In this presentation, Oleksii Asiutin describes how thredUP evolved from a monolithic application to a fully containerized, distributed system that is powered by Kubernetes. His team used HAProxy as a main routing point to distribute traffic simultaneously to the existing and the new system. They gradually increased the amount of traffic that went to the new system, which allowed them to fix issues along the way with less risk. HAProxy gave them real-time observability, which they used to quickly identify potential problems.

Transcript
Thank you. Hello everybody, welcome to the Kubernetes HAProxy talk. Today I will describe how we migrated our cloud-based microservices infrastructure to Kubernetes infrastructure and what role HAProxy played in it; but before that let me introduce myself again, maybe, and my company I work in. So yes, I have both experience in software development and platform engineering, which helps me to popularize this kind of DevOps culture and practices in [the] company. I live in Ukraine. We have a big community of engineers and I’m organizing our DevOps digest newsletter, which runs monthly. And I work now as a staff software engineer at thredUP.
thredUP is [the] biggest consignment and thrift store in the world. We have, we process about 100,000 second-hand items daily and we have about 300,000,000 items available for sale every time online. We have a lot of distribution centers, which is powered by automation; you can see it on the video. And all this is run by software and platforms that run the software.

In terms of engineering team, thredUP is not so big. We have about 70 software engineers, we run about 50 microservice applications and everything is about on 100 EC2 nodes in AWS.
We have Ruby, we have NodeJS, we have Python and we are exploring more programming languages like Java and so on; and we started in 2009 as a monolithic application written in Ruby on Rails running on one dedicated server.

But with the time passed, we grew as a company and we migrated to a microservice architecture deployed in Amazon Cloud; and here is where HAProxy came into play because it acts as our main routing point, delivering requests from a bunch of microservices based on request URI prefix, based on hostnames, and so on.

But with time, comes, we decided to containerize our application and we were looking for a unified deployment platform for containers and Kubernetes seemed to be the right solution. And we had this type of architecture and infrastructure and we wanted to get this type of infrastructure where every service is kind of abstracted by a Kubernetes service.

And so we began our migration and actually we did it. We did it within a year. We even have a case study on Cloud Native Computing Foundation. And we receive a lot of gains from it, not only in our deployment process, and we also received a big hardware decrease because it’s about fifty percent. We improved performance; We improved scalability of our services and you can read about it here.


But the actual point is that during the migration we have to support this type of infrastructure we have. When you have your old one, when you have your new one, it’s two separate networks and you have HAProxy load balancing between it; and I will describe to you our migration plan and migration process and I will give you some examples of issues and gains we bumped and how we solved it.

So our migration plan, it looks actually pretty simple. So if you have a service and you have it functioning on EC2, you need to prepare a Kubernetes deployment and for that you need to containerize it, maybe do some tweaks in [the] codebase to prepare it to be container ready. You write Docker files, you update your continuous deployment pipelines, and after that you test it in a Kubernetes environment. Does it deploy? Does it actually, the container runs? And if everything is okay, you deploy to the staging cluster, you verify it works, you verify it functions, it can communicate to other services; and it sounds like a simple process, but I think everyone knows, you can bump into a lot of issues during these steps.
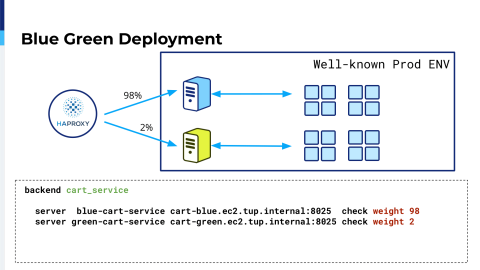
But if everything goes okay, when eventually you’ve fixed everything, you deploy to production. And in terms of production I think a lot are familiar with blue-green deployment. It’s when you route some small amount, percent, of traffic on your new deployment. Like in this we have two percent. Below you can find backend configuration for such an initiative and after that you run your test, you analyze logs, you analyze errors, and if everything is okay you switch 100%.

And you may want to use your old deployment as a backup. You can see it from configuration. You add a backup option.
In case something happens, you can switch back. But the case is like classical blue-green deployment in that you deploy new release and old release. You have it in the pretty well known environment. It’s your production environment and you run it daily like deploy and deploy.

And in our case, Kubernetes was completely new to us and it was completely new and we didn’t know how our service can react and what can happen. So we started with cookie-based routing.
This is when you, in client, you specify cookie and you configure your backend service in that way, that it serves requests to the new release only if you have this cookie specified. And in that case you can manually, or with some integration automatic test, you can verify that this new release in the new environment, it works and functions at least close to your old production service release.

After that you can do pretty much the same, weighted routing for the service; but in our classical blue-green deployment version, we did two percent, one hundred percent. This way we decided that we can go so fast and we do gradual weight increase on our new Kubernetes deployment. So for a single service, this kind of weighted pass would be different but it’s just an example like you take two, 10, then 20, 50; and you still have your cookie set if you want to test some…if you want [the] client to talk to [the] Kubernetes service directly for your test reasons. But here it goes, and not to mention, okay we did test all this cookie routing. We did test all this weight-based routing increase in load and everything works perfectly okay. We switched it to 100 percent to [the] Kubernetes-based service.

But, you still…it’s good practice to leave your old deployment as a backup and also there may be not very convenient points that you have support your deployment pipelines to deploy on both old and new infrastructure and to be bumped in such cases when we have, for example, two days of new Kubernetes service functioning normally and then something happens, you have down time and having this backup option and your old infrastructure is really good point. We investigate it; We fix it; Back to Kubernetes service. But having this I would say for two weeks maybe, your old deployment as a backup strategy, is a good point.
And okay, it was our migration plan. It was our path for migrating, an example, a single service from the old infrastructure to Kubernetes cluster; and it sounds like success and yes, it was success; but is the actual thing that during this path it wasn’t so straightforward and we bumped into a lot of issues; and I will name a few connected with this, maybe, HAProxy configs, with connectivity; and the first one is in Kubernetes.


If you deploy it in Amazon as a service, it’s represented by a load balancer and during this gradual traffic increase on our newly deployed service, we started to notice that we had downtime and servers became unavailable. We switched it back to the old one and to the backup service and we started to investigate and it seems like AWS does autoscaling out-of-the-box and behind the scenes, and it works perfectly, but it does it in a way that during the autoscaling it changes IP addresses behind your load balancer DNS name.

And in our case, like HAProxy, we didn’t do dynamic resolvers; and in our case during autoscaling, HAProxy on the start resolves your DNS load balancer name to specific IP addresses and when AWS ELB scales, we get new IP addresses and old IP addresses are unavailable. And so we have service downtime.

The solution is pretty simple from [an] HAProxy configuration standpoint. You have to define dynamic resolvers; You have to specify your AWS DNS nameserver; You configure cache allow time, lifetime, retries, and everything like that; and you specify this resolvers on the backend and after then, everything works mostly. You don’t have any downtime.
It was [an] unpleasant case when we experienced such problems, but we quickly solved it, but it’s worth to mention that you can have it and please use dynamic resolvers. I think it considers not only AWS. It considers every cloud-based provider and even if you have [a] DNS name in your backend on servers and if you plan to change IP addresses behind it, please take it into account and use it.
Okay, the other not to mention point, when you deploy your server, when you do migration of your service to Kubernetes, you probably have your dependent services deployed in the old infrastructure and during this migration you have to communicate with both in this new one and in the old one and maintaining two deployments like new one and old ones simultaneously makes you provide connectivity with, for example, that database layer from Kubernetes and from your old infrastructure. And the point is your old data layer and dependent services has probably deployed in the old infrastructure. And, okay, when you do deployment you set up for example Kubernetes as a single, separate network and it’s not so easy to connect to these resources.

Of course, eventually you migrate everything to a new network, to a new platform and it includes databases and everything like that. But during the migration, you have to maintain them simultaneously.

So, and the good point that we already had HAProxy deployed in the production network, in the old infrastructure, and we decided, hey, why not use it as a proxy and just to define a couple more frontends for the database, for elastic file system, for example, which we use regularly; and to use it as a temporary solution for the routing to just to configure firewall to enable access for these resources only from Kubernetes network. And this way you can maintain this connectivity and have this temporary problem solved really fast and in a secure and reliable way. That’s it.

Okay, you migrate services. You do it day to day and sometimes you see that it’s not going so well and monitoring seems to be a good place to look and to look for metrics and to see if everything goes well. HAProxy provides you with a bunch of metrics and we use DataDog as a monitoring dashboard. We use 200 errors, 500 errors, and it seems it was very useful. For example, if you migrate a service and you notice an increase of 500 errors, you can dive in and investigate further.
Apart from that, we used a lot of metrics like response times from HAProxy to the backend and from the HAProxy to the client; and sometimes it gave us a lot of benefits to notice [a] problem immediately and to fix it. I will name one. What is the downside of Kubernetes, if you can say so? Because if you deploy your service on dedicated hardware, is it bare metal or cloud based? You just reserve an EC2 instance with sufficient capacity. You know how much memory it has, how much CPU it has, and you use it and your service works on that instance and everything is okay. If you need more, you provision more.

In Kubernetes, for example, if [a] service starts to consume more resources than you expected, it could be a noisy neighbor for other services. And yes, we have this resource management. You set up fixed capacity for a service; and sometimes you try to investigate. Okay, what it will be if I reduce or maybe the service doesn’t need so much resources? And you actually reduce. You can see, we reduced memory footprint and which service requests, and we noticed that latency increasing ten times like immediately. So, HAProxy metrics help us with monitoring and to prevent such experiments and bad experiments from going to production. That’s it.

I will also tell you about our configuration management because during this migration you have to update HAProxy configs a lot, maybe even multiple times a day; and we decided that it’s not good to do it by hand and to do it by just verifying from other engineers and it’s good to use configuration management. So, we store all HAProxy configs in GitHub and we use pull requests to review so we can verify and having two couples of eyes, at least, is a good point to verify everything works perfectly. And when we do pull requests, merge it. We update our continuous integration pipelines in that way we provision configuration on all our HAProxy servers and this way, we could do migration in a kind of predictable, reliable and secure way.
So that’s it. As I said, we succeeded in migration. HAProxy helped us a lot, doing it reliably and in a predictable way. And if you have some questions, I’m ready to answer and thank you very much.