HAProxy reached a significant milestone: the release of a new, major version, 2.0! Many changes have been stirring up the realm of high availability, including the rise of containerized and cloud-native applications, Kubernetes, and heightened awareness about security threats. The community has worked hard to add features that enhance HAProxy for even more use cases.
.jpg)
Transcript
Hello. Last year, approximately at the same period, we were finalising 1.9 and I stumbled upon a blog post from a guy who was comparing multiple load balancing proxies. They were NGINX, HAProxy, Envoy, Traefik, and there was a lack of scientific approach. His numbers were off by at least one order of magnitude compared to what anyone could expect, even from a very slow VM, but something struck me. HAProxy was showing the lowest latency and, despite this, it was showing exactly the same request rate as all other products, except Envoy which was slightly, or I mean, significantly above.
For me, it was obvious that the guy was hitting a packet rate limitation on his network during his test. He did not notice it, and Envoy uses a HTTP persistent connection by default which NGINX and HAProxy did not use because they have been facing I would say a more tricky server or interoperability issues and they did not enable this all by default, which explains the difference. So initially I thought that probably this guy did something wrong and he could not conduct a test correctly and that’s why it was not great. But, after this, I thought a little bit more and I said, well, when you compare four products like this you can barely assign more than one hour to each product, so it’s difficult to figure all the tricks you can do in a configuration to run an optimized setup with each product if you have only one hour per product.
So, in fact, as developers, we are used to have a lot of configuration files available. We constantly pick the closest file to our needs, we modify it a little bit and we run our tests with it, and that’s all. But in this case it was different and I suspected that this guy who was in the same situation as any user, any new user of HAProxy, probably experienced some issues that we completely forgot that existed, that have been existing for a while and we completely forgot them. So in order to run a test correctly, you have a lot of settings right now to set. You have the global maxconn. You have the frontend maxconn. You will have the number of threads which defaults to one. You will need to bind your listeners to various threads so that the load is properly spread. You need to explicitly specify the protocols if you want to use a HTTP/2, for example. You may want to enable HTTP re-use which was missing in this test, it was obvious. You may need to enable HTX if you need to connect to the back end of an HTTP tool, like in a GRPC test.
.png)
A usability benchmark
So, in fact, this guy faced, was really running a usability benchmark more than a performance benchmark and, in my opinion, we failed on this test. So, what could be done on this? In fact, in my opinion, the large number of features we support cannot be a valid excuse for having an increased complexity.
Better Usability in HAProxy 2.0
So in 2.0 we wanted to address all of these issues, so we have changed the way a number of default settings used to work for almost 18 years. The global ulimit is now set by default to what is allowed to the process. The maxconn is derived automatically from ulimit. The frontend maxconn is derived from the global maxconn. The number of threads is set to the number of threads available to the process. The listeners automatically are dispatching incoming connections to the least loaded threads. The protocols are automatically detected if you are using HTX. HTX is enabled by default.
By the way, for those who don’t know HTX, it’s a new internal structured representation of HTTP that we implemented in HAProxy which allows multiple versions of HTTP to coexist. So we have the same representation for HHTP/1, HTTP/2, or even FastCGI now. The benefit is that in order to modify some headers, we just have to modify one [unclear] instead of moving bytes back and forth when you modify multiple headers, and we have saved some performance for this. Back to this, we also enable HTTP re-use by default now in safe mode, which is fine with almost any server right now. We have enabled connection pooling to the servers. The server site protocol is already automatically detected and adjusted using ALPN.
Do you want to see the difference in terms of configuration? On the left, you have 1.9. On the right you have exactly the same configuration with 2.0.

Comparing 1.9 and 2.0
I guess I know which configuration you prefer and, in addition, the right one is slightly faster. It’s very, just slightly, but at least it’s a little bit faster.
Probably, as any complex conf, you probably did not notice that there is a typo on the left. The thread number was miscopied when duplicating the line and it was not properly replaced.
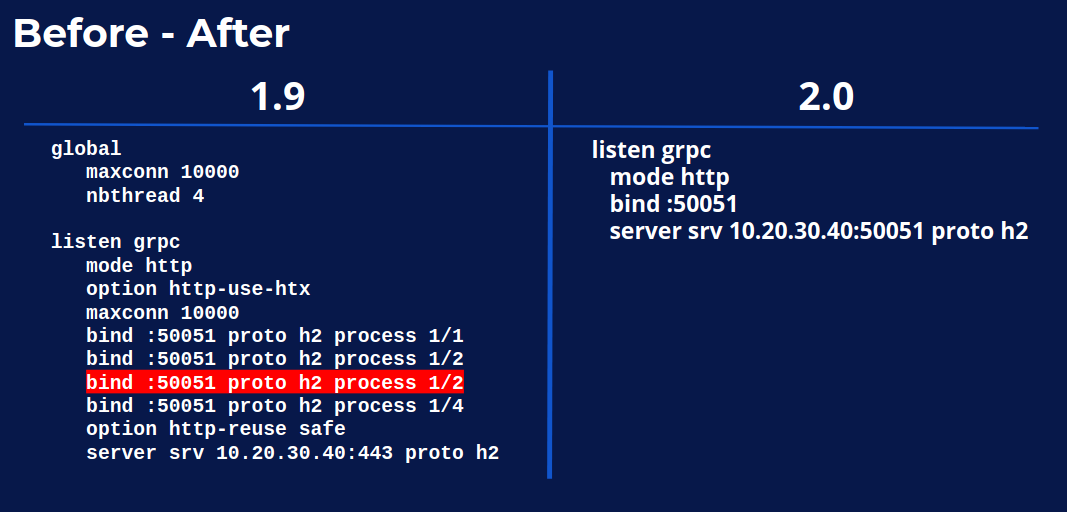
A typo in the configuration
So, in my opinion, we can say thanks to this example that with simplicity comes reliability. If we run the test again, my co-worker, Nick Ramirez, decided to rebuild all this test platform. And this time if he prepared the complete test suite that anyone can reproduce, he picked the configuration from the blog post and he picked HAProxy 2.0 directly from the Debian repository, the standard one. Out of the box, without doing anything, you notice that HAProxy is back to its place as being the highest performer that you see on the left side, the left graph.
And the lowest CPU and memory usage that you can see on the right, so it also means that simplicity brings you performance. It’s particularly important in container environments because in containers it’s often difficult to adjust your configuration to match the resources assigned to the container.
Cloud-native Logging
Sometimes the configurations are made once for all and you can’t modify them afterwards; it’s delicate. Many times we see that users instead put very high values on their settings, but it’s not the best way to have a reliable solution either. So here at least they will not have to modify their configuration; it will be correctly tuned by default. Speaking about containers, some people regularly complained about something else, which is logging.
The problem with logging is that HAProxy sends its log over a UDP socket and these users do not want to install a syslog server in their container for various reasons, some of them being that it’s not the way it should be done, and they prefer to simply retrieve the logs over STDOUT. It’s the right way to do it for them. So the problem I’m seeing is that STDOUT in fact is a pipe in this case and writing to a pipe causes a problem. Because when you send some data to a pipe and the pipe is almost full, what the system does is that it will simply pick the amount of data that fits in the pipe and will leave the rest outside. This results in twin catalogues, or you would have to have some extra buffers, etc, but in any case it adds some complexity. This was the reason why I systematically refused to implement logs on STDOUT on HAProxy from the beginning.
In fact, the problem really is that you cannot have an atomic write. But, recently I had another idea. There is another syscall which is “writev”, which is used to write a vector and the difference is subtle.

Simplified logging
A vector is a memory block which starts at the position and has a given length. Writev returns the number of vectors written, not the number of bytes. So I thought it must be atomic per vector. If I put my log message in a vector, maybe I can make sure that it is either entirely delivered or not at all. I ran the test and, yes, it does work. So right now we finally have logs on STDOUT thanks to this. It was just a small change, but we have this atomicity and the number of lost logs is simply accounted for; you have it in the stats. So thanks to this you don’t need any more to install a syslogd in your containers and that works out of the box. So we simply simplify your deployments.
Improvements in HAProxy 2.1
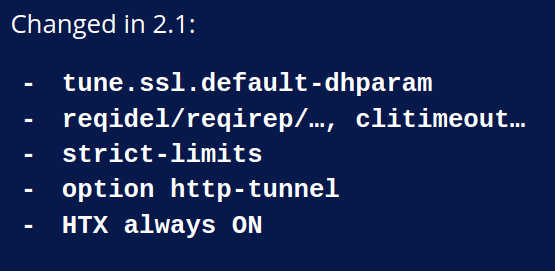
2.1 changes
Improvements in HAProxy 2.1
There are other simplifications that we did later in 2.1. One of them is default-dhparam . It has been sending a warning over the last five years suggesting to increase the value to have a more secure setup, but nobody really cared. So we changed it so that it does not warn anymore and instead it uses the default value from the SSL library. This way, it’s always secure. You may experience a slight performance loss on SSL. If this is the case, you just have to set it up to the old value and it will be okay.
We removed a number of obsolete and confusing keywords that came from version 1.0. They were not suitable anymore to HTTP/2. Some people were using them to insert headers by rewriting a specific header, adding a \n and another one. It was causing a real mess and breaking some connections sometimes, so we completely got rid of them. If you use them, you will get an error message which will tell you what to use instead.
We have something else; some users were bothered by the fact that when HAProxy cannot allocate enough file descriptors for your configuration, it emits a warning saying, I could not do this but I will run anyway. For developers, it’s nice because you don’t care, you just want to run a unit test and it’s okay. But for production, you restart your service, it goes up. Okay, you did not notice the warning, especially with systemd, so you did not notice the warning and when the load increases, suddenly it fails to accept new connections and the service is degraded. So the idea was to change this to turn it into an error, but I’m pretty sure that there are a lot of setups deployed in this situation right now. Instead of breaking existing setups, we have now a new keyword, strict-limits, which when enabled will turn the warning into an error, a fatal error. Otherwise, it will remain a warning and it will tell you that it will become by default in 2.3.
We removed the option http-tunnel. It was a leftover from 1.3 to ease the transition between 1.3 and 1.4 and it is the same. People were using it as a hack for various bad reasons and when you use HTTP/2 and HTTP/1, they don’t cope well. When you send some extra requests as a data part of a second HTTP request, it causes a problem. HTX is always on. We removed all the bogus legacy and tricky code and it was inefficient. It was causing us grey hair trying to figure out how to fix some issues, so we completely got rid of it now. In addition, I would say that we have added a lot of bugs. It was not intentional, not completely at least. We added a lot of bugs in 1.8 and 1.9, mainly because of threads, because of the I/O work, because of HTX. There were a huge number of changes.
Native Protocol Tracing
We noticed that for a lot of users who are experiencing issues it was very difficult to know if what they were seeing was a bug, was a misunderstanding on their part, that they maybe missed something in the documentation, so we needed to improve the ability to debug.

Simplicity == Observability
So in order to simplify the debugging, we started with something easy recently. A guy called Beorn presented a talk at Kernel Recipes a few weeks ago and he explained how terrible it is to have to read the man page at 3AM just to figure the meaning of a stats indicator, and I figured that this guy was absolutely right and we were not good at this. So I added recently one line, a one-line description to each and every stats indicator. So now, when you consult your stats, you can run a show stats desc, you will see the description, what it relates to, its unit maybe, or some possible values, if negative values have a special meaning, for example. At least it will tell you if you are looking at the right metric or not. We are sending a copy of the warnings on the CLI because, as I explained, people miss the warnings a lot these days.
We needed to find a way to expose them again, so on the CLI now you can type show warnings and you will see the start-up warnings. We can have the logs on the CLI as well. We implemented some ring buffers. You just have to specify your ring in the logs directive and on the CLI you will be able to show them in real time.
We have implemented a tracing system. The problem we had was that for certain complex issues we had to enable traces by rebuilding HAProxy with specific options. These options were extremely slow and they were not particularly well detailed, nor maintained, so instead we decided to implement traces as a standard feature. So now traces can be enabled any time on the fly, you can enable them on a specific event only if needed and let them stop on another type of event, and you can consult them on the CLI.
You have multiple verbosity levels, so it’s even possible to use them just as a way to just show what request enters and what response leaves, for example. They are extremely convenient. Right now they are only for HTTP/1, HTTP/2 and FastCGI, but they are expanding.
Improved Debugging Tools
We wanted to improve the ability to get a core dump. Some users were seeing some bugs from time to time and they said HAProxy crashed.
Okay, can you give me the core? No, unfortunately I have no core. Every time we explained, so you need to disable the chroot, you need to comment out the setuid, etc, a large number of settings to modify in the configuration, and on average it required three to four attempts before the core was properly dumped. It’s a problem because when issues happen once a week, it can require one full month to get your core dump.
So we decided to address this differently by adding a new option to make the process dump-able again. So without modifying your security feature, you can simply say, I want to have my core dumped, and it will work. There was another feature which was restricted to developers only, which is a debug dev on the CLI which allows you to inspect some memory areas in the process, to decode some blocks as a stream or whatever internal structure, even to kill the process, or to make it core dump, or whatever.
We figured that some users are so advanced that they would benefit from this, so instead of requiring a specific build option, now it is available by default on the CLI. However, it is only shown when you enter expert mode so that it’s not too much disturbing. Don’t use this if you don’t know what it’s about because you will likely crash your process.
The peers are an interesting beast. For many years, everyone considered that the peers were working okay because they did not provide any log. Obviously it was not the case. We had to troubleshoot some issues recently. I insisted so that we had logs and some debugging options, so now we have logs when peers reconnect. We have a show peers command which shows their internal state, how long they have been connected, the number of messages or errors, or I don’t know what exactly. Surprisingly, we found a number of bugs thanks to this, so I would say that the peers work much better right now.
We can also access all the workers after a reload directly from the master process socket. This was a problem for people who reload often. Sometimes they want to access the old process stats because it uses long connections. Sometimes they want to connect to an old process because they don’t understand why it’s not stopping and they want to see if it has a bug or whatever. Sometimes they just want to connect to it to make it to force to quit, for example, and it was inconvenient. You had to pre-connect to the socket before sending the reload. It was not convenient. Now you connect to the server, it forwards automatically your connection to the process you want. So I think that we have significantly improved the observability overall of HAProxy by keeping things simple.
Packages and Distros
Now we still have some corner cases. Some people sometimes report issues with their HAProxy and we figure that they are running an old version. When we ask them to update, they happily do it, so it means that it’s not that they refuse to update, they just don’t know they are not up to date. That’s a problem because it also affects their reliability. They are running with known bugs and it’s a real problem. How can they trust their HAProxy process if they don’t even know if it’s up to date and what is running?
So we tried to identify the various causes of the fact that we cannot possibly trust a process running in production. One of them is a package origin. I mean that many users deploy HAProxy because it’s shipped with their distro. The problem is that most distros have a policy of not applying fixes at all. If it’s not explicitly written that it fixes a security vulnerability, they don’t apply the fix. I completely disagree with this because when you have an edge device like a load balancer, many bugs are far more critical than any stupid vulnerability. Anyway, it’s the policy.
I don’t want to blame them completely because I would say that a lot of software do not provide maintenance branches and it’s not necessarily easy to follow updates without breaking anything. Mostly infrastructure components in fact, and those with a very slow development cycle, tend to provide maintenance branches. In Debian and Ubuntu, Vincent Bernat, who is the package maintainer, found a nice way to work around this issue by providing his own packages. Since he’s the official maintainer of the package, you must trust him. This means that if you are using this distro, you must use his packages and not the default one shipped by the distro. For other distros we are still discussing the various possibilities to try to address this problem, but we really want to find a nice way to address this once and for all because, in my opinion, it’s not acceptable to see that people are running the wrong version just because fixes are not delivered. So there is still room for improvement here.
Version Release Cycle
Another point is the branch stability. In fact, we love to implement some bleeding edge code and to see it deployed in field and to collect feedback from advanced users, but when these users run a pre-release or a development version, they can’t have bug fixes. So recently we decided to address this problem by changing the development cycle. So now we have two releases per year, one at the end of the year which ends with an odd digit on the second number which is mostly a technical release. It contains some risky fixes. It’s not for everyone and it’s purposely not maintained long; I would say between one year and one year and a half.
Another version is issued in the middle of the year with an even number. This one keeps on the regular maintenance cycle and it only contains I would say improvements, nice features, or whatever, but nothing really risky. So this helped us a lot because we collect a lot of bug reports at the beginning of the year which are well detailed because usually they come from very advanced users. These users don’t see this as a big problem because they are autonomous enough to be able to roll back and to work around the problem by themselves. We can afford to backport some complicated fixes because we know that even if we break this version a little bit during its maintenance cycle, it’s not dramatic, so it’s a win-win. Some users can benefit from bleeding edge features and we benefit from early feedback.
And, in addition, all users benefit from much stabler versions. The problem we discovered recently was that users don’t know the release cycles and that’s normal. If I asked you for what software what is the release cycle, you don’t know. We figured recently that some users were running with 1.9 not even knowing that it was a little bit tricky and not knowing that its maintenance will end soon. So the idea was very simple, it was to add this status, this branch status in haproxy -v so that when the checks are released it’s mentioned in it that it’s not for everyone and that its maintenance will end soon. So I consider that it’s almost done, we will do it before 2.1 is released, and it will be backported to older versions.
The version status itself is another problem. Users don’t know if they are running the latest version of their branch, even if they are on the right branch. It’s not easy to address this. However, there is a page on HAProxy.org which is called bugs I think. It lists the known bugs per version, so we will add a link to this page for the specific version so that users will be able to copy paste this link and list all the bugs that affect their version and see if a new version is available in this branch. So it’s trivial and I consider that it’s almost done as well.
Code Quality and Testing
Code quality is another matter. The code has become more complex and since I would say approximately 1.8 nobody knows the whole codebase anymore, so that’s really a distributed project but it causes a problem, because when you develop in your area, sometimes you break someone else’s code and it’s not acceptable. So we adopted a tool called V-test which comes from the Varnish cache project. It’s a regression testing suite. It’s specially made for testing proxies. It can emulate client servers and logs and whatever. We have implemented something like approximately 50 tests I think. They are run all the time by the developers and we avoid a lot of bugs thanks to this, because very frequently we see that we broke something we did not even know existed so we can fix it before committing, so that’s a nice improvement.
Another one is that we adopted TravisCI and CirrusCI to run tests on the various operating systems and libraries. That’s how we discover that we regularly break a libreSSL, for example, or that OSX does not build anymore. So this happens after the commit, but it’s very quick to fix because you still have your code in mind and you know what to do to fix this. In addition, it also runs the V-test so we can see the behavior of this test on all platforms. We now have an issue tracker on GitHub so that the bugs can be shared with anyone and anyone can participate and add some extra information to refine a bug report.
What else can I say? In my opinion, it’s still not sufficient because it’s still too easy to add new bugs to the code. The internal API is still not very clean. We are still lacking internal documentation, so we definitely need to improve this. And with this said, I think that the total bug count has increased per version during the last releases. However, the total number of bugs per feature has decreased, so that’s already an improvement and for me it means that the code remains completely trustable today.
Detecting Deadlocks and Infinite Loops
Another point which concerns the process trustability is the fact that for a very long time everyone used to simply monitor the presence of the HAProxy process to consider that everything was okay. As we have seen with 1.8 and 1.9, we broke this assumption because we created a new class of bugs which were deadlocks, which are common with threads, and spinning loops which were common with IO changes which were very tricky, and sometimes we enter spinning loops that we cannot leave.
So, in my opinion, it’s not acceptable. There is nothing worse than having a process present on your system, eating resources and doing nothing. It will fool any monitoring system. So we decided to get rid of this the hard way. We have implemented strict integrity checks in the system and we have a mandatory watchdog which will crash your process if it detects a deadlock. We have a mandatory loop prevention system which will crack the system if it detects that your system has entered a mad loop. There are in addition a few other mechanisms, like detecting use after free and whatever, but these ones are optional because they are very, very slow. With this said, we caught a huge number of bugs thanks to them.
A lot of the early reports we collected from 2.0 on GitHub were all traces from the watchdog, so I was very happy that it was there because it helps a lot to know exactly what’s happening. To give you an idea, HAProxy.org is running with all of these features enabled and till now it never crashed, so I’m pretty confident that it significantly improved the process trustability.
Where Next?
So we are back to the old principles that if the HAProxy process is present, it means that the service is properly delivered. What are the next directions?

Next directions
We want to make the code more reliable. This means cleaning the internal API. We want to make the lower layers less visible from developers. Today, when you have to contribute, you copy paste some code from other areas. When I ask, “Why did you copy this flag?”
“I don’t know, it was there.”
So maybe this flag should not even be exposed at all. We need to ease the access for new contributors and that’s again better internal documentation. It’s still difficult to know how to use a connection stream or whatever. We need to improve this. We also need to ease access to new users on the packaging point that I mentioned and on config generators, for example. We had ideas on this to simplify the first configuration. HAProxy used to be made for experts only in the past. Some people were proud to say, I’m using HAProxy, so it meant that you were an expert. I think we managed to significantly shorten the learning curve so that even beginners can save time by trying it right now, even if they never tried a load balancer. So, in my opinion, we are giving novices an easier access to HAProxy’s full power.
That was visible in the slide where I showed the difference between 1.9 and 2.0. In parallel, we have improved the reliability and we provide better access to the internals for advanced users. We save more time on incidents, so I think that we are giving experts more control and that they can better cut costs and operation costs I mean thanks to this.
So, in my opinion, now we have simplified both expert and novices’ life with the recent versions. In this conference you will see a number of talks from experts who all started, like many of us, as novices. I really encourage you to listen carefully to them because they will share what they learned to become experts, and very likely maybe next year you will be there presenting at their place.
Thank you. Have a great conference.