In this presentation, Eric Martinson describes how PlaceWise Digital utilized HAProxy Enterprise to gain observability over their network, improve performance, and secure their applications from threats. HAProxy’s metrics revealed that a large portion of their traffic was bots, which were sapping performance for legitimate customers. Eric leveraged several techniques for thwarting these bad bots, such as enabling the HAProxy Enterprise Antibot module and the HAProxy Enterprise WAF. He also succeeded in eliminating unplanned downtime, creating robust disaster recovery mechanisms, and offloading work from the development team.

Transcript
I’m going to discuss how a small company was able to really leverage HAProxy to get pretty massive improvements in both performance and stability for a pretty legacy platform.

Really would help to give a little bit of background on the company. PlaceWise has been in business for over 20 years. We service the mall or shopping center industry. You know if you ever go to a mall or shopping center website, that’s us.
We’re primarily in the United States. We own a pretty good chunk of the market in terms of an independent vendor that isn’t a real estate investment firm. We host about 40 to 50% of all shopping center websites or supply the content for them. We serve retailers and brands through our online platform that’s called RetailHub. It’s basically the place where anywhere from Gap and H&M to the mall operator themselves to the actual local stores can load their content and have it published across anyone that has access to our system.
I think one of the unique things about our environment is we act as both an agency and a platform, which adds a lot of complexity. On the agency side we’ll do web development, ad creative and publishing; We’ll manage content for clients and a lot of what the agency would do. On the platform side, we actually serve that up. So, in addition to RetailHub, we have our own custom web serving platform as well as an API. The API will feed any number of other clients either their websites or on-screen displays, touch screens and sometimes even apps. It kind of just depends on the use case, but in the grand scheme of things we sell data, right? We are a content provider. We sell data and run websites.

Some of the challenges: When I joined the company six years ago, we were already in business 15 years and we had used…It was a pretty exciting time where you’re gonna get a lot of opportunity thrown at you once you get to a certain scale in our industry, but really going after so many different markets was a strain on our end systems. We went after things like grocery and we had our own app and a lot of things that were just built onto a system that really wasn’t designed to scale or do anything different than just ones-y, twos-y updates.
What ended up happening is we had a legacy system that was incredibly single threaded and multi-tenant. You’d have a server that had not only one single threaded item on there, but another eight on there as well. So, any one of them could take down the rest of them and it was just kind of a cascade effect. It was pretty painful. It’s a Windows-based system, so reboots would just take an astronomically long time not just because of the legacy hardware we were on, but also because of our caching strategy at the time. A reboot would take over 20 minutes, which when you’re in the middle of troubleshooting is awful. The physical hardware was already dated, so we had to do something about that. We had no disaster recovery in place.
We were in the process of rebuilding a platform, one we are still in process of. Anybody who has a pretty massive infrastructure will know the pain of that. It’s not something you can just cut off and put new items in there. You have to take them out bit by bit.

A little bit about my background. It’s what it is, but I was bringing, really, kind of an enterprise mentality to what was kind of a little bit of a Wild West mentality at the company. With that, obviously, you have a different set of constraints.

At Sungard we deal with budgets of millions of dollars. United Healthcare doesn’t really care that you spent $4,000,000 on a data center that they’re not going to use. They also tend to build for scale right out of the box. You have a new project and you’re loading up, you know, multi instances of Oracle and 25 web servers just on the whim that it might scale. We also had large tech staffs. Obviously, with a smaller company you don’t have that and we’d have, at times, a pretty onerous change management process even to the effect that sometimes we’d have a two-week wait just to reboot a machine, which is pretty awful.
Going into PlaceWise, you know obviously, it’s a very small company. I had to reduce an already minimal budget. We were over paying for a lot of the stuff that was there. We really could only build when necessary. The infrastructure team, right here. Change what? Really kind of goes the mentality of a lot of startups and things. You know you just load this stuff up and go, right?

This is one of my favorite memes. I use it as a bludgeon if anybody crosses the rules. We have a good time with it.

Now the key question that I ask with anything that I’m doing within my environment is, what solution will limit or eliminate developer time? Because as an agency and a platform, we’ve got a lot of conflict there. Someone comes in and wants to pay us big bucks to develop something, a lot of times we have to answer. I have to really kind of manage that both on a management side and on a solutions side. So, I’m always looking at ways to circumvent having to have developers do the work.

What I’ve really come to rely on is HAProxy as a framework to program my network. I don’t look at it as a load balancer. I really look at it as a way to manage and control what’s on my network. Between the rules that are simple to the scripting that I just hack together to the plugins that I’ve been using lately and obviously security, it’s been a game changer for me because now I have just a ton more control.
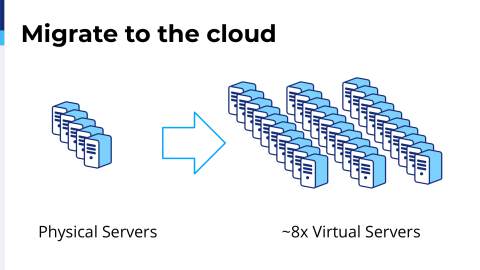
The first step in me getting to the point that we are today is something that is pretty basic to anybody who’s ever been on physical hardware. You will have done this at some point or another. It was to migrate, obviously, all of our servers from legacy hardware to the cloud. There’s nothing really unique on it. I think what is telling is the fact that we went from the physical servers, but we have 8 times the amount of virtual. It really shows how single threaded and how constrained we were.
This did drive some improvements, but it took a year to do even at our scale. We didn’t have the benefit of a large legal team, so we have contracts that we have to just basically wait out to be able to do this. When we were in this process is when I lucked upon HAProxy because I’d tried every other solution out there. It’s built into my firewall. I tried that. Didn’t work well. I tried a bunch of different projects, not great for what I needed to do. I was also looking at the cloud vendors’ load balancing solutions, but I also didn’t want to get tied again to another vendor, right? I want to be able to move data centers if I need to and take that configuration and move it somewhere else. HAProxy was really the best solution for me.
The thing that was really the kicker for me was just being able to have an agent on the local machine to circumvent some of the stuff that we needed to have done. I’ll kind of go into that configuration when we get there.

The other side of this that I didn’t have when I first got into place was any kind of real logging. Once I had HAProxy in place it was extremely helpful to have a logging solution. I was used to things like Splunk at Sungard. It was all great, but even at our small load we quickly got out of the free version and it got way too expensive quickly. So when I found ELK Stack, even though it was a little bit painful to put in place, it was pretty much a godsend for me because I finally had both the control and now the visibility for my network.

We had an internal joke. It became kind of like the two of them together is like a different kind of Marvel character. It’s the Incredible HELK Stack for us. All you Marvel nerds out there, you might enjoy that one.

Once we got it on there and actually started to look at the traffic that hit our network, it was pretty eye opening for me. Coming from a systems team, a lot of this stuff was already taken care of for me when I got to any of the systems I had to manage. Really, I was always just: How can I make my servers the most performant? I wasn’t really concerned much about security or bad actors on the network.
Here was a different story. We didn’t really know what was hitting us. We just had to kind of guess. When we got the logs it was pretty evident where a lot of our performance issue was coming from. 60% of our traffic was pretty much invisible to the tools we had before I put this solution in place, meaning it was all bots. If I had to guess today I think the legit traffic would be even lower, just as matter of course. It’s just too easy to put these things in place and I don’t know, there’s some perverse thing out there that people really want to go out and see if they can get access to your servers for no real reason.

Roughly 12% of that was really good bots that we wanted, search engines and some monitoring. Now, we’re a little bit unique in that we’re fairly locally specific in our SEO. We’re not really as concerned about the overall visibility of the sites. It’s more about local search. That being said, we’re still gonna do whatever we can do for the big search engines and there are others on there that we like to whitelist, but those are the big ones.
We’ve got that thing and it’s a balancing act. We still have the performance issues that we had before. It’s getting better because I’m starting to filter the bad traffic, but I still have an older caching strategy that I had to deal with.

Now, filtering the bot traffic, this is where I really got ingrained in the solutions given by the community. This was one that set me off in a pretty good direction where it was just a list of all of the bad bot strings, which was a great first step.

Other people have done this example as well. It’s pretty straightforward. I see that traffic come in; I put it into a stick table and I basically just bin bucket it.The one thing with these is that I wanted time amount for about half an hour because a lot of these bots, they will identify themselves once and then hide. They’ll start doing other kinds of agent strings and they won’t necessarily show up. So if you’re just blocking the agent string you’ll block one out of 300 packets. I wanted to get them to a way that I block them for a longer period of time and hopefully, eventually, they just let me go.
The other part of that is a lot of the search engines that we didn’t want, like Yandex and Baidu, we just don’t care about them. A lot of them don’t…they look at the robots.txt file. They just ignore it. I’ll see that traffic coming across as they make the request for them, but then they constantly just ignore it. So this was a good first step. In this I already have some other bad reqs that I get. People trying to do WordPress requests on my network, I know are already just scanners. There’s a lot of those out there, right? I immediately just tarpit those.

Once that was in place and we started to get some performance gains, I wanted to really decrease the recovery time we had on our network. I can’t change the hardware that it’s on. I can’t change a lot of the legacy stuff because it’s pretty well hard-coded to what we had. We still had fairly long reboot times. The reboot itself was quick, but the caching was still pretty long. We needed to warm up our servers and we had kind of hit a limit. Adding any kind of vertical scaling wasn’t working anymore. We’d hit a kind of a memory limit and then it would just kind of crater anyway.

I needed a different solution and this is where I started just playing with how am I going to manage the traffic on my network? How am I going to use it to do things that actually help me? Search engine traffic, that’s just load, right? Especially Bing. Bing is like 8% of our entire traffic load for a reason I have no idea why, but I wanted to use it.
So I started doing to my backup servers, and this is like one pod, we have multiple pods, but this would be like an example of one pod. I wanted to start using it to my advantage. I started taking the wanted bot traffic and now using it to warm up my backup servers. The effect of that was pretty significant for us. Now if we actually had an issue on our primary and it failed over, it was already warmed up and ready to go. Our downtime within that cutover basically went to zero. Since then, my team has re-architected the caching so that’s no longer a problem, but I still do this just from a system load perspective.

Once I started doing that I started looking at, well, these are servers identifying themselves as Google. I did this for Bing and all the others as well. Is it actually Google? It turns out 38% of them weren’t. They were just identifying them and it’s just a good excuse to say, “Oh, I’m Google. You’re just going to let me in.” So, I started just writing some very simple rules for that and, again, we’re starting to lop off all of this illegitimate traffic.

The next phase was really trying to cut the rest of some of the issues that I have out of the picture. We had already had some really big performance gains. Our cutovers were pretty much seamless, but the biggest time of year for us as a shopping network is Black Friday. We’re not doing e-commerce, but, you know, pretty much Thanksgiving afternoon in the United States, people are already starting to get antsy for Black Friday and we start hitting our spikes.
I wanted a couple of things. One was a good recovery solution, one that would be a lot more scalable because you just don’t really know in those load times what’s going to hit you. We’ve had years in the past where we got hit by just massive API requests, that kind of flat footed us. I wanted a way to take all of the remaining single points of failure, which is essentially our database, out of the picture. I also wanted to give me a better maintenance ability that was already kind of…I had already started with some of my other failovers.
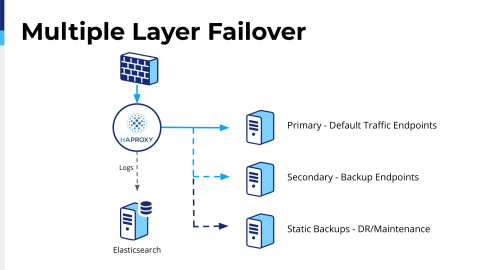
I was actively blocking. I started scraping all of my sites nightly. So now I had a situation where my third level of backup was a static copy of our sites. For the end user, it was great. As far as they’re concerned the site’s up and running. There are only a couple features that we’re still working on for a logged-in state, which has just a couple differences. This accomplished a couple things. One is now if my database took a complete dump, I could act as if the network was still up and no one would really know.
It was really, really helpful for us in this particular instance and with our failovers it’s amazing how automated this is so that when I get the alarm I’m not immediately trying to triage some issues with getting people online again. I’m trying to find the root cause. It’s been exceptionally helpful for us. We had this like two weeks ago and nobody knew it. All of the site’s back up and it’s a pretty scalable solution for us. As well as, I have scripts available on the different endpoints that I can push that for our developers. So, if the developers want to do something and they know they need to switch traffic, we can actually switch traffic to our static backups in pretty easy fashion.

The last thing I had on before I went to Enterprise was really the push to be SSL everywhere. We have about 2,000 SSL certs for our network. If you’ve ever managed manually any of this SSL stuff you would be…it’s just a nightmare to do. Luckily, Let’s Encrypt was really coming out of beta at the exact same time that we needed to implement it. There were no plugins, so the beauty of the platform that really, really made me fall in love with it is just the ability for me to integrate this with a few Bash scripts. Essentially, one line in the config file, point it to the directory where all these certs were, that was it. I mean I had 2,000 SSL certs within a few days up and running. It’s running today. I know they’ve come out with plugins since that automatically do a lot of the stuff I did, but really it was a few lines in Bash and we’re off to the races.

I had already gotten just a ton of value at this point and we had gone from a place where we were having quite a bit of outages when I had started to one where we were rock solid for an app that was pretty long in the tooth. This is just a graphic of the SSL.
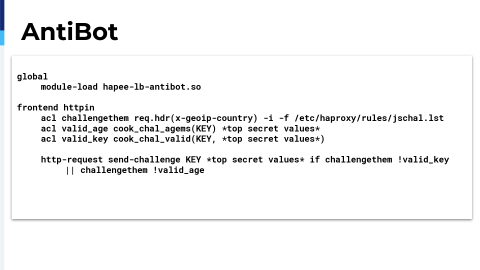
At that point I started talking to HAProxy about the enterprise version and I started to implement some of the features in there.
The first one I did, which, ironically, I was already in plans to create this myself with my dev team. I don’t know why. I don’t think I was reading that they actually had this in place. So, when I was on the phone with them, they were talking about this and I was ecstatic because I could immediately just lop off a lot of time of development to do this. It was drop dead simple to put in place. Other people have talked about it. It’s pretty amazing. I’ve made a couple mistakes when rolling it out where I actually put it on more people than I wanted to and the little loading thing is not ideal. So, I really only put it on traffic that I’m pretty suspect with, but this thing is amazing. It changes the game for a lot of this stuff.
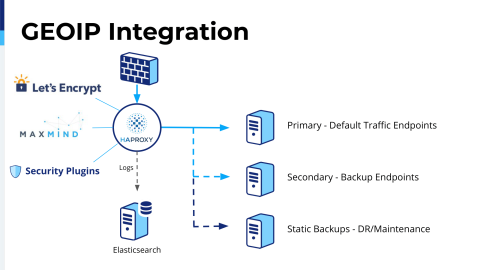
The next thing that I integrated was GeoIP. Using this was a huge help for us and I had been doing this manually with database updates for GeoIP.

Being able to just put this in a few lines in the config was, I mean it was just awesome because then I could start using this data to do a lot more traffic shaping. It’s actually coming up.

One of our next things that we had to deal with was GDPR, but it’s kind of limited for us as our network, our traffic, 0.7% comes from the EU. Our locations are in the US and Canada. It doesn’t really affect us. Although, today we have one EU client so this kind of changed, but when we put this in place we didn’t have to really comply to GDPR because we weren’t serving that market. But since our clients are mostly real estate investment trusts and mall operators, they are at a much bigger scale and their legal departments did want to be compliant.

So, what I ended up doing was taking the static backups as the source for anything coming from the EU and I basically stripped out all the tracking. GDPR light. Done! No developers needed and it was a very simple solution for us to be able to be compliant within days, actually hours. I could not get away with that here, but it was pretty good for what we had to do and it was really because of the ability to just implement this quickly that I was able to turn that around and, again, not use any developer time.

I’ve just been starting to play with the web application firewall. I’m about as a beginner as you can tell, but I’ve already seen some definite improvements from this and this is my next wave of things that I’m going to investigate because the shape of the traffic and the threats that are hitting you is not going to get any better. It’s going to get worse. You need to have that layer when you’re in a kind of environment that we’re in to be able to handle that.

I’m kind of talking to the right crowd, right? We all know about HAProxy and how easy it is to do a lot of pretty unique and amazing things.

There’s nothing there for you guys, but here’s where it really hit home for us. The reason it has helped really just change the game is our client load has doubled since we started this process, but our servers have not changed at all. In fact, our performance load has continually kept going down. We have to architect for Black Friday all the time, but that load ends up being not much more than a busy day now, which is pretty much a game changer for us.
We had down time when I first started, in the hours per month, mostly unplanned; and now maybe it’s minutes per month, planned. It’s just a complete 180. I have complete visibility over my network and control of it. It really informed the way I was able to do a disaster recovery solution and maintenance. To top it all off, I spend almost no time managing this. That my job is much bigger than the network, than the infrastructure. I’ve got all kinds of other things to do. I may spend 5% of my time on this, so the investment-to-payoff ratio is pretty big.

When I look at it, my biggest lever is time. I bought my team time to solve problems. I may be a little bit ahead of things when I do some solutions, but it’s to a business problem and I head off going to the development team. Improving performance, I was able to kind of mask some of the performance issues and give my team the time to fix them. It wasn’t an emergency. They could do it in the right ways. GDPR and DR, I solved those without actually doing anything with the team and I keep improving the security of our application.
It’s still legacy code and I’m always just paranoid what is going to hit it. We’ve got to keep updating that, but most significantly as we build out a new platform, I bought us years. We didn’t have to do any kind of emergency. We could do this in lock step. Now we’re at the time, like next year, we’re going to start rolling out a completely new platform and it’s on our schedule, not someone else’s. It’s really because of the tools we were having within HAProxy I was able to leverage to be able to do this.

The one thing that was difficult: I can still remember what it was like to fire up HAProxy for the first time. I had no clue about what I was doing. Whenever you’re doing that you obviously have some missteps. I think one of the things especially if they’re looking at some of the presenters we have today, they have these amazing solutions. The tendency is to have to think, “Oh, I need to use those or do those now”. But when you’re beginning, you don’t really have the ability to do that, especially as a small company.The benefit that I’ve had is I’ve been able to do this slowly over time. It’s not been one and done. I just started out with a few simple rules, figured out how it worked, and I just iterated, iterated, iterated. This is the exact platform to be able to do that.