In this presentation, William Dauchy and Pierre Cheynier describe building a self-service infrastructure platform that supports 50,000 servers at Criteo. HAProxy Enterprise is their preferred layer 7 load-balancing technology because it provides robust health checks, log sampling, and TLS offloading. Its ability to run on commodity hardware is cost effective and allows them to scale horizontally to accommodate any sized traffic. Their platform allows load balancers to be created on-demand, giving their teams convenient Load Balancing-as-a-Service.

Transcript
Hi everyone. I hope that you are awake! I’m William and this is Pierre and we are both from the Network Load Balancer team at Criteo. Today, we are going to talk about transitioning from ticketing to a Load Balancer-as-a-Service. This subject, interestingly, you will find some connections with the presentation from this morning from Booking or GitHub.

So, at Criteo infrastructure we have lots of different projects, which some of them are very interesting to us. One of them is about replacing our operating system on our network switches. We are using the SONiC open-source project for that. We are also starting to take care of our servers with the Open Compute Project. The project I can mention, replacing our BIOS and also our BMCs. But today, we are going to talk about load balancers, for sure, with the HAProxy transition we did.

Criteo infrastructure was for a long time a quite big, growing, bare metal infrastructure. After a while, we introduced the platform as a service hosted on Mesos. The important thing here is that we made sure to put everything as transparent as possible for our developers.
What I mean here is that every application starting on the Criteo infrastructure is registering itself into our service discovery, Consul, in order to make sure that every service can discover each other for east-west communication.

On the network side, we also did some work along the years. We did implement the CLOS Matrix design, which is quite well known today because it’s implemented in a few big companies. I won’t go too much into details into that, but the important thing here to understand is that it made it possible to scale our data center horizontally. The second point I wanted to mention is that every server is able to communicate with another one with the same network cost. However, something like two years ago there were still some issues to resolve because some network services were still very specialized in a specific part of our data center. Here, for sure, I want to talk about our load balancer.

Let’s go back on the developer point of view at Criteo. Back then, two years ago, the developer was able to push his application and trigger everything so that everything is deployed whether it’s on bare metal or a platform-as-a-service or for a container. But when it came to deploying to production, there were lots of missing points you can think of to make a production-ready application. So, I’m thinking about IP, DNS, TLS certificates, etc. Everything was handled by human people and through tickets. Today, we are going to try to show you how we did resolve this automation part, but also make sure that we can horizontally extend the load balancer infrastructure without any specific hardware.

William mentioned that our transition to microservices has been done mainly through Consul because it’s a good layer of abstraction for different applications so that they can see the difference between a legacy bare-metal machine and a container-based solution. Our point here was to understand at that time, it was around 2016, if we can’t extend this model to be able to do the same with networking. The goal at the end was for the developer to be able to specify how they want to deploy their app, network speaking.
I won’t enter too much into some gory details because this morning there was an awesome talk about that from Booking and GitHub, but we’ll try to focus more on what’s specific to Criteo. The first thing we did as a team at that time was to define APIs for our end users. The way we introduced these APIs was by writing our own DSL and API extension for our existing execution environment. The goal here was to have the exact same primitives everywhere, again so that people can see the network as a flattened environment completely agnostic from the execution environment. This, for sure, was tightly linked to the Consul registration.
I took a small example here. So, you have someone defining an app with a port and with a network service data set, which is in fact a matter of adding metadata. The first part here for these folks are apparently to create a service named superservice and under the domain criteo.net. Their visibility, this is a public service and they have a strategy regarding the DNS entries we would generate. Then, they can specify stuff related to HTTP. For example, they want a redirection between HTTP and HTTPS to be enforced.
Finally, at the end they can introduce routing features through these semantics, let’s say. For example, here you see that they almost do a sort of canary, meaning that for 20% of the requests on foo and bar they redirect the traffic to the foobar app, which sits within our DC. Same, they are able to offload stuff such as the security policies to an existing app. So, it fits quite well with the microservice approach where you have existing services and you can reuse them when you deploy a new app.
Here I have something to mention that is very interesting. We are really focused on making only features expressed through intent and never to mention technology. The goal at the end for our team would be to be able to completely swap technologies when we want. The consequence of that, also, is that the ownership of the network app config has completely moved from our team, the network teams, to the end-user. At the end, it’s the developer that defines self service and their requirements.

A second thing we had to tackle at that time was the health checks. As you may know, health checks can be very complex and they should be very close to the application and the developer. If you envisage loading health checks into all your load balancing technologies, at the end it could be a mess and, worse than that, it could multiply the source of health checks and consequently you will end up having a lack of consistency between your different systems.
So, the idea here was also to leverage Consul and to make it a state reference. At Crito we try to contribute publicly when possible and this is why we started this initiative and these pull requests on Consul to create a dedicated endpoint. The goal of this endpoint was, for an existing app, to be able to retrieve an aggregated view of the health of an application.

Let me enter a bit into the detail and what it all has to do. We have on every machine at Crito, we have a Consul agent. When an app pops in there is a registration which happens on the loopback, on the localhost. Then there is a health check mechanism that takes place. Finally, at the end we can offload the health check traffic to the Consul agent so that we test both the health, we have an aggregated view of the health, and the network path. We check, also, that the network path is valid and that it works. Finally, we can stop forwarding traffic because we are sure that everything is supposed to be healthy.

How do you do that with HAProxy? It’s a matter of adding, nowadays, two lines. The first one is referred to this new endpoint. You have to specify the name of your app, like in this example, foo-bar. The second one specified the Consul default port, which is 8500. Okay, so if you want to use that on your side it’s available since version 1.4 of Consul. We are quite proud of this contribution, actually. It helps a lot.

At the end, we still missed some things, right? William mentioned that people want to have their VIP, their DNS entries, their configuration to happen automatically, right? So, here we have the scope of a system. As a specification this system should take events in entry. It should consume events from the service discovery and on the other side it should configure load balancers. In the middle it should grab the missing resource to a different asset manager we can have at Criteo, such as an IP asset management system or TLS asset management, so that we can take care of renewing certificates automatically; but also it can configure external systems such as DNS, CDN, whatever you can think about.
At Criteo we did that in two steps. The first one was to create what we call internally a control plane, which basically takes care of consuming events and producing events on another end. The app in production is available through a WebSocket API, which is described with OpenAPI and so on. This component, there is one instance per DC to ensure the consistency when we try to resolve resources.

The second part is what we call device provisioners and the goal of this component is to translate normalized events and normalized objects into a vendor-specific implementation. There is one contract and multiple implementations and at the end if you want to create one at Criteo, it’s a matter of implementing this because, as you probably know, nowadays everything is software, right?
It has been historically written in Python, but it’s not really a matter of technology because we can swap. There is an API for that. These components run themselves on top of our platform-as-a-service infrastructure in a plain container, Linux container. Here, for example, you see that if you implement the get_device and the pre_provision, you enter into a sort of provisioning workflow and at the end you are able to introduce a new technology.

Now that Pierre showed us how we did implement our control plane, let’s have a look at how we are using it. First, the first thing for us, which was quite important, was to have something fast on the control plane so that every developer pushing a new application can have a load balancer configuration within a few seconds. Here we are talking about less than 10 seconds. It’s very important for us because if you want to do a test for one hour or less this is something which can be totally done.
Also, as mentioned in other presentations as well, we provide metrics, for sure, related to everything you can think of related to our networks. We put this example. I think it’s the biggest application at Criteo: 4,000,000 QPS at the time. That’s a pretty huge one.The developer can subscribe to those metrics in order to trigger alerting, for example.

We continued this work in order to improve even more the experience from the developer point of view. As most of our applications are HTTP-based, we, by default, push a tag on Consul, which triggers automatically any new application pushed on Criteo so that when you push your application without even thinking about it, you get a default load balancer configuration. So, you can test right away. It comes with a default configuration as close as in production: TLS certificates are working properly, our HTTPS redirection, etc.

People were starting to use it quite a lot and I think they were quite happy about it. At some point, we got, let’s say, some strange surprises where people started to use it a lot, especially for this kind of load balancer, which had to be internal for internal testing. That’s the other side of the picture where users started to use it extensively and somehow started to break the load balancer on our site.
That’s where we introduced the usage of the HAProxy configuration named tarpit in order to make sure that the developer is aware of, yeah, maybe in this kind of case where you have thousands of instances, maybe this is something you don’t want to do. If you want to benchmark your applications, please prefer the east-west communication I was mentioning at the beginning of the presentation.

These kinds of incidents brings me to: How do we actually operate our infrastructure today? As Pierre mentioned before, we are able to implement any new load balancer technology. That’s what we actually did to transfer our traffic to HAProxy and we were quite happy about it because it’s permitted a very smooth transition without the user noticing it.
As you probably understood, at Criteo we are talking quite often about big services. To give you an idea, we have 50k servers across the world, which is quite a lot. When you need to push a change or a new version, anything you can think of, we have a system called choregraphie, which helps you to somehow control what you do in the production. You select part of the infrastructure; In our case, for the load balancer—by the way it’s between 50 and 100 load balancers—so you select in our case 10% of the infrastructure and when the change is validated you go on the next batch, etc.
This is quite convenient because I had some fun looking at, while doing this presentation, how many bumps we did for HAProxy or any other software, such as the kernel. We did almost 600 deployments over the past few years, which is quite huge. I was even surprised by this number. Why do we do that much deployment? Because our team is used to looking at the Git repository and once we see an interesting fix, which probably can be triggered on our site, we do a backport and we deploy it in a few hours. That’s something which is quite enjoyable because we can do lots of deployments every week.

This brings me to another story for the other side of the picture because, of course, our team creates a lot of incidents. I wanted to mention the maxconn. Willy told you about it this morning already, but let’s go back on what happened on our side. Basically, we were looking at the number of connections per process and we said, “Oh, now we should start to increase it because we are reaching a limit. So let’s double the number and deploy it”.
Everything seemed fine because HAProxy was not doing anything. We are simply doing very simple checks and after a while everything started to become strange. So, a few hours after you are ending up with a worldwide incident. As you probably already know, when you change the max connection, HAProxy is doing its own stuff in order to adapt the number of file descriptors you put on a given process, but if it fails to increase that number it rolls back the value to another value, which could be lower than the previous one you’d already set. That’s why in that kind of situation we don’t like HAProxy to take this kind of decision. That’s why we contributed recently, in order to introduce the strict-limits parameter and make sure that HAProxy is failing completely if it fails to increase this parameter, those limits.

Now, I wanted to talk about our probing system. At Criteo we have, let’s say, a given SLA for almost every service we have. We try to make it as simple as possible for every user in the company to make sure that someone coming can have a quick view of our infrastructure and have, more or less, an idea on if it’s going well or not. Here we are talking about only three metrics, which are latency, availability, and what we call provision delay. Provision delay is a process which is trying to add a new service, test it and remove it, and measure the time between the first and the last operation. It’s about what people do at Criteo a lot every day.
What is interesting for us here is it might sound like very simple metrics, but at the end we are quite proud of it because it allows us to trigger, I would say, 99% of our issues. I would say, also, that most of our bug reports we do for HAProxy are based, at the beginning, on those metrics. We bump a new version, we trigger something weird, and this is based on those metrics.

Another subject, which was already mentioned earlier today, was the logging. Of course, these are quite random subjects, but at Criteo we have, sometimes, lots of requests. Here at peak time on a given data center it was 2.5 millions requests per second. It’s enough for us to just take one request among 100 and it gives us a good idea of what’s going on with our traffic.

I won’t go too much into the details of that because we already mentioned that, but we are starting to use it more and more and we find it very pleasant because it allows you to take very accurate decisions on your production. I wanted to mention the trending topic about removing TLS 1.0 and 1.1 and that’s actually what we did a few days ago by looking at the TLS 1.1, which was under 1% of our traffic.

Okay, so now that our user seems to be happy and now that we also are happy to deploy with these safe mechanisms, we can start on our side to move everything without, hopefully, that the user notices it. Here, I will only mention, how does it integrate in our workflow? We don’t really focus on what’s the technology behind. Let’s start with, where do we come from? Historically, as mentioned by William at the beginning of the presentation, we came from very specialized infrastructure within specific racks in our network.
This is what I call here hyper-converged load balancing. Basically, the idea in this set up, historically when we started this initiative, was for the application to register itself, asking for here a layer 7 service to the network, wait for the control plane to locate the correct provisioner, and then ask this provisioner to configure the load balancing technology. Then you have a client, which is an end user, which is happy, can start making its DNS requests and the traffic flows this way.

Then, we started an initiative to support the layer 4 services, so we can think about SSH or DNS or whatever. We introduced a dedicated technology for that, IPVS, whatever you may want. It’s not really important in that case. You have the same workflow. An app can self register and ask for a layer of service, which is layer 4. The correct provisioner is located by our control plane; An event is sent and the traffic can start to flow the exact same way.
But now we have two different stacks. One of them can be completely replaced by commodity hardware and can be moved within our data center. It’s only a matter of having sufficient machines to handle the load because at layer 7 level, as you might know, there is an issue…I mean there is a lot of load that is consumed by handling TLS.

So, this is exactly what we did, but this way. We think that’s quite an elegant way to do that. Again, an app registers and is asking for layer 7, a provisioner is located and configured, but then you can redo exactly the same. I mean load balancers themselves can become clients of this system. So, the load balancers themselves, on behalf of an existing service, can ask the network to give a layer 4 service. This way we’ve introduced this kind of setup with specifics related to DSR and whatever. Again, I won’t go too much into detail, but we were clearly able to decorrelate and to despecialize stuff by reducing our own framework.

It went more and more powerful with time, meaning I can…sorry, forgot to mention that this is purely software again. There is an example here of our network device provisioner for our HAProxy network device provisioner. This is done in very simple steps. The first one is that you have to define your health checks for HAProxy this time. So, here the goal is to check that HAProxy has at least one server in the backend. Okay? You register specific metadata. HAProxy is asking for a layer 4 service to the network and then you register this into Consul. That’s done. So, very simple.

Now that we have this, we can go even further. We can redo the exact same thing on the layer 3 level, right? For example, the layer 4 load balancing can ask for a layer 3 service to the network and exactly the same: The control plane locates the proper switches, you know on top of racks, configures the peering session, and then you have a BGP session which is established. Also, you can imagine handling DDoS specifics or whatever you may need or think about. It’s only a matter of abstraction here, right?

Let’s continue; Same thing for GeoDNS, etc.

As a sum up, we moved from a hyper-converged service to commodity hardware and this by using, I would say, a pretty elegant service description framework. The consequence is that we’ve transitioned from something which was very specialized to a cost-efficient solution and with our load balancer becoming a plain server in our infrastructure. So, no more 100 Gig interfaces or whatever. Only plain servers, 10 gig interface and you scale horizontally.

Second topic: Edge PoPs. Again, I won’t really detail the schema, but the general idea for us and for every people that use this kind of solution is to optimize latencies. Historically at Criteo, we were deployed in facilities that were close to our partner for our business, but you can also think about improving the display time for your end user. For example, we display banners to people on the Internet and you probably want to be hosted in multiple places to have fast access to your infrastructure and to your services.
Just to mention here that this is very easy to do since HAProxy 2.0 thanks to the pool-purge-delay option, because it allows you to maintain a persistent connection pool between your Edge PoP and the origin server.

You can have really optimized latencies for your end users. As a recap, the goal for Edge PoPs was to reach large population bases and to keep our cost under control, right? Because it’s a matter of adding a few machines in a small rack somewhere and you end up optimizing a lot of user experiences.
Also, we had one concern, which was we probably want to do that progressively and gradually. For example, by deploying ourself in our on-premises in some location, but also to rely maybe on a cloud provider and to boot a VM and install HAProxy on it, but also maybe we could want to offload that on a cloud provider. We don’t want to be locked and we want, again, to be agile on that.

I will do exactly the same thing. Again, here the role of our control plane is to drive our Edge PoP configuration so that we can choose the appropriate method, we can shift from one provider to the other and the user is not supposed to suffer from everything. Everything should be transparent and on our side.

It brings me to a last point, which is still under study I would say, which is the value of data you can grab from HAProxy. It has been mentioned a lot, the logs on HAProxy are awesome, but they are so awesome that we started to like index the data and start what we could do with that, and only with the RTT value. It turns out that we will probably be able in the near future to do crazy stuff, meaning if I want to optimize my traffic engineering, like understand for one subnet on the Internet, which transit or peering I should use. Or maybe I can improve my GeoDNS database, right? Because sometimes you cannot locate your user and so maybe we can do the same on our side. We can do something on our side, sorry. At the end, what I wanted to mention here is that this is clearly becoming a decision-making tool and for our team, they are now already able to assess if a new data center location and a new topology is consistent or not. Only with this data.

This presentation, let’s say that it’s almost over in a way that we wanted to show you how we use our control plane, but let’s go back on a few feedbacks we had along those two years more related to HAProxy. As I mentioned before, we have lots of events on our infrastructure. Sometimes you are talking about a few events per second, which can be challenging at some times. So that’s why we try to make use, for sure as much as possible, of the API. When we cannot, of course, we do reloads.
One thing we would like to improve in the following HAProxy version is improving the metrics part. I’m especially talking about the counters. As you can see here in this graph, you can see some holes. Typically, in this case this was most likely some reloads, which were happening because of events from our developers or machines. So, this is something which is kind of something we would like to improve because sometimes our users are coming back to us and saying, “Oh, is there something wrong?” and of course everything is perfectly fine. That’s why this is something we would like to improve.

As you understood, we have a very high traffic generally speaking, but we are also latency sensitive. So, my point here is that even if we would like to make more machines into the API to load more and more things without reloading, it’s important for us to find a good middle point between adding more things in the API and never going back on the latency part, which is very important for us and that’s why we love HAProxy. I mentioned the facts about reloading is not acceptable if we lose packets, but that’s an issue which is fixed for a few years now.
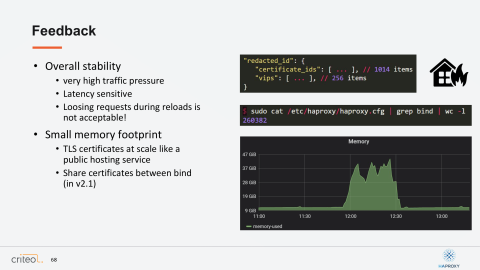
Now I wanted to talk about another subject about the memory footprint. We are overall very happy about the memory footprint, but it becomes a bit trickier when you are starting to use lots of TLS certificates. Here I put a few examples where you have a few thousands certificates possibly and you possibly also have a few, different IPs which are using the same certificates. Quickly, you can end up with very huge HAProxy configs with lots of bind lines. It can also be worse if you are using the CPU pinning on your configuration. Why? Because you probably know that already, but each new bind line in your HAProxy config with the TLS certificates loading will load a new object of your certificates. So that’s something which will be, as we saw in the other presentation, that this will be fixed in the 2.1. We are very happy about it.
What I wanted to highlight here is even if we do fix this issue, this is something which is very important for us because as you can see on the last graph with the memory, when we trigger lots of events it can be very challenging because suddenly the memory can go crazy. It’s very important for us in the future that we can make sure that each certificate is loaded just one single time, just because when you reload lots of times your process, it will create a new one with the new set of your certificates.

Let’s finish with something very positive. It might seem very normal to you and very straightforward that overall our experience those last few years was very good because we are so happy to be able to rely on the community and also on HAProxy Enterprise. So, a very simple example I’ve put here to finish is that we were using lots of TCP features and we triggered something about an issue related to Unix and it was fixed something like 20 hours before and backported in 2.0 and it was deployed two hours after. So, for me, it’s a good conclusion of our work in a way that, now, we are able to be so much [more] agile than before. We can spend much more time on more interesting things in our work. Thank you!