In this presentation, Luke Seelenbinder, founder of Stadia Maps, describes the benefits his company received by building a custom Point of Presence (PoP) network using HAProxy. Their previous solution required placing authentication, authorization and quota enforcement into the backend applications. Also, failover was done at the DNS layer, which had a slow recovery time. By building a PoP network based on HAProxy, cross-cutting concerns like authentication, authorization, and rate limiting could be moved to the edge of the network. They increased their service reliability, gained observability over their traffic, and removed single points of failure.

Transcript
Good afternoon. I hope you all got some coffee and are ready for the last few sessions. I’m Luke Seelenbinder as he said, cofounder of Stadia Maps, and let’s start with a little bit of background about Stadia Maps.

We were founded in 2016 and we launched our public version in 2017. We’re a young company. We have two primary developers and a few contractors. We offer interactive and static map tiles for base maps, and we offer routing and geospatial data APIs.
We run about 50 servers in eight geographic regions and we service anywhere between 150 and 200 requests a second globally. So, as a very small team, our goal in infrastructure is to be able to deliver fast, affordable and very reliable location data services to all of our customers. Our customers are spread around the world so that means we need a solution that allows us to spread servers around the world so that all of our customers have good response time.

Before I get into what a PoP network is and how to use HAProxy for it, a little about our previous solution. Our previous solution was based on direct connections to our backend servers. So, we had servers spread around the globe. We used GeoDNS to resolve clients to the closest server that hosted the service they needed. If they needed maps, they went to the closest map server. If they needed routes, they went to the closest routing server.
All of our auth and statistics was baked into NGINX via nginxauthrequest. We had DNS failover. So, if one region went down their DNS record would eventually get updated to point to the next region. This comes with a few drawbacks, unfortunately.

That means if one client needs to talk to multiple of our services, they have to connect to multiple backend servers requiring multiple DNS connections, multiple TLS connections, and that just takes time and is complex from a client perspective. Every backend server has to know how to do everything a client request needs. If you need to do authentication, if you need to do authorization, if you need to do any kind of quota enforcement, all that lives on a backend server who really…that server only cares about doing one thing well.
And DNS-only failover. As we all know DNS TTLs are more of a suggestion than a hard and fast rule. So, if you set a 60 second TTL, you might have clients who have requests fail when a server goes down for a minute, for two minutes, for an hour, and that’s obviously a very bad solution.
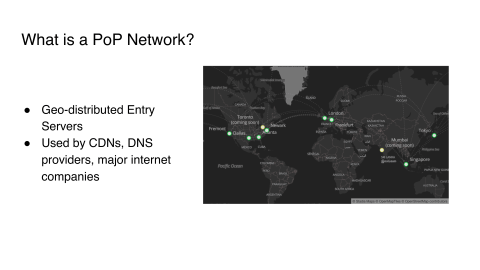
That brings me to point-of-presence networks. We’ve heard a lot about this already yesterday and today, but this is more how you can do a very simple version of it and a very cost effective version. Just a little bit about what a PoP network is, and the idea is that you have geo-distributed entry servers. You can have, as we have, eight entry points. These are very small servers that service all the traffic. All the DNS records point to a single server closest to the user and this is very frequently used by CDNs, by DNS providers and by pretty much any major Internet company. You have to build a point-of-presence edge network at some point.

Just a diagram how this works. You have your clients. They all talk to their nearest server. So, let’s say a client is in Dallas. One client is in Tokyo. Another client is in Amsterdam and they talk to Frankfurt, and then they all go back to your backend servers via some kind of discovery mechanism. As a comparison to the previous failover method we saw, let’s say that our map service in Newark goes down. Instead of a client seeing 500 errors or not getting a response at all because the server is down, those client requests go directly to a failover server. The client requests and connections were never severed and they have an overall much better experience because they never see a 500 error, and you’re able to deal with the problem.
Why would you want to build a PoP network? Originally, this talk was going to be more of a process of how we build it with HAProxy and a few other tools, but because I have a much shorter time period I’m just going to hopefully convince you why you need an edge network. Then in a few weeks, a blog post will be on the Stadia Maps website and possibly also the HAProxy website about more of the technical details.

What are the benefits of a PoP edge network? Well, I think you should build a PoP edge network for your clients because it reduces latency. As we all know, faster page loads means happier clients. If you’re an e-commerce site you know faster page loads means more sales. It increases connection stability; A client that’s closer to your edge server is going to have a more reliable connection in general than one that is farther away. Also, because of the way TCP works, most clients that have lower latency will have better download and upload speeds. This is especially important if you handle a lot of uploads such as video or other media. Having an edge server very close to your user will result in much better upload speeds in general.

It also increases service reliability. As I talked about before, it means that the edge server knows what backend servers are up and how to deal with that. It knows the backup servers as well. So, you get much faster failover, which, in turn, makes your clients happier because they’re not seeing the 500 errors. They’re seeing your service as it should be.

It also improves your control of the client experience. Let’s say, as we do, we have a map service and we have a routing service and they run on very different hardware. They need to have very different requirements. So, we can’t put this all on one server. If we have direct connections, as we had in the previous solution, that simply doesn’t work on the single hostname. By using a PoP network that means that you can integrate all of your services behind one hostname and that gives you a much better client experience because they only have to remember one hostname or do one DNS lookup. For integrations it’s much easier.
Also, a PoP network gives you the opportunity to prioritize user requests at the edge. Let’s say you have a commodity version of your product and an enterprise version. With an edge network, you can prioritize your enterprise version without…and that gives them much better, perhaps much better performance and you can meet your SLAs for your enterprise customers without too badly affecting your commodity traffic.
We also have the opportunity as we’ve seen in the last couple talks to block or deprioritize bad traffic or perhaps over-quota traffic. Each of our plans at Stadia Maps has a quota and when people go over the quota we don’t block them because that would be bad because then their users wouldn’t get maps; but we can implement rate limiting and, perhaps, make those requests a little bit slower so that we can maintain quality for our other customers, but not completely cut off that customer that was over quota.

So what about you? Why would you want to build a PoP network for yourself? Well, I like to think about it as it’s for your sanity. It allows you one central place that all the client requests come in so you can control all the flow of traffic using one relatively simple set of configuration. You can control deployment rollouts. If you’re using a green-blue deployment strategy, it’s very easy to with a PoP network. Say I want all my traffic to go from the first generation to the second generation at 15, 20, 30% as you roll out.
Also, with a global network, if you have a region that’s experiencing traffic loss or you have a, as we often have sometimes, a cache server will be performing very badly and we want the ability to reroute traffic from, say, London to Frankfurt to maintain quality; and having an edge network allows you to do that because you can dynamically say just don’t send any traffic to London and the client requests are automatically pushed to where they need to be.
You have one source of truth for your service state. Often, we ask the question: Is this server up? When you have just direct connections to the backend it is sometimes difficult to answer that question, but with HAProxy it’s much, much easier to just look at the Stats page as we all like to look at it and see what servers are actually up on the backend.

It also gives you a centralized place to do access control and logging, as we’ve heard also a lot about today. You can capture all the logs in one place. All the client requests flow through one place. So, you can then have one configuration to push it to, something like Elasticsearch or Grafana or something like that.
It also again gives you one centralized place to enforce your authentication and access control, and in our case we do a lot of quota enforcement. To improve your client experience, it’s also a great place to gather performance metrics because you’re right on the edge. You see exactly what your client sees in regards to your backend services.

The biggest reason we built a PoP network was to remove single points of failure. In our original solution if a backend server went down, we waited for DNS to propagate to the new server, but there were always clients that lost requests. With a PoP network that does not happen and typically these are set up so in a region you have at least two servers with some kind of IP level failover. That allows you to, as we’ve heard many times, to push traffic from one server to the other without clients ever knowing or perhaps, at worst, a TCP connection is dropped.

But why should we use HAProxy for this? That’s why you’re really here. So, the benefits of HAProxy in a PoP network: First, I think the configuration makes an enormous amount of difference. At the edge you want to control every bit about your traffic. We heard about how people were using ACLs to block bad traffic. We use ACLs extensively to manage the flow of requests through HAProxy and to what backend they end up on. We use ACLs to control all of our authorization and authentication. Every API key, every Referer header that we use, is on the edge.
We changed our authentication method that took sometimes up to a second because of network latency to being an instant process. Every single one of our requests is authenticated instantly. You add hitless reloads so you can change the configuration as much as you want and as long as you don’t have to deal with too many long lasting TCP connections, you have an uninterrupted experience for the client as you refresh your HAProxy configuration.
Then, for us, we use DNS SRV records for our service discovery. I looked at a lot of different options and HAProxy has one of the best integrated support for DNS SRV records, along with you can control everything from how often records are expired and how long you keep them if you can’t actually look up the service in the backend.

It also comes with active everything. If you have a PoP network, you wanna know what’s up so you know where to send the traffic and with active health checks you can know explicitly this server is up and this server is down. You also, as I mentioned, have DNS records. You control how fast it comes up.

For us, resource efficiency is key. We operate on a very small budget. We’re bootstrapped; We don’t have millions of dollars to spend on infrastructure. The fact that we can put HAProxy on the edge with one core and a few gigabytes of RAM and handle all of our traffic makes a big difference. We can’t use the HAProxy built-in cache, but if you are just hosting a relatively normal site with a lot of static assets, the fact that you can put an edge cache of CSS and JavaScript makes a big difference.
I think one of the biggest differences is the community that HAProxy offers. When we just pushed out our solution using HAProxy, our PoP network, we ran into an issue when we enabled HTTP/2. I didn’t know what was going on and I found the mailing list and I said I’m going to send a bug, say this is my problem. Within just a few hours I got a response from Willy and I think from a few other people saying, “We found a problem. We’re going to fix it.” The fact that, as an open source user of this product that I had just found a few months ago, getting a response like that is something I had not seen in the open source community. So, keep that up.

What was the success of rolling this out for us? As I said, we changed authentication, authorization and quote enforcement to entirely use map files and ACLs in HAProxy. That took us from a very slow process sometimes to always being instant. We never have to talk to our central database to make sure a client is authorized. We gain full visibility into all of our client experience. We know when errors happen; We know when client requests are slow; We know when timeouts are happening. That is not possible if you don’t have a central place to gather all of those statistics, or it’s very difficult to implement.
It’s also incredibly cost effective. We deployed our entire edge network with eight locations for $80 a month and this handles all of our traffic and it could handle much more. Our error rates during normal operation dropped to practically nothing. I don’t have good statistics from before we deployed the network, unfortunately, because we didn’t have a good way to gather them. When we upgraded from HAProxy 1.9 to HAProxy 2.0…so for those of you haven’t upgraded yet there’s something that’s very cool in that…we added layer 7 retries and, as you can see, this is an error graph over, actually, I think about a week.

Right there around three quarters of the way over is where we deployed HAProxy 2.0. Starting at 720 on the graph, going for multiple months, we had a period of no 500 errors returned to the client and that is because of the efficiency of HAProxy and the fact that we can do layer 7 retries across all of our servers. So, if you want to know more about the technical aspects, again, there will be a blog post with all the gory details, but that’s all I had for today. Thank you very much for listening.