Enterprise modules
Global Profiling Engine
The Global Profiling Engine collects stick table data from all HAProxy Enterprise nodes in a cluster. It can perform calculations on both current and historical data before pushing the data back to the load balancers, giving them all a comprehensive and up-to-date view of client behavior across the cluster.
For example, in an active-active load balancer configuration where traffic is relayed to two or more load balancers in a round-robin rotation, the GPE ensures that each load balancer receives the sum of requests that a client has made, even when some of those requests were routed to the other load balancer.
It calculates statistics for current, real-time traffic, which you can use to take action based on an immediate threat, such as a web scraper. It also calculates historical statistics, which you can use to make decisions based on traffic trends from the past. For example, you can factor in the request rate at the 90th percentile from yesterday.
The Global Profiling Engine should be installed on a separate server from your HAProxy Enterprise nodes, from where it can collect and aggregate data from stick tables from across your load balancer cluster.
When would you use the profiling engine? The table below outlines various, common ways to set up your load-balancing cluster and explains which benefit from using the Global Profiling Engine:
Standalone load balancer
If you operate a single HAProxy Enterprise node, collecting data with stick tables can help improve security and observability by monitoring client activity in real time. However, you do not need to use the Global Profiling Engine because there aren’t multiple load balancers collecting data that needs to be aggregated, unless you want to use its historical aggregations feature.
Active-standby cluster
In an active-standby cluster, you operate two HAProxy Enterprise nodes as peers, with one peer actively receiving traffic while the other is on standby. If you define a peers section in your configuration, then the stick tables of the active node are propagated to the passive node, where they overwrite existing values. Overwriting would be bad if both peers were receiving traffic and collecting data, but in an active-passive scenario, it’s perfectly fine. The metrics stay accurate on all nodes. In this case, you do not need the Global Profiling Engine, which aggregates data from multiple, active peers, unless you want to use its historical aggregations feature.
Active-active cluster with Global Profiling Engine
In an active-active cluster, you operate two HAProxy Enterprise nodes as peers, with both receiving traffic at the same time. To ensure that stick table counters are accurate cluster-wide, you need the Global Profiling Engine, which runs on a separate server, collecting stick table data from both peers and aggregating it. Once aggregated, the data is sent back to the peers so that they can make decisions based on it.
Installation Jump to heading
The following section gives detailed information on how to install the Global Profiling Engine.
-
Provision a server on which you will install the Global Profiling Engine.
-
On the new server, add package repositories for your operating system.
In a terminal window, set a variable named
keyto your HAProxy Enterprise license key.nixkey=<HAProxy Enterprise Key>nixkey=<HAProxy Enterprise Key>Then use the
echoandteecommands to add the HAProxy Technologies extras repository location into the file/etc/apt/sources.list.d/haproxy-tech.list, as shown below.nixecho "deb [arch=amd64] https://www.haproxy.com/download/hapee/key/${key}-plus/extras/debian-$(. /etc/os-release && echo "$VERSION_CODENAME")/amd64/ $(. /etc/os-release && echo "$VERSION_CODENAME") main" | sudo tee -a /etc/apt/sources.list.d/haproxy-tech.listnixecho "deb [arch=amd64] https://www.haproxy.com/download/hapee/key/${key}-plus/extras/debian-$(. /etc/os-release && echo "$VERSION_CODENAME")/amd64/ $(. /etc/os-release && echo "$VERSION_CODENAME") main" | sudo tee -a /etc/apt/sources.list.d/haproxy-tech.listIn a terminal window, set a variable named
keyto your HAProxy Enterprise license key.nixkey=<HAProxy Enterprise Key>nixkey=<HAProxy Enterprise Key>Then use the
echoandteecommands to add the HAProxy Technologies extras repository location into the file/etc/apt/sources.list.d/haproxy-tech.list, as shown below.nixecho "deb [arch=amd64] https://www.haproxy.com/download/hapee/key/${key}-plus/extras/ubuntu-$(. /etc/os-release && echo "$VERSION_CODENAME")/amd64/ $(. /etc/os-release && echo "$VERSION_CODENAME") main" | sudo tee -a /etc/apt/sources.list.d/haproxy-tech.listnixecho "deb [arch=amd64] https://www.haproxy.com/download/hapee/key/${key}-plus/extras/ubuntu-$(. /etc/os-release && echo "$VERSION_CODENAME")/amd64/ $(. /etc/os-release && echo "$VERSION_CODENAME") main" | sudo tee -a /etc/apt/sources.list.d/haproxy-tech.listCreate a new file
/etc/yum.repos.d/haproxy-tech.repoif it does not exist and add the contents below. Replace<HAProxy Enterprise Key>with the key you were given when you registered. Also replacerhel-8with your RHEL version number.haproxy-tech.repoini[hapee-plus-extras]name=hapee-plus-extrasenabled=1baseurl=https://www.haproxy.com/download/hapee/key/<HAProxy Enterprise Key>-plus/extras/rhel-8/$basearch/bin/gpgcheck=1haproxy-tech.repoini[hapee-plus-extras]name=hapee-plus-extrasenabled=1baseurl=https://www.haproxy.com/download/hapee/key/<HAProxy Enterprise Key>-plus/extras/rhel-8/$basearch/bin/gpgcheck=1 -
Install packages:
nixsudo apt-get install --yes apt-transport-https curl dirmngr gnupg-agent grepwget -O - https://pks.haproxy.com/linux/enterprise/HAPEE-key-extras.asc | sudo apt-key add -sudo apt-get updatesudo apt-get install --yes hapee-extras-gpenixsudo apt-get install --yes apt-transport-https curl dirmngr gnupg-agent grepwget -O - https://pks.haproxy.com/linux/enterprise/HAPEE-key-extras.asc | sudo apt-key add -sudo apt-get updatesudo apt-get install --yes hapee-extras-gpenixsudo apt-get install --yes apt-transport-https curl dirmngr gnupg-agent grepwget -O - https://pks.haproxy.com/linux/enterprise/HAPEE-key-extras.asc | sudo apt-key add -sudo apt-get updatesudo apt-get install --yes hapee-extras-gpenixsudo apt-get install --yes apt-transport-https curl dirmngr gnupg-agent grepwget -O - https://pks.haproxy.com/linux/enterprise/HAPEE-key-extras.asc | sudo apt-key add -sudo apt-get updatesudo apt-get install --yes hapee-extras-gpenixrpm --import https://pks.haproxy.com/linux/enterprise/HAPEE-key-extras.ascyum makecacheyum install -y hapee-extras-gpenixrpm --import https://pks.haproxy.com/linux/enterprise/HAPEE-key-extras.ascyum makecacheyum install -y hapee-extras-gpe -
To start the Global Profiling Engine, run:
nixsudo systemctl enable hapee-extras-gpesudo systemctl start hapee-extras-gpenixsudo systemctl enable hapee-extras-gpesudo systemctl start hapee-extras-gpe
Manage the service Jump to heading
Start, stop and check the status of the Global Profiling Engine service by using the corresponding systemctl commands.
Start the service:
nix
nix
Restart the service:
nix
nix
Show current status:
nix
nix
Stop the service:
nix
nix
Real-time aggregation Jump to heading
The Global Profiling Engine collects stick table data from all HAProxy Enterprise nodes in the cluster in real time. It then aggregates that data and pushes it back to all of the nodes. For example, if LoadBalancer1 receives two requests and LoadBalancer2 receives three requests, the Global Profiling Engine will sum those numbers to get a total of five, then push that to both LoadBalancer1 and LoadBalancer2. This is helpful for an active/active load balancer configuration wherein the nodes need to share client request information to form an accurate picture of activity across the cluster.
The aggregated data does not overwrite the data on the load balancer nodes. Instead, it is pushed to secondary stick tables that have, for example, a suffix of .aggregate. You would use a fetch method to retrieve the aggregated data and perform an action, such as rate limiting.
Stick table data is transferred between the HAProxy Enterprise servers and the Global Profiling Engine server by using the peers protocol, a protocol created specifically for this purpose. You must configure which servers should participate, both on the Global Profiling Engine server and on each HAProxy Enterprise node.
Configure HAProxy Enterprise nodes Jump to heading
An HAProxy Enterprise node must be configured to share its stick table data with the Global Profiling Engine server. Once aggregated, the profiling engine sends the data back to each node where it is stored in a new stick table. Follow these steps on each load balancer:
-
Edit the file
/etc/hapee-2.8/hapee-lb.cfg.Add a
peerssection.hapee-lb.cfghaproxyglobal# By setting this, you tell HAProxy Enterprise to use the server line# that specifies this name as the local node.localpeer enterprise1peers mypeersbind 0.0.0.0:10000# the local HAProxy Enterprise node# name should match the server's hostname or the 'localpeer' valueserver enterprise1# The Global Profiling Engine# If you run GPE on the same server, use a different port hereserver gpe 192.168.50.40:10000# stick tables definitionstable request_rates type ip size 100k expire 30s store http_req_rate(10s)table request_rates.aggregate type ip size 100k expire 30s store http_req_rate(10s)hapee-lb.cfghaproxyglobal# By setting this, you tell HAProxy Enterprise to use the server line# that specifies this name as the local node.localpeer enterprise1peers mypeersbind 0.0.0.0:10000# the local HAProxy Enterprise node# name should match the server's hostname or the 'localpeer' valueserver enterprise1# The Global Profiling Engine# If you run GPE on the same server, use a different port hereserver gpe 192.168.50.40:10000# stick tables definitionstable request_rates type ip size 100k expire 30s store http_req_rate(10s)table request_rates.aggregate type ip size 100k expire 30s store http_req_rate(10s)Inside it:
-
Define a
bindline to set the IP address and port at which this node should receive data back from the Global Profiling Engine server. The server name value is important because it must match the name you set in the Global Profiling Engine server’s configuration for the correspondingpeerline. In this example, thebinddirective listens on all IP addresses at port 10000 and receives aggregated data. -
Define a
serverline for the current server. Ensure the host name matches the name determined by one of the following methods, in order of precedence:- the
-Largument specified in the command line used to start the load balancer process; - the
localpeername specified in theglobalsection of the load balancer configuration; or - the host name returned by the system
hostnamecommand. Method 3 is the default, but the other methods are recommended instead.
In this example, the local HAProxy Enterprise node is listed with only its hostname,
enterprise1. It is not necessary to specify its IP address and port. - the
-
Define a
serverline for the Global Profiling Engine server. Set its IP address and port. The name you set here is also important. It must match the correspondingpeerline in the Global Profiling Engine server’s configuration. -
Define stick tables. For each one, add a duplicate line where the table name has the suffix
.aggregate. In this example, the non-aggregated stick tablerequest_rateswill store current HTTP request rates. The stick tables record the rate at which clients make requests over 10 seconds. We clear out stale records after 30 seconds by setting theexpireparameter on the stick table. Thetypeparameter sets the key for the table, which in this case is an IP address. The stick tablerequest_rates.aggregatereceives its data from the Global Profiling Engine. Its suffix,.aggregate, will match the the profiling engine’s configuration.
-
-
Add directives to your frontend, backend or listen sections that populate the non-aggregated stick tables with data.
Below, the
http-request track-sc0line adds request rate information for each client that connects to the load balancer, using the client’s source IP address (src) as the key in the stick table.hapee-lb.cfghaproxyfrontend fe_mainbind :80default_backend webservers# add records to the stick table using the client's# source IP address as the table keyhttp-request track-sc0 src table mypeers/request_rateshapee-lb.cfghaproxyfrontend fe_mainbind :80default_backend webservers# add records to the stick table using the client's# source IP address as the table keyhttp-request track-sc0 src table mypeers/request_rates -
Add directives that read the aggregated data returned from the Global Profiling Engine server. That data is stored in the table with the suffix
.aggregate.Below, the
http-request denyline rejects clients that have a request rate greater than 1000. The client’s request rate is an aggregate amount calculated from all active load balancers. Note that this line reads data from therequest_rates.aggregatetable.hapee-lb.cfghaproxy# perform actions like rate limitinghttp-request deny deny_status 429 if { sc_http_req_rate(0,mypeers/request_rates.aggregate) gt 1000 }hapee-lb.cfghaproxy# perform actions like rate limitinghttp-request deny deny_status 429 if { sc_http_req_rate(0,mypeers/request_rates.aggregate) gt 1000 } -
Restart HAProxy Enterprise.
nixsudo systemctl restart hapee-2.8-lbnixsudo systemctl restart hapee-2.8-lb
Configure the Global Profiling Engine Jump to heading
The Global Profiling Engine server collects stick table data from HAProxy Enterprise load balancers in your cluster, but you must set which load balancers will be allowed to participate by listing them in the configuration file.
-
On the Global Profiling Engine server, edit the file
/etc/hapee-extras/hapee-gpe-stktagg.cfg.In the
aggregationssection, add apeerline for the Global Profiling Engine itself and for each HAProxy Enterprise node. Each peer’s name (e.g.enterprise1) should match the name you set in the HAProxy Enterprise configuration, since that is how the profiling engine validates the peer.hapee-gpe-stktagg.cfghaproxyglobal# Enables the Global Profiling Engine APIstats socket /var/run/hapee-extras/gpe-api.sockaggregations data# set how to map non-aggregated to aggregated stick tablesfrom any to .aggregate# the profiling engine listens at this addresspeer gpe 0.0.0.0:10000 local# the load balancers listen at these addressespeer enterprise1 192.168.50.41:10000peer enterprise2 192.168.50.42:10000hapee-gpe-stktagg.cfghaproxyglobal# Enables the Global Profiling Engine APIstats socket /var/run/hapee-extras/gpe-api.sockaggregations data# set how to map non-aggregated to aggregated stick tablesfrom any to .aggregate# the profiling engine listens at this addresspeer gpe 0.0.0.0:10000 local# the load balancers listen at these addressespeer enterprise1 192.168.50.41:10000peer enterprise2 192.168.50.42:10000In this example:
-
The Global Profiling Engine API provides a programmable API, which listens at the socket
/var/run/hapee-extras/gpe-api.sock. Thestats socketdirective enables a CLI that lets you view data that the aggregator has stored. -
In the
aggregationssection, thefromline defines how non-aggregated stick tables map to aggregated stick tables, and what the suffix for the aggregated stick tables should be. The keywordanymeans that any stick table found will be aggregated. Aggregated data is pushed to tables with the same name, but ending with the suffix.aggregate. In the example, the engine expects stick tables to be named likerequest_ratesand it will push aggregated data torequest_rates.aggregate.You can also use a more specific mapping. In the example below, the engine expects stick tables to be named like
request_rates.nonaggregateand it will push aggregated data torequest_rates.aggregate. Stick tables without the.nonaggregatesuffix will be ignored.haproxyfrom .nonaggregate to .aggregatehaproxyfrom .nonaggregate to .aggregate -
HAProxy Enterprise
peerlines must use the same name you set on theserverline in the HAProxy Enterprise configuration (e.g.enterprise1), and specify the IP address and port where that node is receiving aggregated data.
-
-
Restart the Global Profiling Engine service:
haproxysudo systemctl restart hapee-extras-gpehaproxysudo systemctl restart hapee-extras-gpe
Verify your setup Jump to heading
Check that the Global Profiling Engine and load balancers are setup correctly by utilizing their APIs.
-
On the load balancer, call the Runtime API function
show peersto check that the Global Profiling Engine is listed and that itslast_statusisESTA(established):Below, the
show peerscommand lists connected peers:nixecho "show peers" | sudo socat stdio unix-connect:/var/run/hapee-2.8/hapee-lb.sock | head -2nixecho "show peers" | sudo socat stdio unix-connect:/var/run/hapee-2.8/hapee-lb.sock | head -2outputtext0x5651d4a03010: [07/Jul/2021:17:02:30] id=mypeers disabled=0 flags=0x2213 resync_timeout=<PAST> task_calls=920x5651d4a06540: id=gpe(remote,active) addr=192.168.50.40:10000 last_status=ESTA last_hdshk=2m17soutputtext0x5651d4a03010: [07/Jul/2021:17:02:30] id=mypeers disabled=0 flags=0x2213 resync_timeout=<PAST> task_calls=920x5651d4a06540: id=gpe(remote,active) addr=192.168.50.40:10000 last_status=ESTA last_hdshk=2m17s -
Call the Runtime API function
show tableto see data in non-aggregated and aggregated stick tables.Below, we view data in the stick table named
request_rates.aggregate:nixecho "show table mypeers/request_rates.aggregate" | sudo socat stdio unix-connect:/var/run/hapee-2.8/hapee-lb.socknixecho "show table mypeers/request_rates.aggregate" | sudo socat stdio unix-connect:/var/run/hapee-2.8/hapee-lb.sockoutputtext# table: mypeers/request_rates.aggregate, type: ip, size:102400, used:10x7fc0e401fb80: key=192.168.50.1 use=0 exp=28056 http_req_rate(10000)=5outputtext# table: mypeers/request_rates.aggregate, type: ip, size:102400, used:10x7fc0e401fb80: key=192.168.50.1 use=0 exp=28056 http_req_rate(10000)=5 -
On the Global Profiling Engine server, call the
show aggrsfunction to see load balancers that are registered as peers. Astateof0x7means a successful connection. If you see a state of0xffffffff, that means that a connection was not successful. Often, this is caused by the peer names not matching between the Global Profiling Engine’s configuration and the HAProxy Enterprise configuration.Below, the
show aggrscommand shows that the peer namedenterprise1has connected:nixecho "show aggrs" | sudo socat stdio /var/run/hapee-extras/gpe-api.socknixecho "show aggrs" | sudo socat stdio /var/run/hapee-extras/gpe-api.sockoutputtextaggregations datapeer 'enterprise1'(0) sync_ok: 1 accept: 1(last: 6080) connect: 1(last: 16086) state: 0x7 sync_state: 0x3sync_req_cnt: 0 sync_fin_cnt: 0 sync_cfm_cnt: 0outputtextaggregations datapeer 'enterprise1'(0) sync_ok: 1 accept: 1(last: 6080) connect: 1(last: 16086) state: 0x7 sync_state: 0x3sync_req_cnt: 0 sync_fin_cnt: 0 sync_cfm_cnt: 0
Optional: Bind outgoing connections to an interface Jump to heading
If the server where you are running the Global Profiling Engine has multiple network interfaces, you can configure the engine to bind to a specific one for outgoing data sent to HAProxy Enterprise servers.
To bind outgoing connections to a specific address, use the source directive in the global section.
IPv4 examples
hapee-gpe-stktagg.cfghaproxy
hapee-gpe-stktagg.cfghaproxy
The port is optional. It defaults to 0 for random ports.
hapee-gpe-stktagg.cfghaproxy
hapee-gpe-stktagg.cfghaproxy
IPv6 examples
hapee-gpe-stktagg.cfghaproxy
hapee-gpe-stktagg.cfghaproxy
The port is optional. It defaults to 0 for random ports.
hapee-gpe-stktagg.cfghaproxy
hapee-gpe-stktagg.cfghaproxy
Multi-level setup Jump to heading
You can aggregate stick tables from other Global Profiling Engines, which allows you to aggregate stick tables across different data centers, for example.
We will consider the following setup:
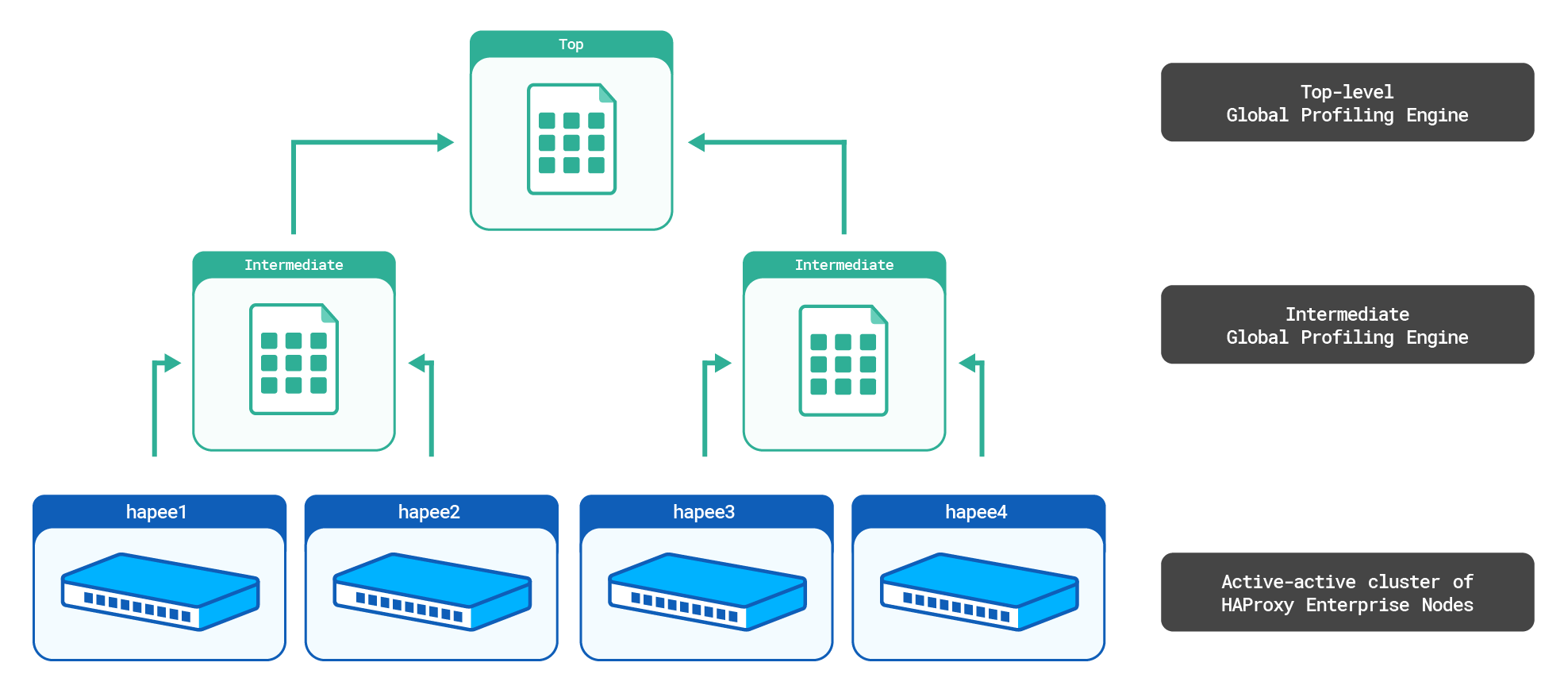
The top-level aggr3 Global Profiling Engine will sum the counters from the intermediate aggr1 and aggr2 aggregate stick tables. It will then send the top-level aggregate stick table to all HAProxy Enterprise nodes.
You can also host multiple top-level servers for high availability. In that case, intermediate servers simply push their data to both. See below for details.
Configure the top-level Global Profiling Engine Jump to heading
Follow these steps on the server you wish to be the top-level Global Profiling Engine.
-
Edit the file
/etc/hapee-extras/hapee-gpe-stktagg.cfg.hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations toplevelfrom .intermediate to .aggregatepeer top-profiling-engine 0.0.0.0:10000 localpeer intermediate-profiling-engine1 192.168.56.111:10000 downpeer intermediate-profiling-engine2 192.168.56.112:10000 downhapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations toplevelfrom .intermediate to .aggregatepeer top-profiling-engine 0.0.0.0:10000 localpeer intermediate-profiling-engine1 192.168.56.111:10000 downpeer intermediate-profiling-engine2 192.168.56.112:10000 down-
The current server has the
localkeyword set on itspeerline. -
In this example, two other Global Profiling Engine servers, intermediate-profiling-engine1 and intermediate-profiling-engine2, are listed with the
downkeyword, which means that they are one level down from the top. -
The top-level Global Profiling Engine will aggregate stick table data from the intermediate servers. Their stick tables should have the
.intermediatesuffix. -
The top-level Global Profiling Engine will push aggregated data back to the intermediate servers. The globally aggregated stick tables should have the
.aggregatesuffix.
-
Configure the intermediate Global Profiling Engines Jump to heading
Follow these steps on the servers you wish to be the intermediate-level Global Profiling Engines.
-
Edit the file
/etc/hapee-extras/hapee-gpe-stktagg.cfg.intermediate-profiling-engine1
hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations myaggrfrom any to .intermediateforward .aggregatepeer intermediate-profiling-engine1 0.0.0.0:10000 localpeer top-profiling-engine 192.168.56.113:10000 uppeer enterprise1 192.168.50.41:10000peer enterprise2 192.168.50.42:10000hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations myaggrfrom any to .intermediateforward .aggregatepeer intermediate-profiling-engine1 0.0.0.0:10000 localpeer top-profiling-engine 192.168.56.113:10000 uppeer enterprise1 192.168.50.41:10000peer enterprise2 192.168.50.42:10000intermediate-profiling-engine2
hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations myaggrfrom any to .intermediateforward .aggregatepeer intermediate-profiling-engine2 0.0.0.0:10000 localpeer top-profiling-engine 192.168.56.113:10000 uppeer enterprise3 192.168.50.51:10000peer enterprise4 192.168.50.52:10000hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations myaggrfrom any to .intermediateforward .aggregatepeer intermediate-profiling-engine2 0.0.0.0:10000 localpeer top-profiling-engine 192.168.56.113:10000 uppeer enterprise3 192.168.50.51:10000peer enterprise4 192.168.50.52:10000-
The current server has the
localkeyword set on itspeerline. -
The upper-level Global Profiling Engine peer is denoted by the
upkeyword. -
Each intermediate Global Profiling Engine is aware of only the HAProxy Enterprise nodes it manages and of the top-level Global Profiling Engine.
-
The intermediate-level Global Profiling Engines will aggregate stick table data from the HAProxy Enterprise servers.
-
The
forwardline relays the top-level server’s.aggregatestick tables to the HAProxy Enterprise servers. -
The intermediate-level Global Profiling Engines will push aggregated data back to the HAProxy Enterprise servers. The aggregated stick tables should have the
.aggregatesuffix.
-
Configure for high availability Jump to heading
To create a highly available setup, you can have multiple top-level servers. Add the group parameter to them so that the intermediate servers recognize that there are two top-level servers.
intermediate-profiling-engine1
hapee-gpe-stktagg.cfghaproxy
hapee-gpe-stktagg.cfghaproxy
Historical aggregation Jump to heading
In addition to aggregating stick table data from multiple HAProxy Enterprise nodes in real time and pushing that data back to each node, the profiling engine also stores historical data. For example, you can configure it to tell you what the average HTTP request rate was at the same time of day yesterday. Or, you can check what the average rate was at this same time a week ago, and adjust rate limiting to match.
Historical data allows you to perform dynamic decisions in your load balancer based on data from the past, such as to set rate limits that change depending on the hour.
Configure the Global Profiling Engine Jump to heading
Follow these steps to configure historical aggregation of stick table data.
-
On the Global Profiling Engine server, as shown for real-time aggregation, configure the list of peers in the
/etc/hapee-extras/hapee-gpe-stktagg.cfgfile.hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations datafrom any to .aggregatepeer profiling-engine 0.0.0.0:10000 localpeer enterprise1 192.168.50.41:10000# list more 'peer' lines for other load balancers in the cluster# e.g. peer enterprise2 192.168.50.42:10000hapee-gpe-stktagg.cfghaproxyglobalstats socket /var/run/hapee-extras/gpe-api.sockaggregations datafrom any to .aggregatepeer profiling-engine 0.0.0.0:10000 localpeer enterprise1 192.168.50.41:10000# list more 'peer' lines for other load balancers in the cluster# e.g. peer enterprise2 192.168.50.42:10000 -
Edit the file
/etc/hapee-extras/hapee-gpe.jsonto configure data retention policies for storing historical data.Data is stored in buckets of time. For example, you might keep 24 1-hour buckets, as shown below, which would allow you to compare a client’s current request rate to the average request rate during the same hour yesterday, for example.
hapee-gpe.jsonjson{"worker_thread_count": 4,"inter_worker_queue_size": 1024,"collector_queue_size": 64,"httpd_port": 9888,"datadir": "/var/cache/hapee-extras/hct_datadir","default_stick_table_handling": 1,"ignore_tables": [],"detail_tables": [],"aggregate_tables": [],"stat_retentions": [{// 24 1-hour buckets"duration": 3600,"retention": 24}]}hapee-gpe.jsonjson{"worker_thread_count": 4,"inter_worker_queue_size": 1024,"collector_queue_size": 64,"httpd_port": 9888,"datadir": "/var/cache/hapee-extras/hct_datadir","default_stick_table_handling": 1,"ignore_tables": [],"detail_tables": [],"aggregate_tables": [],"stat_retentions": [{// 24 1-hour buckets"duration": 3600,"retention": 24}]}In this example:
-
The
httpd_portfield sets the port on which to publish historical data, which HAProxy Enterprise servers poll for updates. Here, it hosts the data at port 9888. -
The
aggregate_tables,detail_tables, andignore_tablesfields are all empty since we setdefault_stick_table_handlingto1which will aggregate all tables. -
The
stat_retentionssection lists data retention policies. Each policy sets adurationin seconds, which is the size of the data bucket, and aretention, which is the number of buckets to keep. A bucket stores counters from your stick tables. For example, if your stick table tracks the HTTP request rate over 10 seconds, a 1-hour bucket might store many thousands of these 10-second request rate data points.
For each bucket, the server calculates statistics and serves them on the configured port.
-
-
Restart the Global Profiling Engine:
nixsudo systemctl restart hapee-extras-gpenixsudo systemctl restart hapee-extras-gpe
Configure HAProxy Enterprise Jump to heading
Example: Use the Global Profiling Engine to enforce rate limits Jump to heading
One use case for historical aggregation is to compare a client’s current request rates against the request rates over time and to then make rate-limiting decisions based on the current rate.
Configure each HAProxy Enterprise server to download and use the historical data.
-
Create an empty file at
/etc/hapee-2.8/historical.map.Although an in-memory representation of this file will hold historical values received from the profiling engine, the file must exist on the filesystem when HAProxy Enterprise starts.
HAProxy Enterprise updates a representation of this file in memory only. You will not see the contents of the file itself updated and it will remain empty, but you can see the in-memory values by calling the Runtime API
show mapmethod. -
Install the Update module, which polls the profiling engine for new data to load into the map file.
nixsudo apt-get install hapee-2.8r1-lb-updatenixsudo apt-get install hapee-2.8r1-lb-updatenixsudo yum install hapee-2.8r1-lb-updatenixsudo yum install hapee-2.8r1-lb-updatenixsudo zypper install hapee-2.8r1-lb-updatenixsudo zypper install hapee-2.8r1-lb-updatenixsudo pkg install hapee-2.8r1-lb-updatenixsudo pkg install hapee-2.8r1-lb-update -
Edit the file
/etc/hapee-2.8/hapee-lb.cfg.In the
globalsection of the file, add amodule-loaddirective to load the Update module:hapee-lb.cfghaproxyglobalmodule-load hapee-lb-update.sohapee-lb.cfghaproxyglobalmodule-load hapee-lb-update.so -
Configure the Update module to poll the profiling engine’s
/aggsendpoint for data by adding adynamic-updatesection that contains anupdatedirective.The
urlparameter should use the profiling engine’s IP address.hapee-lb.cfghaproxydynamic-updateupdate id /etc/hapee-2.8/historical.map map url http://192.168.50.40:9888/aggs delay 3600s loghapee-lb.cfghaproxydynamic-updateupdate id /etc/hapee-2.8/historical.map map url http://192.168.50.40:9888/aggs delay 3600s logIn this example:
- The
dynamic-updatesection configures HAProxy Enterprise to poll the profiling engine for historical data updates. - The
updateline’sidparameter sets the local file to update (remember, this file will not be updated on disk, only in HAProxy Enterprise’s runtime memory). - The
mapparameter switches the Update module into map file mode. - The
urlparameter specifies the IP and port of the profiling engine. It specifies the/aggsURL path. - The
delayparameter sets the polling interval to 3600 seconds. Since our smalleststat_retentionsduration is 3600 seconds, we can poll GPE hourly. - The
logparameter enables logging to the HAProxy Enterprise access log.
- The
-
As you would for real-time aggregation, add a
peerssection that lists the local node and the profiling engine onserverlines.Here you will also define stick tables with their
.aggregateclones.hapee-lb.cfghaproxypeers mypeersbind :10000server enterprise1server profiling-engine 192.168.50.40:10000table request_rates type ip size 100k expire 30s store http_req_rate(10s)table request_rates.aggregate type ip size 100k expire 30s store http_req_rate(10s)hapee-lb.cfghaproxypeers mypeersbind :10000server enterprise1server profiling-engine 192.168.50.40:10000table request_rates type ip size 100k expire 30s store http_req_rate(10s)table request_rates.aggregate type ip size 100k expire 30s store http_req_rate(10s)Be sure that the hostname of the HAProxy Enterprise node and the hostname of the Global Profiling Engine instance that you specify are the configured hostnames of those instances. Use the
hostnamecommand on each instance to retrieve the names.nixhostnamenixhostnameoutputtextenterprise1outputtextenterprise1 -
Use map fetch methods in your
frontendsection to read information from the local map file and make traffic routing decisions.In the example below, we deny clients that have a request rate higher than the 99th percentile of requests from the same hour (3600 seconds) yesterday (86400 seconds ago).
hapee-lb.cfghaproxyfrontend fe_mainbind :80# add records to the stick table using the client's IP address as the table keyhttp-request track-sc0 src table mypeers/request_rates# store the 99th percentile rate and the client's current rate in variableshttp-request set-var(req.rate_99percentile) str(/request_rates.http_req_rate.3600sec.86400sec_ago.99p),map(/etc/hapee-/historical.map,1000)http-request set-var(req.client_rate) sc_http_req_rate(0,mypeers/request_rates.aggregate)# set ACL expressionsacl historical_rate_greater_than_zero var(req.rate_99percentile) -m int gt 0acl client_rate_exceeds_historical_rate var(req.rate_99percentile),sub(req.client_rate) -m int lt 0# deny the request if it exceeds the historical ratehttp-request deny deny_status 429 if historical_rate_greater_than_zero client_rate_exceeds_historical_ratedefault_backend webservershapee-lb.cfghaproxyfrontend fe_mainbind :80# add records to the stick table using the client's IP address as the table keyhttp-request track-sc0 src table mypeers/request_rates# store the 99th percentile rate and the client's current rate in variableshttp-request set-var(req.rate_99percentile) str(/request_rates.http_req_rate.3600sec.86400sec_ago.99p),map(/etc/hapee-/historical.map,1000)http-request set-var(req.client_rate) sc_http_req_rate(0,mypeers/request_rates.aggregate)# set ACL expressionsacl historical_rate_greater_than_zero var(req.rate_99percentile) -m int gt 0acl client_rate_exceeds_historical_rate var(req.rate_99percentile),sub(req.client_rate) -m int lt 0# deny the request if it exceeds the historical ratehttp-request deny deny_status 429 if historical_rate_greater_than_zero client_rate_exceeds_historical_ratedefault_backend webserversIn this example:
-
The
http-request track-sc0line adds the current client to the stick table, using their source IP address as the primary key. -
The
http-request set-var(req.rate_99percentile)line reads the value of the/request_rates.http_req_rate.3600sec.86400sec_ago.99pstatistic from thehistorical.mapdata. If that statistic does not exist or has no data (which happens if there was no traffic during that hour), a value of 1000 is used instead. See the Reference guide to learn how these statistics are named. -
The
http-request set-var(req.client_rate)line retrieves the current client’s request rate from themypeers/request_rates.aggregatetable, which uses real-time aggregation to collect data from all load balancers in your cluster. -
The
http-request denyline rejects requests if the client’s current request rate (aggregated across load balancers) exceeds the 99th percentile rate for all users from the same hour yesterday. (note: If the historical rate is zero, then it defaults to a value of 1000).
-
-
Restart HAProxy Enterprise.
nixsudo systemctl restart hapee-2.8-lbnixsudo systemctl restart hapee-2.8-lb
Verify the setup. First, check that the HAProxy Enterprise admin logs show that the Update module is downloading the map file successfully. If there was an error, it will be written there. If everything worked, there will be no output (no errors).
Also, verify that data is being published by calling the /aggs URL with curl on the aggregation server. You will need to wait until the first bucket has been populated with data, though, which depends on the size of the bucket, before you will see data.
nix
nix
outputtext
outputtext
You can also call the Runtime API’s show map function to see the data stored in the map file.
Example: Use the Global Profiling Engine to calculate response time percentiles Jump to heading
You can use the Global Profiling Engine to track response time percentiles across your HAProxy Enterprise cluster. You can record these response time percentiles on some interval and then use the data for analysis.
Configure each HAProxy Enterprise server to download and use the historical data.
-
Create an empty file at
/etc/hapee-2.8/historical.map.Although an in-memory representation of this file will hold historical values received from the profiling engine, the file must exist on the filesystem when HAProxy Enterprise starts. HAProxy Enterprise updates a representation of this file in memory only. You will not see the contents of the file itself updated and it will remain empty, but you can see the in-memory values by calling the Runtime API
show mapmethod. -
Install the Update module, which polls the profiling engine for new data to load into the map file.
nixsudo apt-get install hapee-2.8r1-lb-updatenixsudo apt-get install hapee-2.8r1-lb-updatenixsudo yum install hapee-2.8r1-lb-updatenixsudo yum install hapee-2.8r1-lb-updatenixsudo zypper install hapee-2.8r1-lb-updatenixsudo zypper install hapee-2.8r1-lb-updatenixsudo pkg install hapee-2.8r1-lb-updatenixsudo pkg install hapee-2.8r1-lb-update -
Edit the file
/etc/hapee-2.8/hapee-lb.cfg.In the
globalsection of the file, add amodule-loaddirective to load the Update module:hapee-lb.cfghaproxyglobalmodule-load hapee-lb-update.sohapee-lb.cfghaproxyglobalmodule-load hapee-lb-update.so -
Configure the Update module to poll the profiling engine’s
/aggsendpoint for data by adding adynamic-updatesection that contains anupdatedirective.The
urlparameter should use the profiling engine’s IP address.hapee-lb.cfghaproxydynamic-updateupdate id /etc/hapee-2.8/historical.map map url http://192.168.50.40:9888/aggs delay 10s loghapee-lb.cfghaproxydynamic-updateupdate id /etc/hapee-2.8/historical.map map url http://192.168.50.40:9888/aggs delay 10s logIn this example:
- The
dynamic-updatesection configures HAProxy Enterprise to poll the profiling engine for historical data updates. - The
updateline’sidparameter sets the local file to update (remember, this file will not be updated on disk, only in HAProxy Enterprise’s runtime memory). - The
mapparameter switches the Update module into map file mode. - The
urlparameter specifies the IP and port of the profiling engine. It specifies the/aggsURL path. - The
delayparameter sets the polling interval to 10 seconds. - The
logparameter enables logging to the HAProxy Enterprise access log.
- The
-
As you would for real-time aggregation, add a
peerssection that lists the local node and the profiling engine onserverlines.Here you will also define stick tables with their
.aggregateclones.hapee-lb.cfghaproxypeers mypeersbind :10000server enterprise1server profiling-engine 192.168.50.40:10000table st_responsetime type string len 64 size 100k expire 1h store gpt0table st_responsetime.aggregate type string len 64 size 100k expire 1h store gpt0hapee-lb.cfghaproxypeers mypeersbind :10000server enterprise1server profiling-engine 192.168.50.40:10000table st_responsetime type string len 64 size 100k expire 1h store gpt0table st_responsetime.aggregate type string len 64 size 100k expire 1h store gpt0Be sure that the hostname of the HAProxy Enterprise node and the hostname of the Global Profiling Engine instance that you specify are the configured hostnames of those instances. Use the
hostnamecommand on each instance to retrieve the names.nixhostnamenixhostnameoutputtextenterprise1outputtextenterprise1 -
In your frontend, track the total response time of each request in the stick table mypeers/st_responsetime. We use the general purpose tag (gpt0) to store the response time value in the stick table. Each record uses a unique ID as its key, where the unique ID’s format is a combination of the client’s IP address, client’s port, frontend IP address, frontend port, a timestamp, a request counter, and the process ID.
hapee-lb.cfghaproxyfrontend fe_mainbind :80# generate a unique IDunique-id-format %{+X}o\ %ci:%cp_%fi:%fp_%Ts_%rt:%pidhttp-request set-var(txn.path) path# add records to the stick table using the unique ID as table keyhttp-request track-sc0 unique-id table mypeers/st_responsetime# prepare and perform the calculation for response timeshttp-response set-var-fmt(txn.response_time) %Trhttp-response set-var-fmt(txn.connect_time) %Tchttp-response set-var-fmt(txn.queue_time) %Twhttp-response sc-set-gpt0(0) var(txn.response_time),add(txn.queue_time),add(txn.connect_time)# store the 99th percentile rate in variableshttp-request set-var(req.response_time_99percentile) str(/st_responsetime.gpt0.3600sec.3600sec_ago.99p),map(/etc/hapee-2.8/historical.map,1000)default_backend webservershapee-lb.cfghaproxyfrontend fe_mainbind :80# generate a unique IDunique-id-format %{+X}o\ %ci:%cp_%fi:%fp_%Ts_%rt:%pidhttp-request set-var(txn.path) path# add records to the stick table using the unique ID as table keyhttp-request track-sc0 unique-id table mypeers/st_responsetime# prepare and perform the calculation for response timeshttp-response set-var-fmt(txn.response_time) %Trhttp-response set-var-fmt(txn.connect_time) %Tchttp-response set-var-fmt(txn.queue_time) %Twhttp-response sc-set-gpt0(0) var(txn.response_time),add(txn.queue_time),add(txn.connect_time)# store the 99th percentile rate in variableshttp-request set-var(req.response_time_99percentile) str(/st_responsetime.gpt0.3600sec.3600sec_ago.99p),map(/etc/hapee-2.8/historical.map,1000)default_backend webservers -
Restart HAProxy Enterprise.
nixsudo systemctl restart hapee-2.8-lbnixsudo systemctl restart hapee-2.8-lb
Verify the setup. First, check that the HAProxy Enterprise admin logs show that the Update module is downloading the map file successfully. If there was an error, it will be written there. If everything worked, there will be no output (no errors).
Also, verify that data is being published by calling the /aggs URL with curl on the aggregation server. You will need to wait until the first bucket has been populated with data, though, which depends on the size of the bucket, before you will see data.
nix
nix
outputtext
outputtext
You can also call the Runtime API’s show map function to see the data stored in the map file.
Global Profiling Engine configuration file reference Jump to heading
The following fields can be set in the /etc/hapee-extras/hapee-gpe.json file:
| Field | Description |
|---|---|
| worker_thread_count | The number of worker threads to start. Default: 2. |
| inter_worker_queue_size | The size of the message queue that handles communication between workers. It must be greater than 2 and a power of 2. Default: 1024. |
| collector_queue_size | The size of the message queue between workers and the collector. It must be greater than 2 and a power of 2. Default: 64. |
| httpd_port | The TCP port on which to publish historical statistics data. Default: 9888. |
| datadir | The directory in which to store historical data files. |
| default_stick_table_handling | Indicates how the server should process stick tables that are not listed in the ignore_tables, detail_tables, or aggregate_tables arrays. Values: 0 = ignore, 1 = aggregate, 2 = detailed processing (Experimental). |
| aggregate_tables | An array of stick table names that should be processed. One set of aggregates will be created for each stick table as a whole. |
| ignore_tables | An array of stick table names that should be skipped during processing. |
| detail_tables (Experimental) | An array of stick table names that should be processed. One set of aggregates will be created for every value in the stick table. |
| stat_retentions | An array of data retention policies. Each policy should have: duration: an integer value in seconds indicating the size of the bucket (i.e. time period) to aggregate data for. retention: the number of buckets to keep. |
Global Profiling Engine statistics reference Jump to heading
Calling the /aggs endpoint on port 9888 returns a list of available statistics. For example, if you set the following retention policy in the stat_retentions field:
json
json
The /aggs endpoint would return data for each bucket. Each bucket contains one hour of data (3600-seconds), representing one of the hours during the last 24 hours. For example, the following statistics are recorded for the hour that happened one hour ago:
text
text
Each line is a key and value. The key has this format:
/name-of-stick-table . name-of-counter . bucket-duration . time since bucket occurred . statistic
For example:
text
text
Some lines have a negative number in them:
text
text
This indicates a sliding time window that has a begin and end time that changes at a regular inteveral (i.e. an hour ago from now, or more realistically, at the next time the smallest bucket is calculated). In contrast, the following metric would be updated only at the top of every hour:
text
text
The table below describes each statistic:
| Field | Description |
|---|---|
| cnt | The count of data points of the counter (e.g. HTTP rate limit) recorded in the bucket. |
| sum | The sum of all data point values in the bucket. |
| avg | An average of all data points in the bucket that preserves the time period of the stick table counter, which makes it easy to work with when comparing it to current request rates in HAProxy Enterprise; the sum of all data points (e.g. 3547) is multiplied by the stick table counter period (e.g. 10 for http_req_rate(10s)), then divided by the duration of the bucket (e.g. 3600). |
| persec_avg | An average of all data points in the bucket, converted to a 1-second average (discards the period of the stick table counter). |
| burst_avg | A traditional, mathematical average; the sum of all data points is divided by the count. |
| min | The minimum data point value in the bucket. |
| max | The maximum data point value in the bucket. |
| 50p | The 50th percentile. |
| 75p | The 75th percentile. |
| 90p | The 90th percentile. |
| 95p | The 95th percentile. |
| 99p | The 99th percentile. |
| 99.9p | The 99.9th percentile. |
Troubleshooting: peer connections Jump to heading
If calling the /aggs URL with curl on the aggregation server does not produce any data even after adequate time has passed for the first bucket to populate, it may be the case that the Global Profiling Engine does not have connection to its configured HAProxy Enterprise peers.
To verify peer connections:
-
Use the
show peersRuntime API command on the HAProxy Enterprise server:nixecho "show peers" | sudo socat stdio unix-connect:/var/run/hapee-2.8/hapee-lb.socknixecho "show peers" | sudo socat stdio unix-connect:/var/run/hapee-2.8/hapee-lb.sockoutputtext0xaaaad88dbc50: [06/Sep/2023:10:07:50] id=mypeers disabled=0 flags=0x6213 resync_timeout=<PAST> task_calls=1666880xaaaad88e2750: id=profiling-engine(remote,active) addr=192.168.64.50:10000 last_status=ESTA last_hdshk=0sreconnect=4s heartbeat=2s confirm=0 tx_hbt=10896 rx_hbt=0 no_hbt=10882 new_conn=10894 proto_err=0 coll=0flags=0x0 appctx:0xaaaad8d064b0 st0=7 st1=0 task_calls=4 state=ESTshared tables:0xaaaad88fdd40 local_id=2 remote_id=2049 flags=0x0 remote_data=0x2last_acked=0 last_pushed=24 last_get=0 teaching_origin=24 update=24table:0xaaaad88e3860 id=mypeers/st_responsetime update=24 localupdate=24 commitupdate=24 refcnt=1Dictionary cache not dumped (use "show peers dict")0xaaaad88fdaf0 local_id=1 remote_id=2050 flags=0x0 remote_data=0x2last_acked=0 last_pushed=0 last_get=0 teaching_origin=0 update=0table:0xaaaad88e3bc0 id=mypeers/st_responsetime.aggregate update=17 localupdate=0 commitupdate=0 refcnt=1Dictionary cache not dumped (use "show peers dict")0xaaaad88e16d0: id=hapee(local,inactive) addr=0.0.0.0:10000 last_status=NONE last_hdshk=<NEVER>reconnect=<NEVER> heartbeat=<NEVER> confirm=0 tx_hbt=0 rx_hbt=0 no_hbt=0 new_conn=0 proto_err=0 coll=0flags=0x0shared tables:0xaaaad88fde10 local_id=2 remote_id=0 flags=0x0 remote_data=0x0last_acked=0 last_pushed=0 last_get=0 teaching_origin=0 update=0table:0xaaaad88e3860 id=mypeers/st_responsetime update=24 localupdate=24 commitupdate=24 refcnt=1Dictionary cache not dumped (use "show peers dict")0xaaaad88fdbc0 local_id=1 remote_id=0 flags=0x0 remote_data=0x0last_acked=0 last_pushed=0 last_get=0 teaching_origin=0 update=0table:0xaaaad88e3bc0 id=mypeers/st_responsetime.aggregate update=17 localupdate=0 commitupdate=0 refcnt=1Dictionary cache not dumped (use "show peers dict")outputtext0xaaaad88dbc50: [06/Sep/2023:10:07:50] id=mypeers disabled=0 flags=0x6213 resync_timeout=<PAST> task_calls=1666880xaaaad88e2750: id=profiling-engine(remote,active) addr=192.168.64.50:10000 last_status=ESTA last_hdshk=0sreconnect=4s heartbeat=2s confirm=0 tx_hbt=10896 rx_hbt=0 no_hbt=10882 new_conn=10894 proto_err=0 coll=0flags=0x0 appctx:0xaaaad8d064b0 st0=7 st1=0 task_calls=4 state=ESTshared tables:0xaaaad88fdd40 local_id=2 remote_id=2049 flags=0x0 remote_data=0x2last_acked=0 last_pushed=24 last_get=0 teaching_origin=24 update=24table:0xaaaad88e3860 id=mypeers/st_responsetime update=24 localupdate=24 commitupdate=24 refcnt=1Dictionary cache not dumped (use "show peers dict")0xaaaad88fdaf0 local_id=1 remote_id=2050 flags=0x0 remote_data=0x2last_acked=0 last_pushed=0 last_get=0 teaching_origin=0 update=0table:0xaaaad88e3bc0 id=mypeers/st_responsetime.aggregate update=17 localupdate=0 commitupdate=0 refcnt=1Dictionary cache not dumped (use "show peers dict")0xaaaad88e16d0: id=hapee(local,inactive) addr=0.0.0.0:10000 last_status=NONE last_hdshk=<NEVER>reconnect=<NEVER> heartbeat=<NEVER> confirm=0 tx_hbt=0 rx_hbt=0 no_hbt=0 new_conn=0 proto_err=0 coll=0flags=0x0shared tables:0xaaaad88fde10 local_id=2 remote_id=0 flags=0x0 remote_data=0x0last_acked=0 last_pushed=0 last_get=0 teaching_origin=0 update=0table:0xaaaad88e3860 id=mypeers/st_responsetime update=24 localupdate=24 commitupdate=24 refcnt=1Dictionary cache not dumped (use "show peers dict")0xaaaad88fdbc0 local_id=1 remote_id=0 flags=0x0 remote_data=0x0last_acked=0 last_pushed=0 last_get=0 teaching_origin=0 update=0table:0xaaaad88e3bc0 id=mypeers/st_responsetime.aggregate update=17 localupdate=0 commitupdate=0 refcnt=1Dictionary cache not dumped (use "show peers dict")There should be an entry for the Global Profiling engine, as well as all connected HAProxy Enterprise peers. If no data is returned or if peers are missing, there may be an issue with the configuration.
-
If entries are missing, check both the
peerssection of/etc/hapee-2.8/hapee-lb.cfgand the peers entries in the Global Profiling Engine configuration file/etc/hapee-extras/hapee-gpe-stktagg.cfg.Be sure that the hostname of the HAProxy Enterprise node and the hostname of the Global Profiling Engine instance that you specify are the configured hostnames of those instances. Use the
hostnamecommand on each instance to retrieve the names.nixhostnamenixhostnameoutputtextenterprise1outputtextenterprise1
Do you have any suggestions on how we can improve the content of this page?