened.
We also liked that you could load certs just from a directory. With a growing number of services, we had more subdomains, we needed more certificates in certain cases — because we also had subdomains — and wildcards didn't cover that.
We could throw it all in a directory, and it worked. This is more of a personal thing. It's less for my colleagues, but I really liked that the no-request modification was done unless explicitly configured in HAProxy — unlike the proxy pass directive of NGINX, which sometimes rewrites the host header. Things like that. I think it's unnecessary.
The frontend and backend concepts were easily understandable, and things usually happen in the order they are defined. I'm aware that there are also request-response phases and other phases between them, but you can usually just read the config, start here, go there, and understand how a request is processed.
Plus, we experienced great support on GitHub from the get-go. Thank you to Willy Tarreau, Christopher Faulet, and all the others who always jumped on an issue when I opened it. Also, thank you to Vincent Berna for providing well-maintained packages.
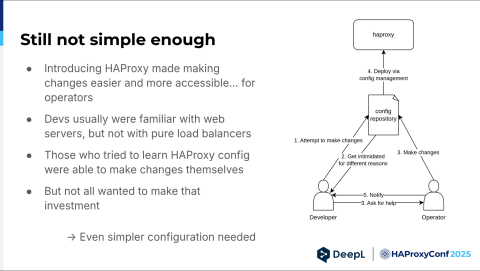
Alright, so it kind of worked. It made changes easier in theory, mostly for operators, because they had to learn how HAProxy worked and were happy with that. Developers were usually familiar with Apache, NGINX, like all the web servers, but pure load balancers aren't something they usually encounter during their day. They had to make an extra investment to do it, and yeah, not everybody wanted to do that. Basically, we had the same graphic, but this time things got intimidating for different reasons. It didn't change that much, sadly. We needed to make it even simpler.
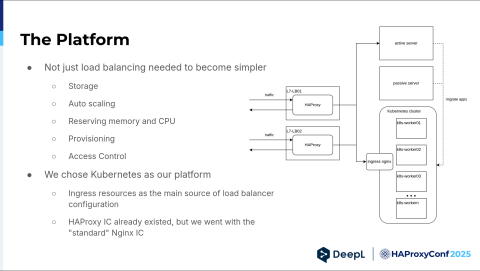
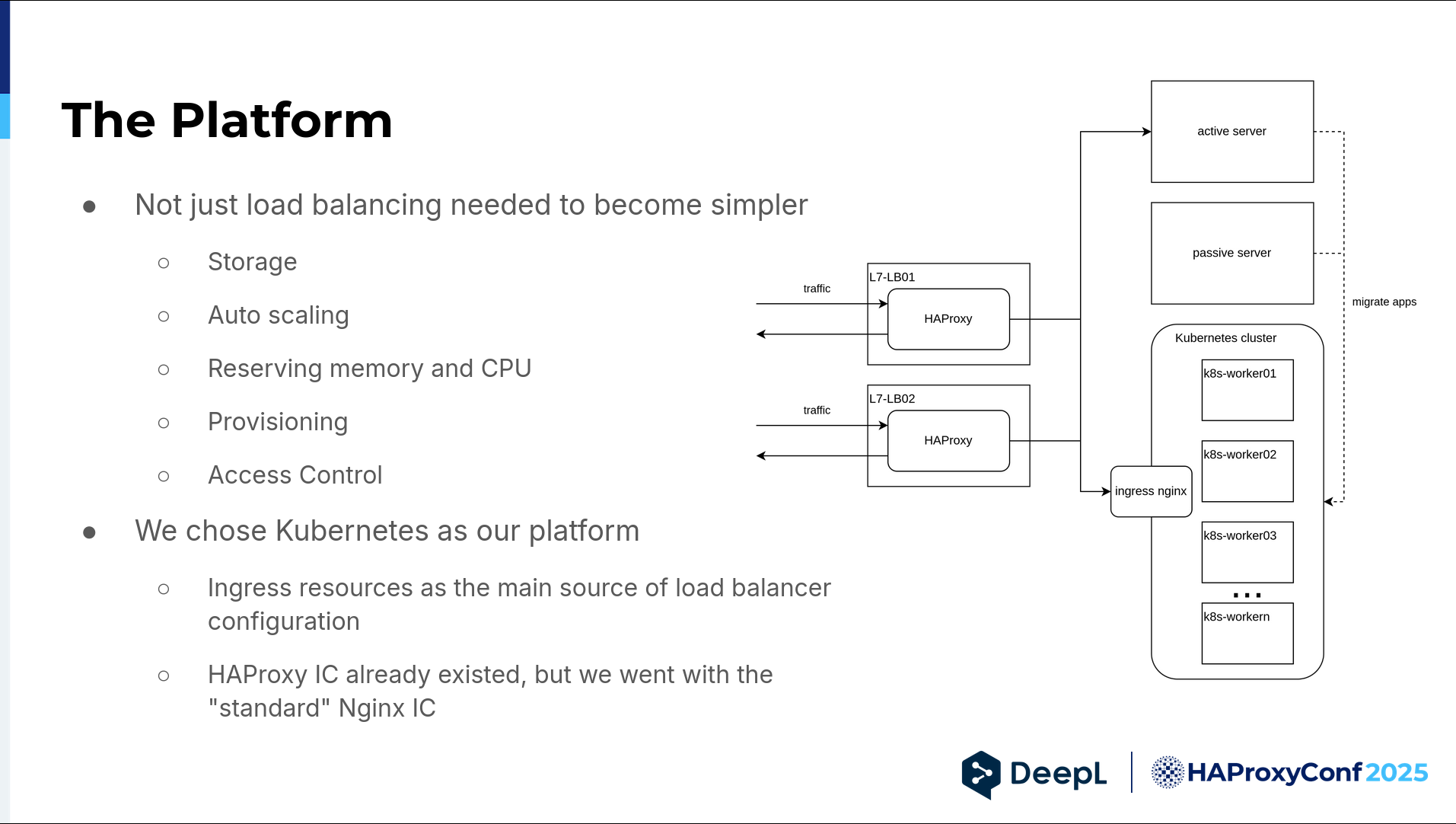
This came at a time when we had to simplify more things. We had to simplify storage provisioning, autoscaling, resource reservation, provisioning in general, and access control. For us, Kubernetes was the obvious choice. Ingress resources were already the main source of our load balancer configuration.
HAProxy Kubernetes Ingress Controller already existed back then. I looked it up. But we went with the standard NGINX ingress controller for the same reasons we stuck with NGINX in the first place. It was the standard, the default, the safe option, and we just wanted to get the cluster off the ground because we had our hands full. As you can see in the graphic, we still had our beefy machines, but we started to migrate all our apps to the Kubernetes cluster.

I just wanted to illustrate this. Envision you're a developer and just want to get your app online — you don't care about the rest.
On the left side, you have an HAProxy config, or maybe you have some abstraction in config management. The point is you see the global options, the default options, and all the things that are in one or more frontends. Then you have to add an ACL and a used backend, and then you have to add a backend, and you see all this in your POV.
On the right side, there's an ingress resource. You can give it a name and add a domain. In most cases, you need to know your service name and port name, and you're good to go.
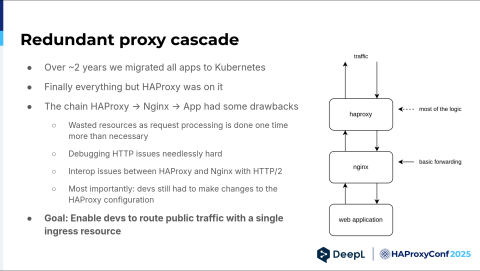
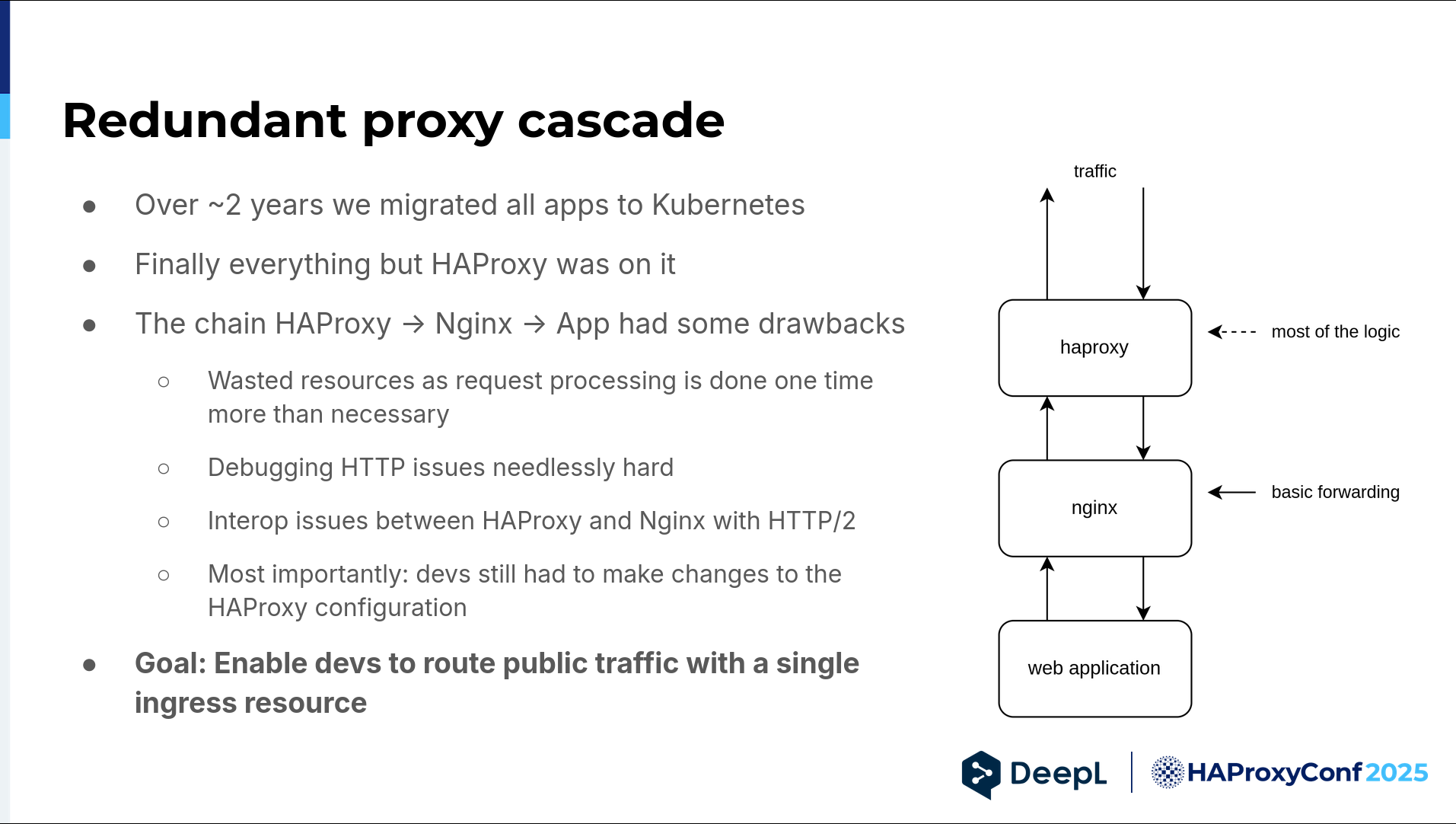
All right, so we migrated everything to our Kubernetes cluster, but then we had a new problem. We had a redundant proxy cascade because we basically had two L7 load balancers in a row. The first had all the neat little things we put in the configuration over the years, and the second was just more or less dumping forward requests. It was really unnecessary. It wasted a lot of resources, and debugging also did not get easier.
We sometimes had some issues with HTTP/2 between the two, and most importantly, sometimes developers didn't have to create only an ingress resource — they still had to make changes to the HAProxy configuration. We really wanted to enable developers to route public traffic with a single ingress resource and then be done.
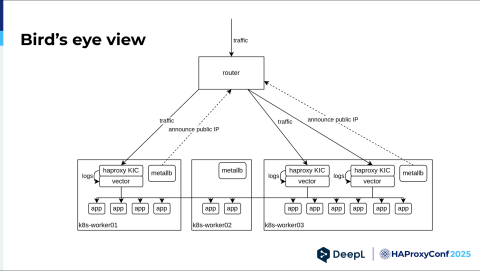
How does it look today? First, I should share one more thing. We actually coupled two things. We wanted to use HAProxy as our own ingress controller and ditch the old bare metal load balancer in front of it, which also had HAProxy.
However, we also encountered the issues I described earlier, most notably the compliance issues we had. We also wanted to have better rate limiting using stick table aggregation via HAProxy Enterprise's Global Profiling Engine. We said, "OK, we have to do a big project anyway. Let's just get HAProxy Enterprise and do both things at once." On our existing Kubernetes clusters, we installed HAProxy Enterprise Edition as an ingress controller.
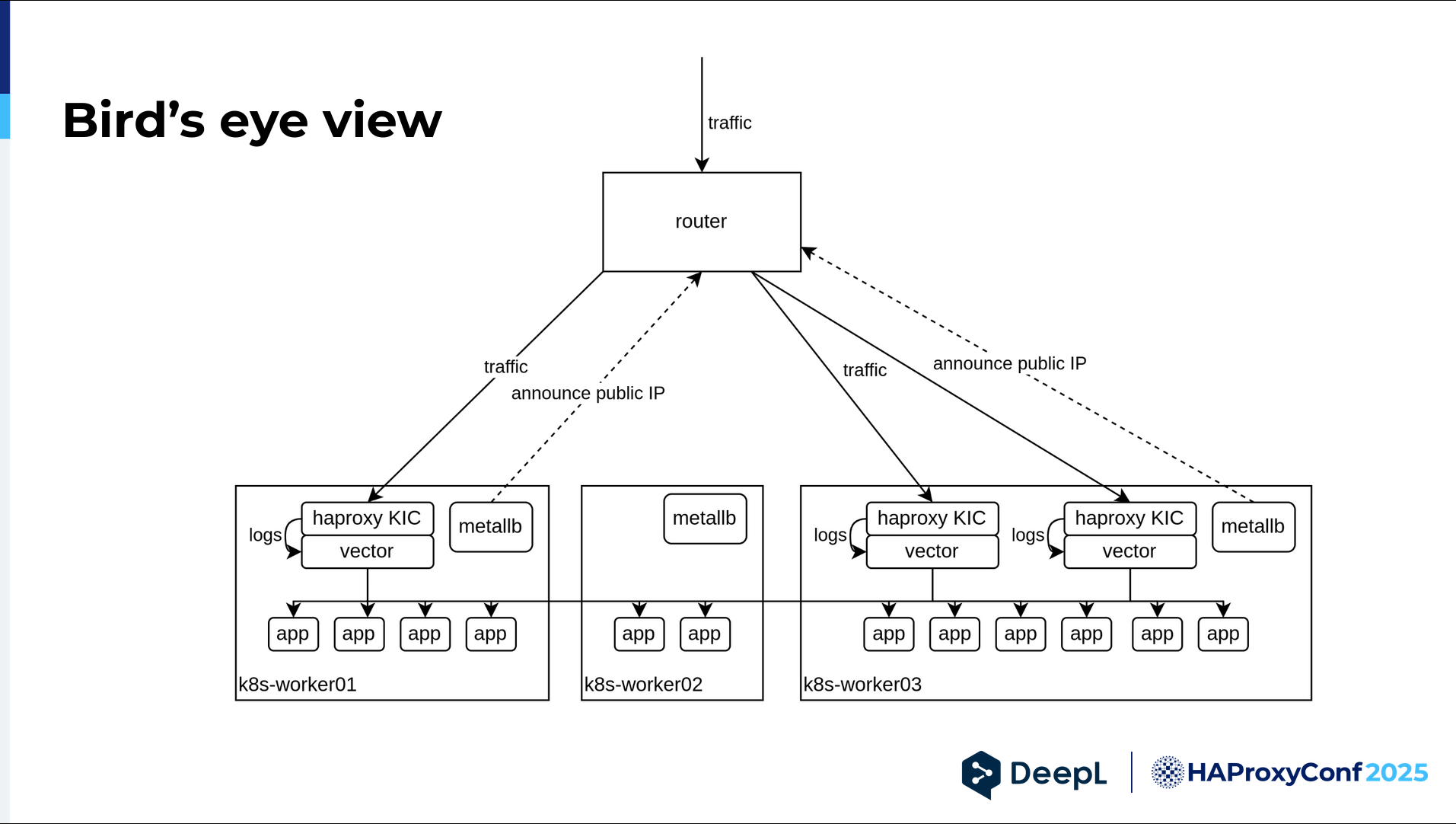
I left out the router in the previous graphics because it wasn't that important, but here I think it's a little bit more necessary to show it. On each node in our Kubernetes cluster, we have a neat little application called MetalLB. It announces the HAProxy public IP via BGP to the router, but only from nodes where a HAProxy Kubernetes Ingress Controller is actually present. This is a specific load balancer service setting you can set. Then, only the nodes with an HAPRoxy Kubernetes Ingress Controller receive early traffic directed by the router.
Each HAProxy Kubernetes Ingress Controller node has a sidecar with a tool called Vector. Vector is a log processor, and we really like that it's written in Rust, is very fast, and can aggregate logs to metrics. We can actually get many more metrics than our original HAProxy instance offers, and we can really customize it to our needs. Meanwhile, HAProxy Kubernetes Ingress Controller knows about all the apps we have, and then it does load balancing.

I talked about how to avoid bottlenecks. One bottleneck we eliminated first was our abuse protection. We have a dedicated abuse protection team, and they own our block list, graylist, and whatnot. But they still had to go over our config management and our repo. We had to approve it. You probably have your reasons for putting that IP there — I cannot vouch for anything. And we rubber-stamped it, basically. Then you can just eliminate it.
We created a Git repository with all the block lists in it. Then, we had a CI/CD pipeline. When it was successful, we uploaded all these files to the web server, and then we used the HAProxy Enterprise LB Update Module to pull new block lists every minute. It's rather simple stuff, but it works.
The best thing is that we never hear about any issues. When somebody remembers from our earlier days that we did that, we just say, "Hey, there's another Slack channel for the abuse protection team. Just do it over there. They can make all the changes you want, and you never hear from them again." We then have our hands free to do something different. In the future, we would like to do the same or similar with HAProxy Enterprise WAF rules. We are currently using the WAF in learning mode. While it's not really active yet, we are currently learning.
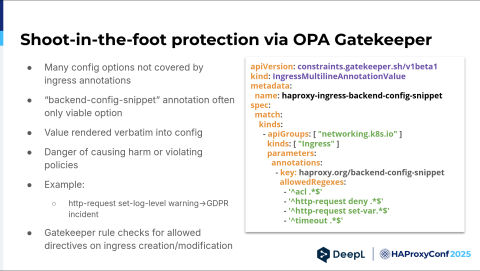
Next, we established some shoot-in-the-foot protection via a tool called Open Policy Agent (OPA) Gatekeeper. The Gatekeeper tool is nice because you can add validation for almost any kind of resource the Kubernetes cluster offers. We wrote ourselves a validation rule for the backend config snippet. There's a specific ingress annotation for HAProxy where you can put configuration verbatim into the backend. This can be dangerous.
For example, if you just say, "Hey, I raised the log level," a very detailed request log is suddenly sent to standard out and then collected by our log collector. It's then shipped to our logging system, and roughly half the company can read it. Not good. Our Gatekeeper rule checks for a loud directive, so we basically go with the loudest approach. We say, "Okay, we found a new use case." We need to put the statement in the regex list for that use case.

There's no TLS management, which means that developers never have to fill out the TLS part of their ingress resource. We have a default certificate, which has many subject alternative names. Developers have to adhere to certain conventions regarding domains and subdomains anyway, so all of our white cards just cover it. There's nothing they have to worry about.
Also, they do not need to think about a TLS redirect. It's hard-coded. They can't have it any other way. Even if developers try to disable it, it's always redirected because we don't think there's any valid use case for public traffic to go unencrypted. That's two more sources of error eliminated, so yet again, more time on our hands.

Finally, we added some nice information to every request via three modules from HAProxy Enterprise: geolocation, fingerprinting, and bot management. You can either ignore the header or make a more elaborate decision about what to do with that request. By the way, we had it both enabled and disabled, and from a latency point of view, it didn't make any difference, so we left it on.

We are now thinking about the future. A few things would complete our dream of a perfect platform, and HAProxy can help with that.

Our current "problem" is that HAProxy is actually a very powerful tool. Every time a developer asks me, "Hey Philipp, we have this weird use case. Can HAProxy do that?" I usually say, "Yes, in two lines — boom — what's for lunch?"
The problem is that HAProxy Kubernetes Ingress Controller is an abstraction on top of that. As abstractions often do, they only expose a fraction of the functionality that HAProxy is actually capable of. You have the backend config snippet that I mentioned earlier, and here's an example where you can restrict the maximum body size. This is not offered as an annotation. Currently, our developers essentially say, "Hey, please copy-paste this into your ingress and change the number to what you like — and yeah, I hope it doesn't break."

It's a little bit overwhelming for developers. It's error-prone. Maybe they change the number to something that does not make sense, or accidentally remove a comma. It's hard for developers to evaluate whether they did the right thing.
In this case, I could just go to HAProxy Technologies and say, "Hey, can you implement that for us?" Then it's yet another feature request. You guys have been awesome, and it was always very quick, but you're also only humans and have limited time on your hands. If you really want to implement all the HAProxy functionality all the time, when you're done, Willy Tarreau pushes a new HAProxy version and then you start from scratch, right? You have to implement all the new or changed functionality.
We actually propose something different. Let us operators help do at least part of that for you. Let's imagine we want an interface like this. We have two annotations: max-body-size-bytes and max-body-size-deny-status. This should basically implement what I've shown you before. You have the snippet, but now you have nice little annotations. And the developers don't have the mental load of wondering whether they did this right. Just copy-paste the left side of it, add a number on the right side, and there's not much I can do wrong — except maybe missing the quotes. That's Kubernetes and YAML for you.

To help administer that, I suggest using the config map we already use to configure the HAProxy Kubernetes Ingress Controller and adding a new key called custom annotations. Fortunately, this is a space only administrators can edit, so we can ensure that people who at least know what they're doing can edit it.
Imagine we have two keys in there — max-body-size-bytes and max-body-size-deny-status — like two custom annotations, maybe some validations, a default value, and most importantly, a templating snippet. I used a Go template here, but I don't really care. Just having a templating engine there is important. Then you can say, "Okay, if the annotation even has a value, then please render this and put the annotation value there, plus the annotation value of the other annotation elsewhere."
The other annotation doesn't have a template, but it has a regex validator where you can monitor for 4xx status codes that make sense. Of course, this is just a suggestion of how something similar could look.

In the end, we would like to offer our developers a simple and safe-to-use interface to unlock the full potential of HAProxy. Plus, there are so many use cases no HAProxy developer even thinks about, and I'm confronted with them every day. It's very unlikely that all of them would get implemented upstream because some only make sense for us, and nobody else.
Next, we have customized access logging, and we may want to add a field, but we want it JSON encoded so it can be put into a JSON field in ClickHouse. Or maybe we're using Global Profiling Engine, but it's not officially supported yet within Kubernetes Ingress Controller (for example), so we do it ourselves. Then you need to modify different variables to actually make the rate limiting work. This could also be exposed via custom annotations.
Recently, I looked at the canary deployment feature, and you have to add an annotation on the service. People are used to using annotations with ingress. I don't think every Helm chart at DeepL even has a feature for adding annotations to services, so we would have to re-implement it. Those could be potential use cases for something like this.
Ultimately, operators could ban backend config snippets and selectively expose functionality they deem safe. In turn, HAProxy Technologies could remove itself as the bottleneck for exposing new HAProxy options. As I said, it's probably never going to happen where every functionality is exposed as a combination of annotations — as far as we know. Maybe somebody will prove me wrong in the next ten minutes, but I don't think any other ingress controller actually offers this feature.
Alright, that's it! Thank you very much.
